Сортировка данных — это процесс перестановки элементов коллекции (списка, массива, таблицы) таким образом, чтобы элементы располагались в определённом порядке (возрастание, убывание, алфавитный порядок и т.п.). Это позволяет значительно упростить работу с данными, сделать их доступными и удобными для последующего анализа.
Например, рассмотрим простой пример:
numbers = [3, 1, 4, 1, 5]
sorted_numbers = sorted(numbers)
print(sorted_numbers) # выводит [1, 1, 3, 4, 5]
Типичные задачи, решаемые методами сортировки
Организация упорядоченных данных для эффективного поиска. Например, упорядочив телефонный справочник по фамилии, мы можем быстро находить нужную запись. Упрощение анализа и агрегации информации. Отсортируя доходы клиентов по величине, можно легко определить самых прибыльных покупателей. Оптимизация запросов к данным. Если база данных хранится в отсортированном виде, запросы выполняются быстрее благодаря специальным алгоритмам поиска (бинарный поиск).
Рассмотрим ситуацию на примере списка продуктов в магазине:
products = [
{"name": "Apple", "price": 1.5},
{"name": "Banana", "price": 0.8},
{"name": "Orange", "price": 1.2}
]
Сортировка товаров по цене (дешевле → дороже)
sorted_products = sorted(products, key=lambda x: x['price'])
print([product["name"] for product in sorted_products]) # выведет ['Banana', 'Orange', 'Apple']
Эта простая операция позволяет быстро увидеть товары от дешёвых к дорогим, что удобно как для пользователей, так и для аналитики продаж.
Алгоритмы сортировки и способы фильтрации данных с примерами.
I. Простые алгоритмы сортировки
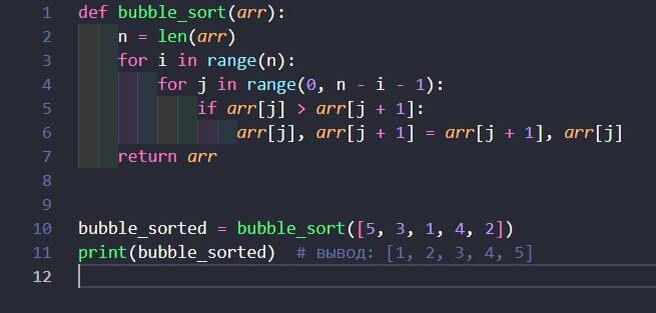
1. Bubble Sort (Метод пузырька)
Принцип работы: Последовательное сравнивание соседних элементов и обмен местами, если элемент слева больше правого. Процесс повторяется до тех пор, пока весь массив не станет упорядоченным.
Пример: Рассмотрим массив [5, 3, 1, 4, 2]. После первого прохода получается [3, 1, 4, 2, 5], после второго — [1, 3, 2, 4, 5], и так далее. Временная сложность: O(n2)O(n2). Использовать редко, поскольку неэффективен даже для небольших наборов данных.
2. Selection Sort (Выбор минимального элемента)
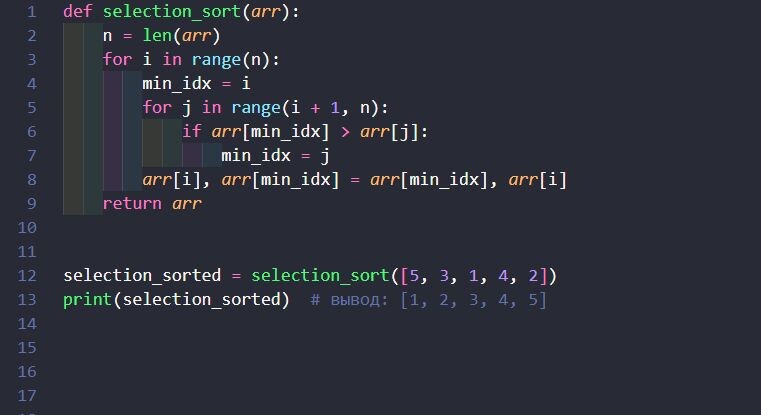
Принцип работы: Проходим по всему массиву и выбираем минимальный элемент, меняя его местами с первым элементом текущего шага. Повторяем процедуру для всех позиций массива.
Пример: Для массива [5, 3, 1, 4, 2]: первый проход даёт [1, 3, 5, 4, 2], второй — [1, 2, 5, 4, 3], и так далее. Временная сложность: O(n2)O(n2). Несмотря на простоту, тоже используется редко ввиду низкой эффективности.
