
PCA — алгоритм, уменьшающий пространство признаков так, чтобы потерять как можно меньше информации. Его часто спрашивали на собеседованиях, и, когда я впервые его изучил, то получил удовольствие от такого изящного применения линейной алгебры. Давайте же начнём разбор 🧑💻
Идея в четырёх словах:
Найти новые ортогональные оси (главные компоненты), вдоль которых дисперсия данных максимальна, и проецировать данные на первые k таких осей.
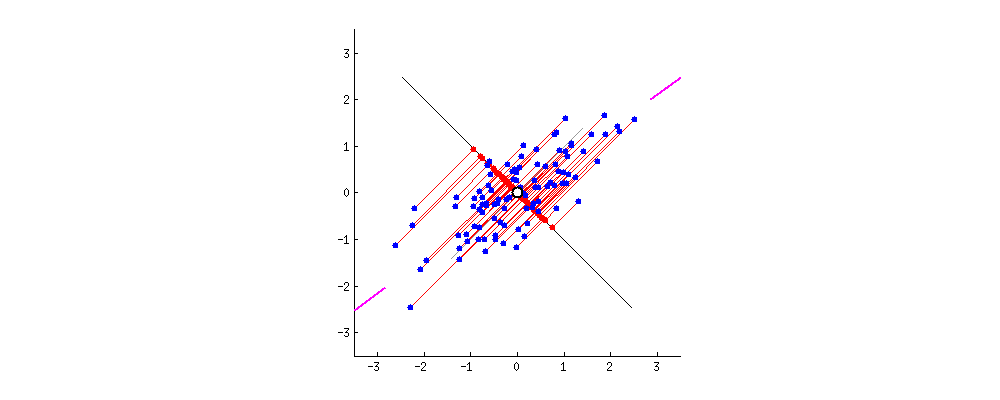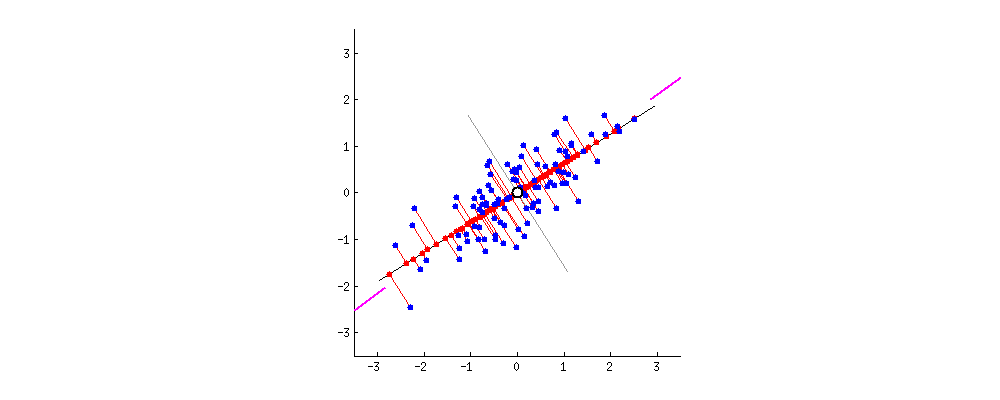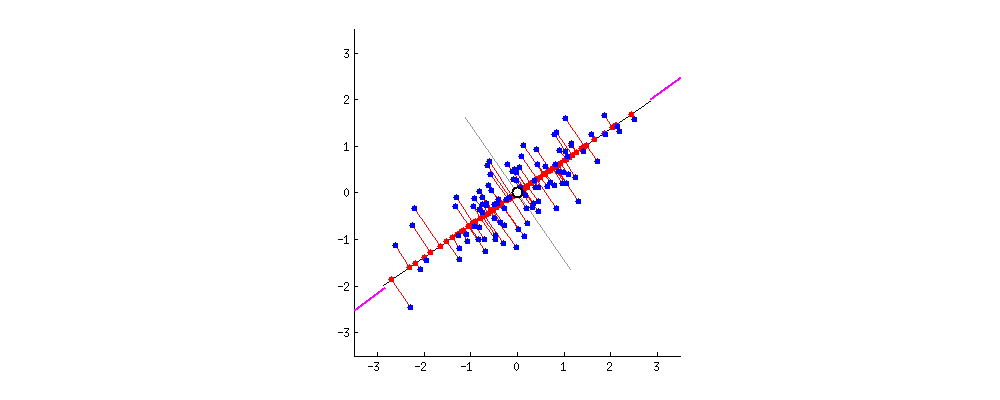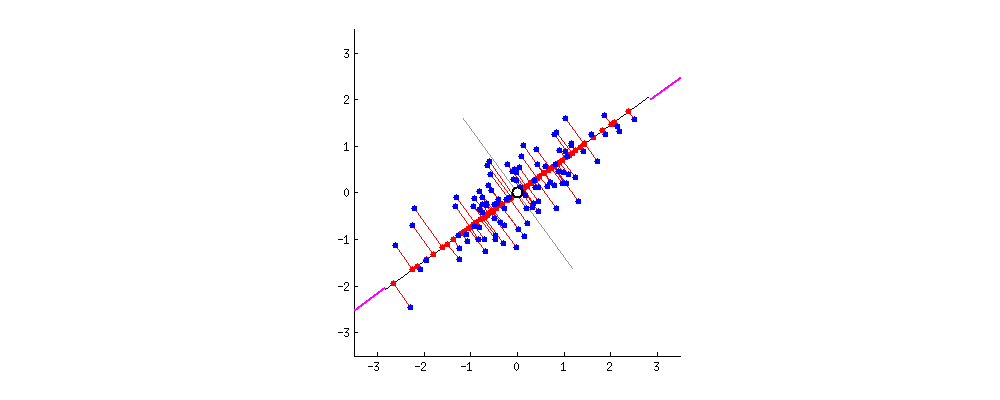
Шаги алгоритма
1) Нормирование.
Приводим признаки к сопоставимым шкалам. Иначе признаки с большими числовыми масштабами доминируют по дисперсии. Например, зарплата — в тысячах рублей, а рост — в десятках сантиметров, из-за этого и дисперсии будут несравнимы.
2) Центрирование.
Вычитаем среднее по каждому признаку. Нам важен разброс вокруг среднего, а не само значение среднего.
3) Строим ковариационную матрицу Σ.
Данная матрица показывает, как каждый из признаков меняется с другим.
- Значение >> 0 — растут вместе,
- Значение << 0 — один растёт, другой падает,
- Значение ~0 — меняются независимо.
4) Находим собственные векторы и собственные значения.
То есть решаем уравнение Σ v = λ v.
Почему именно собственные вектора, а не другие?
Мы решаем задачу max var(X, w), где:
- X — наша матрица признаков,
- w — вектор, который мы оптимизируем (норма w равна 1).
