
Обзор статьи Self-Alignment With Instruction Backtranslation.
Буквально недавно мы разбирали метод синтеза instruct-данных для дообучения LLM, основанный на Bootstrapping LongCoT. Сегодня разберём ещё один способ получить качественные обучающие пары: Self-Alignment with Instruction Backtranslation.
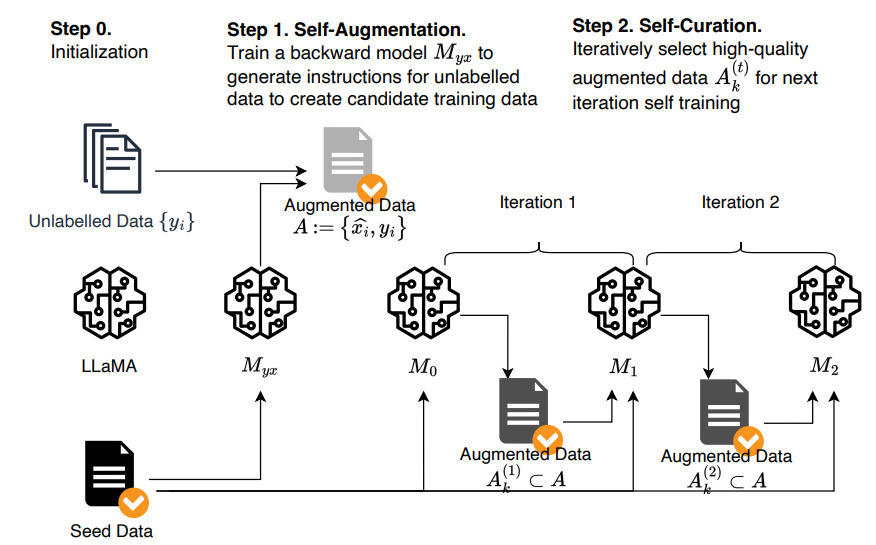
Метод состоит из трёх основных этапов:
1) Инициализация.
Берётся датасет, состоящий из 3200 пар инструкция-ответ. На данном небольшом датасете дообучается модель M0.
2) Self-Augmentation.
Берётся большой корпус текстов из интернета. Тексты делятся на самостоятельные сегменты (self-contained segments), затем сегменты дедублицируются и фильтруются по длине и качеству. Затем для каждого сегмента модель M0 формирует пару инструкция-ответ. Это позволило получить датасет A, содержащий 500к пар.
3) Self-Curation.
Модель M0 получает пару инструкция-ответ и оценивает её по 5-ти бальной шкале на основе качества соответствия и полезности. Далее формируется датасет A1, который состоит только из пар, которые получили оценку 5.
При дообучении на датасете A1 получаем модель M1, которая повторяет шаг выше: оценка пар в датасете A1 → Отбор пар, получивших 5 баллов (~40k) → Формируем датасет A2 → При дообучении на датасете A2 получаем модель M2.
В результате, исследователям удалось обучить модель Humpback (65B). При парных сравнениях (human evaluation) Humpback превосходила Falcon-Instruct, text-davinci-003, Guanaco, Claude, LIMA. И такие результаты удалось получить, начиная всего с ~3k высококачественных размеченных примеров. Также отмечено, что при увеличении исходного размеченного набора свыше ~6k рост качества становится незначительным.
На данном графике:
- w/o curation — модель на всех сгенерированных моделью M0 данных. Синтез данных без этапа Self-Curation,
- A_4 — модель, обученная на данных, которым модель M0 поставила оценку 4.
- A_5 — модель, обученная на данных, которым модель M0 поставила оценку 5.
Ещё один вариант генерации синтетики в копилку. Работаем дальше!Присоединяйтесь к нам в Telegram.