
Статья является переводом. Источник: Hatica, автор Naomi Chopra
В данном тексте автор рассуждает о том, как слепое следование метрикам может мешать развитию бизнеса и эффективности инженерных команд.
Рассматриваются метрики, которые действительно помогают оценивать результативность работы, а не только кратковременный успех. Статья будет полезна руководителям, инженерам, а также всем, кто хочет глубже понять, как организована работа команд разработки и DevOps в индустрии eCommerce.
Последние несколько лет стали настоящими «американскими горками» для разработчиков. Бюджеты росли, зарплаты увеличивались, команды расширялись, а счета за облачные сервисы превратились в привычную часть расходов.
Пока экономика росла, а ресурсов было много, компании сфокусировались на скорости: выпуск новых функций, масштабирование. Но сейчас вектор начал меняться. При ограниченных бюджетах и повышенном внимании инвесторов речь идет не о том, чтобы делать больше, а о том, чтобы делать умнее — и доказывать реальную пользу своей работы.
Это заставляет задуматься о том, как мы измеряем, мониторим и отслеживаем прогресс. На первый взгляд, эти слова похожи, но они выполняют разные роли:
- Измерение показывает, где мы находимся сейчас;
- Мониторинг помогает заранее замечать тревожные сигналы на всех этапах жизненного цикла разработки, прежде чем они перерастут в проблемы;
- Отслеживание выявляет повторяющиеся закономерности, которые могут указывать на пробелы или неэффективность.
У каждой компании свой подход. Кто-то ограничивается базовым отслеживанием, а кто-то связывает метрики напрямую с бизнес-результатами. Разница в том, насколько ясно понимается, что именно означает «ценность» для команды.
Как сегодня выглядит продуктивность инженерных команд? Как измерять успех так, чтобы он отражал именно результат, а не просто количество выполненной работы? В этой статье я поделюсь наблюдениями, с какими вызовами сталкивался и какие вижу возможности — чтобы научиться измерять то, что действительно важно.
Удвоенное внимание к Developer Experience (DevEx)
Developer Experience (DevEx) — это совокупность всего, с чем сталкивается разработчик в ежедневной работе: качество инструментов, документации, процессов, культура команды.
Как бы это ни называлось — Developer Experience (опыт разработчика) или платформенная инженерия, суть одна: убрать отвлекающие факторы и дать разработчикам возможность сосредоточиться на создании ценности и реального результата.
В 2025 году этот фокус станет еще острее. Долгое время опыт разработчика оставался чем-то неосязаемым. Сейчас игнорировать его невозможно: ежедневный опыт разработчиков влияет буквально на все: от того, насколько слаженно работает команда, до скорости выпуска продукта. Но вот измерить этот опыт по-прежнему непросто.
Есть метрики, которые помогают — например, время онбординга (то, как быстро новый сотрудник может начать приносить пользу) или частота переключения контекста (сколько раз в день разработчик вынужден прерываться, чтобы заниматься чем-то другим). Но по-настоящему поддерживают команду другие вещи — менторство, улучшение процессов, качественная документация. Чаще всего это остается невидимой частью работы, хотя именно она скрепляет все процессы вместе.
Возникают важные вопросы:
- Действительно ли новые инструменты (например, Tekton, Pulumi или OpenTelemetry) упрощают работу или же, наоборот, создают новые барьеры?
- Как научиться замечать и ценить «склеивающую работу», которая незаметна в стандартных метриках, но критически важна для успеха?
Ответы не всегда очевидны. Но даже простое внимание к этим вещам помогает лучше понять, что реально поддерживает команду. И это заставляет переосмыслить само определение пользы.
Перестаньте гадать, что нужно разработчикам — начните слушать
Зачастую руководители думают, что знают все болевые точки своих команд. Но 2024-й показал нам жесткий урок: предположения часто оборачиваются провалом.
Ошибочные инвестиции в AI-инструменты обещали эффективность, но приносили хаос — не решая ключевых проблем вроде технического долга, медленной сборки проектов, слабой документации и отсутствия времени на глубокую работу. В итоге команды продолжали бороться с теми же трудностями, только теперь в окружении «блестящих» AI-решений.
Работая с самыми разными командами и культурами, я понял одно: реактивное лидерство (стиль управления, когда решения принимаются спонтанно, в ответ на симптомы проблем, а не на их реальные причины) — это ловушка. Часто руководители спешат внедрить новейшие инструменты или процессы, не задавая главный вопрос: что на самом деле нужно нашим инженерам и разработчикам?
