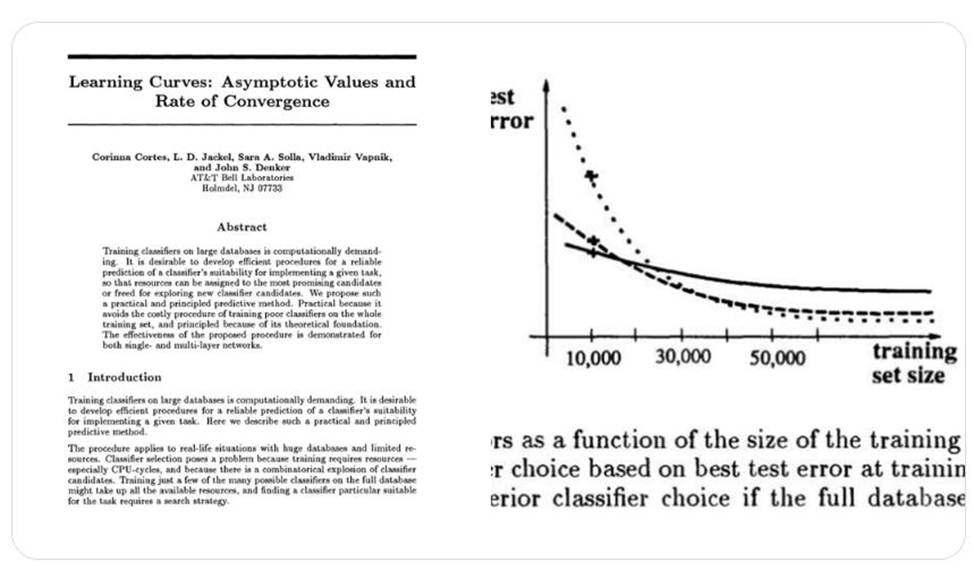
Недавние обсуждения показали, что идеи, которые сегодня называют «scaling laws» — законы роста производительности моделей при увеличении данных/параметров/вычислений — прослеживаются значительно раньше недавних работ OpenAI/Anthropic. В частности, исследование Bell Labs 1993 года (NeurIPS) по «learning curves» демонстрировало степенные зависимости ошибки от объёма обучения на разных моделях и датасетах. Это подводит историю scaling laws к десятилетиям теоретических и эмпирических наблюдений, а не к одному недавнему открытию.
Что важно помнить
- Исследование Bell Labs (1993) — «Learning Curves: Asymptotic Values and Rate of Convergence» — показало, что при увеличении числа обучающих примеров ошибка классификатора на лог‑графике следует устойчивому закону (приближённо степенному). Ссылка на статью: https://proceedings.neurips.cc/paper/1993/file/1aa48fc4880bb0c9b8a3bf979d3b917e-Paper.pdf (в тексте пользователя).
- Комментарии Greg Brockman (OpenAI) и другие недавние обсуждения подчёркивают: эти эмпирические закономерности выдержали проверку временем и масштабом — от малых классификаторов до современных больших моделей.
- История идей гораздо глубже: исследования по кривым обучения встречались в психологии, в работах 1950–60‑х (Rosenblatt и перцептрон), в работах Амари (1992) и в ранних работах Вапника (Vapnik) по статистическому обучению. Таким образом современное понятие scaling laws — результат накопления знаний между дисциплинами и поколениями исследователей.
Практическое значение для современных LLM/ML
- Scaling laws дают ориентиры для оценки отдачи от увеличения параметров, данных или вычислений: помогают принимать решения об инвестициях в модель/датасет/инфраструктуру.
- Они объясняют, почему при масштабировании моделей мы часто наблюдаем предсказуемое улучшение качества (до определённых пределов) и почему экономическая оптимизация (compute vs data vs model size) важна.
- Однако «закон» не отменяет доменно‑специфичных эффектов: архитектура, качество данных, методики обучения и прочие факторы могут менять константы и границы применимости.
Короткие выводы
- Scaling laws — не «открытие 2020 года», а многолетняя эмпирико‑теоретическая традиция, уходящая в работы Bell Labs, Vapnik, Amari и далее.
- Современные большие модели подтвердили и расширили эти тенденции, но история показывает: понимание отношений «данные ↔ модель ↔ вычисления» складывалось постепенно и междисциплинарно.
- Для практиков это важный инструмент планирования ресурсов и оценки отдачи от масштабирования, но применять его нужно вместе с учётом качества данных, архитектурных особенностей и прикладных требований.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru