🕰️ ИИ спотыкается об обычные стрелки: бенчмарк показал, как нейросети «не видят» время
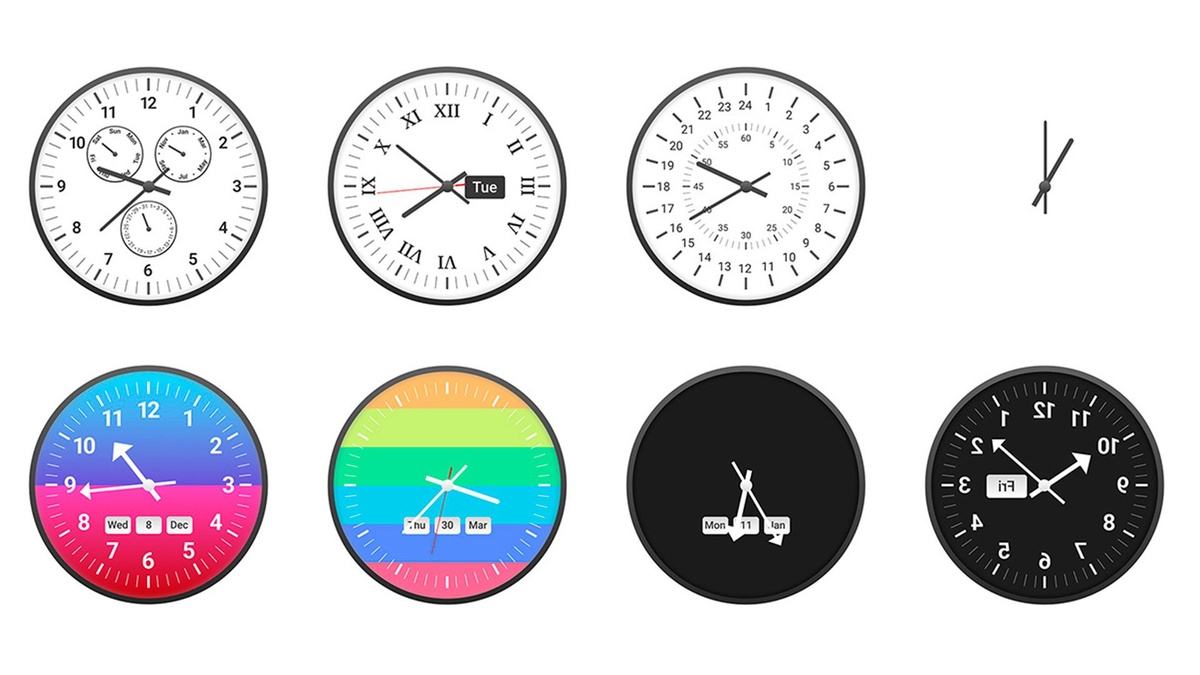
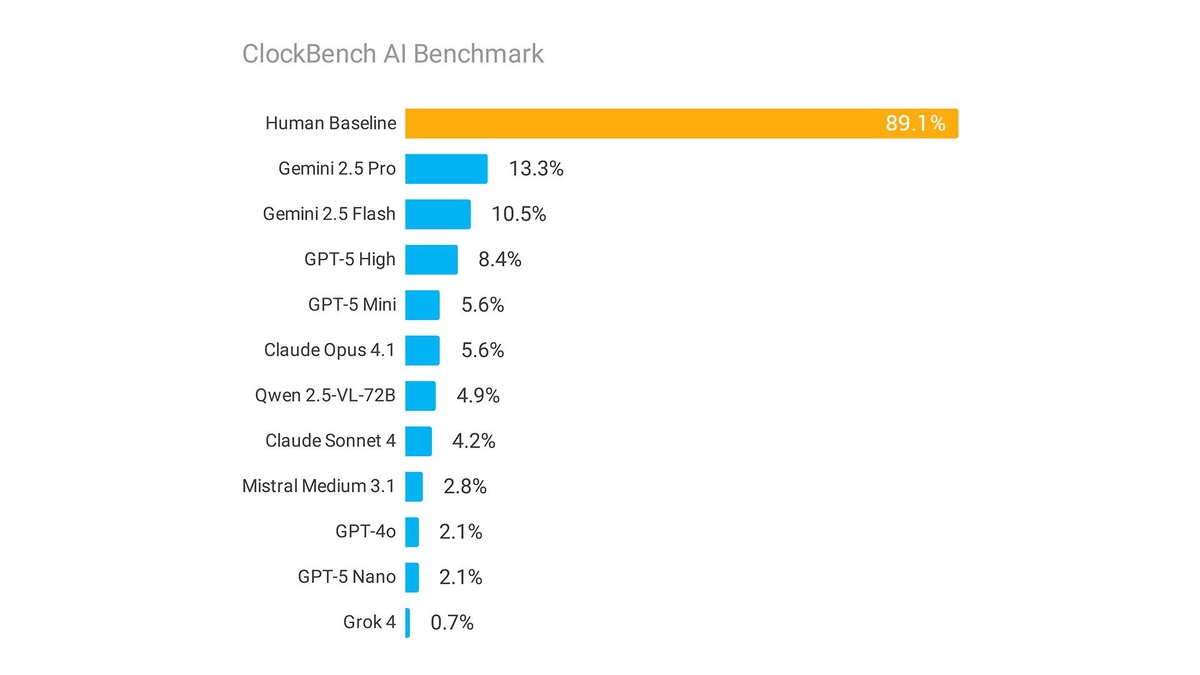
В тесте ClockBench мультимодальные модели, включая топовые, резко уступили людям: лучшая дала верный ответ лишь в ~13% случаев против ~89% у участников. Ошибки доходили до 1–3 часов, особенно тяжело давались римские циферблаты. Задания базовые: «Который час?» и «Что будет через 15 минут?» — 36 разных циферблатов, 11 моделей и контроль с участием людей.
Почему так? Моделям сложно перенести визуальные признаки в «текстовое» пространство и удержать причинно‑следственные связи между углами стрелок и шкалой.
Мой взгляд: отличный reality‑check для «AGI уже завтра». Пока ИИ путает минутную со часовой, ему рано доверять автономию там, где цена ошибки высока.
А вы часто смотрите на стрелочные? Назовёте время на римском циферблате без подсказок?
#Techtaim