Возьмем примеры с AI-решениями. На словах они звучат революционно, но если не устранить базовые проблемы — вроде неэффективных процессов сборки или размытых приоритетов, — то такие внедрения только усложняют жизнь и усиливают разочарование. Это классический случай: решаем не ту проблему или правильную проблему, но неправильным способом.
Настоящее лидерство не гадает — оно слушает.
В последнее время я часто спрашиваю себя:
- Реально ли наши инструменты помогают разработчикам, или они просто добавляют шум?
- И вновь: как мы можем заметить и оценить ту самую «склеивающую работу» (glue work), которая не попадает в отчетные панели, но делает возможным всё остальное?
Мелочи, которые мы упускаем, зачастую оказывают наибольшее влияние. Если мы не научимся измерять и отмечать их, то рискуем потерять из виду огромную часть картины.
Лидерство через метрики, ориентированные на результат
Платформенные команды стоят на переломном этапе: доказать свою ценность или столкнуться с сокращениями. Эпоха измерения успеха по строкам кода или простым показателям активности позади. Сегодня дело не в том, сколько работы сделано, а в том, насколько эта работа действительно двигает бизнес вперед.
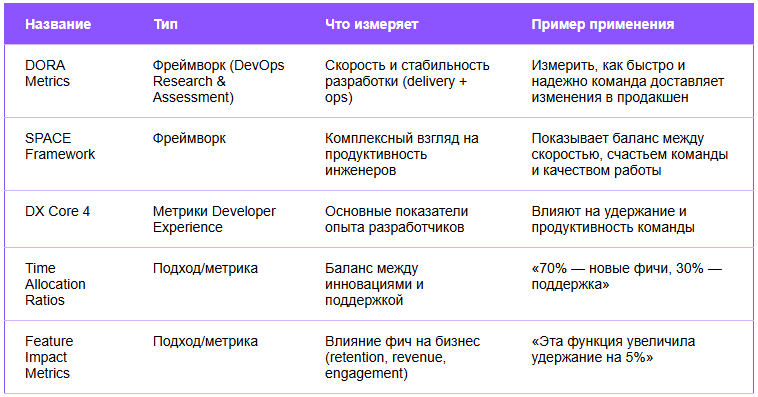
Ведущие компании всё чаще используют такие фреймворки, как DORA, SPACE и DX Core 4, чтобы связать инженерные усилия с бизнес-результатами. Но вот в чем вызов: эффективность ≠ результативность. Метрики вроде частоты деплоя или времени от идеи до релиза показывают скорость, но не говорят, правильные ли вещи мы выпускаем.
Пример: команда выкатывает новые фичи каждую неделю. Звучит впечатляюще, верно? Но если эти функции не увеличивают вовлеченность пользователей и не влияют на выручку, то что мы на самом деле достигли? Проблема не в метриках, а в том, как мы их интерпретируем.
В 2025 году происходит важный сдвиг: фокус смещается к метрикам, ориентированным на результат — тем, что напрямую связывают работу инженеров с бизнес-целями. Например:
- Соотношение времени (Time Allocation Ratios): отслеживание баланса между инновациями и поддержкой может многое показать. Но ключевое — как мы определяем «поддержку». Рефакторинг кода — это инвестиция в будущую скорость или просто отложенная рутинная работа?
- Метрики влияния фич (Feature Impact Metrics): вместо того чтобы считать количество выпущенных функций, связываем работу инженеров с удержанием пользователей, их активностью или ростом дохода.
Эти изменения нелегки. Они заставляют руководство задавать сложные вопросы и идти на неприятные компромиссы. Но именно это неудобство — сигнал: вы задаете действительно важные вопросы.
Руководители, которые не убегают от этих сложностей, переопределят, как ценится инженерный труд. Доказательство ценности — это не только цифры, это умение показать, как инженерия напрямую двигает бизнес вперед. Будущее принадлежит тем командам, которые смогут сделать эту связь максимально прозрачной.
Как задавать правильные вопросы
Я понял, что самые ценные инсайты часто приходят не от сложных вопросов, а от тех, которые бьют прямо в суть. Вместо того чтобы спрашивать: «Что мы измеряем?», я начал задавать другой вопрос: «Какие решения эта метрика поможет нам принять?». Незаметный на первый взгляд сдвиг, но он полностью изменил моё отношение к метрикам и их назначению.
Примеры таких вопросов:
- Мы создаем фичи, которые реально важны для пользователей, или просто вычеркиваем задачи из бэклога?
- У разработчиков есть ясность и нужные инструменты для работы, или они тонут в лишней сложности?
- Мы действительно держим баланс между инновациями и поддержкой систем, которые обеспечивают бесперебойную работу?