3. Insertion Sort (Вставка элементов)
Принцип работы: Берём очередной элемент и перемещаем его в правильную позицию внутри уже отсортированной части массива.
Пример: Массив [5, 3, 1, 4, 2] превращается последовательно в [3, 5, 1, 4, 2], потом [1, 3, 5, 4, 2], и так далее. Временная сложность: Средний случай — O(n2)O(n2), однако при почти отсортированных данных эффективность повышается до O(n)O(n).
II. Эффективные алгоритмы сортировки
1. QuickSort (Быстрая сортировка)
Принцип работы: Выбираем опорный элемент («pivot»), делим массив на два подмножества: меньших и больших значений относительно pivot'а, рекурсивно применяем тот же подход к обеим частям.
Преимущества: Один из самых быстрых способов сортировки. Работает за среднее время O(nlogn)O(nlogn), хотя в худшем случае возможен рост до O(n2)O(n2) (редко встречается на практике). Применение: Часто используется в стандартной библиотеке многих языков программирования.
2. Merge Sort (Сортировка слиянием)
Принцип работы: Рекурсивно делим массив пополам, сортируем каждую половину отдельно, а затем объединяем их обратно в одну отсортированную коллекцию.
Преимущества: Всегда работает за O(nlogn)O(nlogn), независимо от состояния исходных данных. Результат стабильно быстрый и предсказуемый. Недостатки: Требует дополнительную память для хранения промежуточных результатов.
3. Heap Sort (Кучная сортировка)
Принцип работы: Строится двоичное дерево (куча), где каждый родительский узел больше детей. Затем извлекается максимальный элемент и снова восстанавливается куча.
Преимущества: Имеет лучшую временную сложность O(nlogn)O(nlogn) и требует меньше дополнительной памяти, чем некоторые другие методы. Реализация: Эта сортировка часто реализуется на уровне библиотеки, но её можно реализовать самостоятельно.
4. TimSort (Стандартная сортировка Python)
Принцип работы: Гибридный алгоритм, использующий адаптивную стратегию: сочетание Merge Sort и Insertion Sort. Устойчив к небольшим диапазонам, поддерживает стабильность сортировки.
Преимущества: Является самой быстрой сортировкой в стандартной библиотеке Python, работающей за O(nlogn)O(nlogn). Реализация: Автоматически используется функцией sorted() и методом .sort() в Python.
Оценка эффективности методов сортировки
1. Анализ временной сложности
- Лучший случай — ситуация, когда массив уже частично или полностью отсортирован.
- Худший случай — когда массив находится в обратном порядке или сильно несбалансирован.
2. Практическое использование и ограничения
Пузырьковая сортировка (Bubble Sort). Простота реализации, но очень низкая скорость (O(n^2)), практически не используется в реальной разработке. Применяется в образовательных проектах, демонстрационные примеры.
- Сортировка по выбору (Selection Sort). Легкость понимания и простота. Медленная работа O(n^2), плохо подходит для больших массивов. Аналогично с Bubble Sort, чаще всего учебная практика.
- Сортировка вставками (Insertion Sort). Хорошо справляется с небольшими и частично отсортированными массивами. Высокая стоимость для больших наборов данных (O(n^2)). Небольшие наборы данных, предварительная подготовка данных перед другим типом сортировки.
- Быстрая сортировка (QuickSort). Быстро работает в большинстве случаев, средний случай — O(n \log n). Может замедляться до O(n^2) при плохих входных данных (неудачный выбор опорного элемента). Широко используемый алгоритм в библиотеках, хорошо подходит для крупных наборов данных.
- Сортировка слиянием (Merge Sort). Постоянная производительность O(n \log n), идеально для распределённых вычислений. Требует дополнительного пространства для временного хранилища. Применяется когда важна стабильность и гарантированная скорость сортировки, особенно при параллельном выполнении.
- Сортировка по куче (Heap Sort). Отличная производительность O(n \log n), минимум требуемой памяти. Нет стабильности, немного сложнее реализовать. Метод сортировки удобен для организации приоритетных очередей и оптимальной работы с памятью.
- Временная сортировка (TimSort). Самый оптимальный вариант в Python, сочетает лучшие стороны других алгоритмов, обеспечивает высокую скорость и устойчивость. Немного сложный для самостоятельного изучения и реализации. Основной способ сортировки в Python, рекомендуется для большинства практических задач.
Теперь, имея представление о плюсах и минусах каждого метода, вы сможете выбирать подходящий алгоритм сортировки для конкретной задачи.