То есть нам нужно, чтобы дисперсия (var) данных X по направлению вектора w была максимальной. Если раскрыть, чему равна var(X, w), то получим w.T Σ w, при условии, что норма w равна 1. А по принципу максимизации отношения Релея мы знаем, что данное выражение максимально, когда w — собственный вектор с максимальным собственным значением.
Таким образом в уравнении Σv=λv можно сказать, что:
- v — новая ось,
- λ — сколько дисперсии приходится на данную ось.
5) Собираем матрицу W.
Данная матрица состоит из k собственных векторов с наибольшими собственными значениями.
6) Проецируем данные на новые оси.
Z = X W.
Теперь, если X была размерности n x d, а W имела размерность d x k, то Z будет иметь размерность n x k. Таким образом, мы и получим наши новые k признаков.
Как выбрать k?
Полезным показателем является "объясняемая дисперсия", которую можно рассчитать на основе собственных значений. Объясняемая дисперсия показывает, какой объём информации (дисперсии) можно отнести к каждой из главных компонент. Ниже будет график, на котором видно, что большую часть дисперсии (~73% + ~23%) можно объяснить первыми двумя главными компонентами, а остальные два можно отбросить.
Подробнее можно почитать тут и тут.
Алгоритм довольно прост, поэтому у него есть много недостатков. На практике сейчас больше пользуются алгоритмом UMAP. Очень крутая страничка, на которой можно визуально посмотреть на него находится тут.
Надеюсь, что всё было понятно. Всем удачи! 🏆
Присоединяйтесь к нам в Telegram.