Один из подходов, который оказал на меня сильное влияние, — просто попросить разработчиков оценить собственную продуктивность, а затем смотреть, как эти оценки меняются со временем.
В комбинации с системными метриками такие самооценки дают гораздо более полную картину: что реально работает, а что нет. Дело уже не только в цифрах на дашборде — важны человеческие истории за ними. Это помогает понять, где мы проседаем, что создает проблемы и где у нас есть возможности помочь командам работать лучше.
Как основатель компании я верю, что именно в этом и заключается лидерство: задавать вопросы, которые другие упускают, находить связь между людьми и результатами и принимать решения, ведущие к реальным изменениям в будущем — а не просто к «галочкам» в отчетах. Так мы переходим от простого измерения работы к усилению её воздействия.
Метрики, которые помогают, а не упрощают
Onboarding Time (DX Core 4)
- Что измеряет: время, за которое новый разработчик начинает приносить пользу
- Назначение: оценка скорости адаптации новичков
- Пример: «Джуниор начинает коммитить через 1 неделю»
Context-switching frequency (DX Core 4)
- Что измеряет: частота прерываний и переключений задач
- Назначение: понимание, сколько времени тратится на отвлечения
- Пример: «Сотрудник прерывается 10 раз в день на встречи и запросы»
Flow State / Focus Time (DX Core 4)
- Что измеряет: время работы без отвлечений
- Назначение: измеряет возможность сосредоточиться
- Пример: «Среднее время фокусировки — 2 часа»
Developer Satisfaction (DX Core 4 / SPACE)
- Что измеряет: удовлетворенность инструментами и процессами
- Назначение: понимание уровня мотивации и комфорта команды
- Пример: регулярные опросы команды
Feature Impact Metrics
- Что измеряет: влияние фич на бизнес (удержание, вовлеченность, доход)
- Назначение: связь инженерной работы с результатом
- Пример: «Фича увеличила удержание пользователей на 5%»
Time Allocation Ratios
- Что измеряет: баланс между инновациями и поддержкой
- Назначение: понимание, сколько времени идёт на новые фичи и поддержку системы
- Пример: «70% — новые функции, 30% — поддержка и рефакторинг»
Self-reported productivity
- Что измеряет: самооценка разработчиков
- Назначение: сравнение с системными метриками, выявление проблем и узких мест
- Пример: «Команда оценила свою продуктивность как 7/10, метрики показывают высокий уровень»
Deployment Frequency (DORA)
- Что измеряет: частота деплоя
- Назначение: оценка скорости поставки изменений
- Пример: «Деплой каждую неделю»
Lead Time for Changes (DORA)
- Что измеряет: время от коммита до релиза
- Назначение: скорость доставки конкретных изменений
- Пример: «Фича попадает в продакшен через 3 дня»
Change Failure Rate (DORA)
- Что измеряет: доля неудачных релизов
- Назначение: надежность выпуска
- Пример: «20% релизов требуют отката»
Time to Restore Service (DORA)
- Что измеряет: время восстановления после инцидента
- Назначение: способность быстро возвращать систему в работу
- Пример: «Сервис восстанавливается за 1 час»
SPACE Components
- Что измеряет: Activity, Satisfaction, Performance, Communication & Collaboration, Efficiency & Flow
- Назначение: комплексная оценка работы команды и её продуктивности
- Пример: сравнение метрик активности с удовлетворенностью и результатами
Invisible / Glue Work
- Что измеряет: наставничество, документацию, улучшение процессов
- Назначение: учет незаметной, но критически важной работы
- Пример: «Поддержка процессов и наставничество оценивается в квартальном обзоре»
Как подходить к метрикам инженерии в 2025 году?
Если я чему-то научился и продолжаю делиться этим с командой и сообществом, так это тому, что метрики — это только начало. Они служат для старта обсуждений, а не быть окончательной истиной. Настоящая работа начинается, когда нужно интерпретировать цифры и действовать на их основе.
Понимание продуктивности команды — это больше, чем простая статистика. Важно учитывать как системные показатели, так и человеческий опыт: Developer Experience, «невидимую работу», влияние фич на бизнес и баланс между инновациями и поддержкой. Правильные метрики помогают выявлять узкие места, повышать эффективность и строить команды, которые действительно создают ценность.
Мы надеемся, что приведенные метрики и подходы будут полезны для вас. В нашей команде работает множество экспертов в DevOps, SRE и информационной безопасности, которые точно знают, как максимально эффективно поддержать ваш бизнес. Если вы хотите запустить проект на надежной платформе с командой, которая решит все технические вопросы, оставив вам только бизнес-задачи, свяжитесь со Scalehost и получите экспертную поддержку вашего проекта.