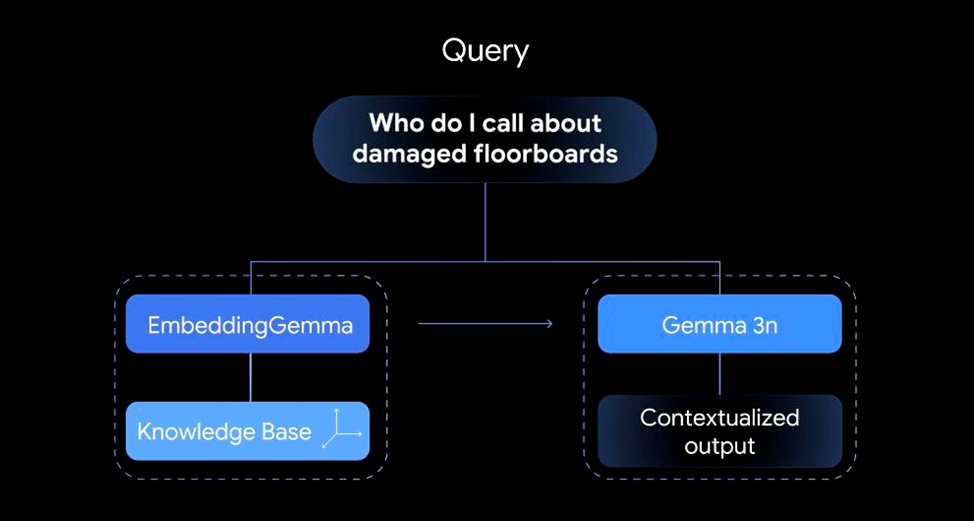
Google открыла EmbeddingGemma — компактную (≈308M параметров) мульти языковую модель для генерации встраиваний (embeddings), оптимизированную под вычисления на устройстве. По заявлениям разработчиков, после квантизации модель умещается в <200 MB памяти, работает оффлайн и по качеству близка к встраиваниям моделей размером вдвое больше (Qwen‑Embedding‑0.6B).
Ключевые факты
- Параметры: ~308M (около 100M «моделейных» + 200M «встраивательных» параметров).
- Память: после QAT/квантизации — <200 MB RAM; запуск на телефоне/ноутбуке возможен в оффлайн‑режиме.
- Поддержка языков: обучена для 100+ языков; показывает лучшие результаты среди моделей <500M на MTEB (Massive Text Embedding Benchmark).
- Динамика размерности (Matryoshka / MRL): гибкая длина встраивания — 768 (полная) и возможность усечения до 512/256/128 для экономии скорости/памяти.
- Контекст: поддержка контекста ~2K токенов (для RAG‑цепочек совместно с Gemma 3n).
- Латентность: на EdgeTPU время инференса (256 токенов) <15 ms.
- Интеграции: готова к использованию с sentence‑transformers, llama.cpp, MLX, Ollama, LiteRT, transformers.js, LMStudio, Weaviate, Cloudflare, LlamaIndex, LangChain и др.
- Демо/страница на Hugging Face: https://huggingface.co/collections/google/embeddinggemma-68b9ae3a72a82f0562a80dc4
Зачем это нужно — практические сценарии
- Оффлайн RAG (retrieval‑augmented generation) на устройстве: поиск по личным документам, письмам, заметкам без отправки данных в облако.
- Локальный семантический поиск и категоризация (классификация/кластеризация) для приложений, где важна приватность.
- Быстрые ответы в мобильных ассистентах, интерактивных чат‑ботах и агентах, где задержки критичны.
- Гибкий компромисс «качество ↔ скорость/память»: можно выбирать размер встраивания под кейс.
Почему это важно
- Переход к «edge»‑интеллекту: EmbeddingGemma снижает порог для RAG‑приложений, делая возможным семантические функции на недорогих устройствах.
- Приватность и надёжность: локальная генерация встраиваний уменьшает риск утечек и зависимость от облачных API.
- Экономия инфраструктуры: меньше запросов в облако → ниже расходы и задержки; полезно для оффлайн‑сценариев в регионах с плохим покрытием.
Ограничения и нюансы
- Хотя по MTEB модель демонстрирует отличные результаты для своего размера, большие централизованные модели всё ещё могут давать лучшие embeddings в «тонко специализированных» задачах.
- На практике итоговое качество RAG зависит не только от embeddings, но и от качества индексирования/база документов, алгоритма поиска и генератора (например, Gemma 3n).
- Встраивание в реальные продукты требует тестирования на конкретных языках/доменах и возможной донастройки/файн‑тюнинга.
Итог
EmbeddingGemma — значимый шаг в сторону распределённого, приватного и малозатратного семантического поиска: модель позволяет запускать качественные embeddings прямо на телефоне или ноутбуке, делая RAG‑функции доступными оффлайн и снижая зависимость от дорогих облачных вызовов. Это открывает новые практические сценарии для персональных ассистентов, корпоративных клиентов с требованиями конфиденциальности и мобильных приложений с жёсткими ограничениями по памяти и задержке.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru