Предисловие
В нашу эпоху всемирного информационного потопа не секрет, что тексты порою пишет ИИ, на известных писателей работают целые коллективы литературных рабов, все кому не лень - или наоборот лень - "плагиатят" и "копипастят" друг у друга, компилируют тексты известных писателей, и не особо известных публицистов. И потому, иногда возникает необходимость провести идентификацию авторства текстов. Представленная методика позволяет математическими методами проанализировать текст и получить результаты необходимые для составления заключения о схожести текстов большого объёма, произведений как внутри автора, так и между различными авторами, при возникновении сомнений в истинном авторстве.
Однако необходимо принять во внимание, что результаты математического анализа не являются окончательным вердиктом, а всего лишь служат поводом для размышлений специалистов.
К исследованию текстов для отработки методики, планируются произведения Михаила Булгакова и Захара Прилепина. И ради чего всё это затеяно — провести сравнительный анализ текстов произведений Михаила Шолохова. Ознакомлен с работой - Садин Бозиев "Превратности текстов произведений М.А. Шолохова и Ф.Д. Крюкова" и статьей - Н.П. Великанова, Б.В. Орехов Цифровая текстология: атрибуция текста на примере романа М.А. Шолохова «Тихий Дон» . Потому, будет очень интересно сравнить выводы.
Предложенная методика - это содержательная аналитика на основе комбинации статистических тестов и грамматического строя языка. Итоговый программный скрипт реализован на Python и настроен на сравнение литературных текстов большого объёма — от 20000 слов.
Обоснование методики
Совершенно очевидно, что никакие статистические тесты и никакой, самый совершенный математический анализ не способны оценить художественные достоинства литературного произведения. Однако, при помощи математики и статистики возможно составить "лексический портрет" автора, который уникален и неповторим, как его внешность. Я исхожу из соображения, что у каждого человека в зависимости от множества факторов, как личностных качеств, так и воздействия внешней среды, формируется пассивный словарный запас. Этот пассивный словарный запас является источником активного словаря, который используется для повседневной разговорной речи и при написании текстов. Писатель может владеть большим пассивным словарём (знать много слов), но на подсознательном уровне, неосознанно, активно использовать лишь часть из них. Таким образом, богатство языка и, следовательно, ценность литературного произведения определяется не только числом слов, но и умением сочетать их, создавать образы, играть смыслами. Отсюда, любое художественное произведение можно рассматривать как выборку слов из пассивного словарного запаса автора, где уникальность автора определяется индивидуальностью этой выборки и особенностями её отбора, который трудно подделать и который устойчив даже при смене темы или жанра .
Или, то же самое, но для любителей научной терминологии:
- Лингвист Б. Н. Головин отмечает: «…язык действует и речь образуется в соответствии со статистическими законами».
- В 1963 году Н. Д. Андреев и Л. Р. Зиндер определили и ввели в научный обиход понятие речевой вероятности. Систему речевой вероятности они определили как «совокупность относительных количественных характеристик, описывающих численные соотношения между элементами в некотором массиве текстов»; «речевая вероятность определяет статистическую структуру текстов, тогда как язык характеризуется их теоретико-множественной структурой и алгоритмами их порождения и распознавания»
Подготовительный этап
Выбор формата исходного файла
Для точности анализа желательно использовать текстовые форматы типа: .txt, .rtf, .epub, .fb2. Издательские макеты типа .pdf или .djvu не пригодны для программной обработки текста из-за наличия слов с жёстким переносом, которые могут значительно повлиять на точность результатов исследования.
Предварительная обработка текста
Удаление из начального текста всех слов, которые не относятся к содержанию произведения.
Приведение текста к нижнему регистру и удаление лишних пробелов.
Замена "ё" на "е" при необходимости.
Удаление в числах окончаний.
Дефисы из слов не удаляются.
Статистические функции
Закон больших чисел (ЗБЧ) утверждает, что при достаточно большом количестве испытаний эмпирическое среднее наблюдаемого результата приближается к своему теоретическому среднему значению.
Применительно к данному исследованию - чем больше количество текстов исследуется и чем больше количество слов в тексте, тем точнее лексический портрет писателя.
В рамках настоящего исследования считаю обоснованным применение сильной формы Закона больших чисел (Чебышёва), в котором утверждается, что среднее арифметическое результатов большого числа испытаний сходится к истинному среднему значению почти наверняка.
Центральная предельная теорема (ЦПТ) позволяет делать выводы о параметрах генеральной совокупности (например, лексическом портрете автора) на основе эмпирических характеристик выборок, представленной текстами его произведений.
Для сравнительного анализа текстов используются следующие статистические функции:
Коэффициент вариации — используется для оценки относительной меры разброса значений относительно среднего значения массива. Коэффициент вариации удобен тем, что позволяет сравнивать степень рассеяния данных разных массивов независимо от единиц измерения и масштаба.
Интерпретация значений: в статистике принято, что если значение КВ менее 10%, то такое значение указывает на слабую вариативность или низкую изменчивость данных. Принимая во внимание, что стиль автора является его уникальной особенностью, если, конечно, тексты он пишет абсолютно самостоятельно, я полагаю что степень рассеивания данных (КВ) не должна превышать порога уверенности в схожести-различии текстов. Потому, значение коэффициента вариации более 5%, принимаю статистически значимым различием и выделяю, при необходимости, для дополнительного анализа.
Статистические методы - для каждой группы числовых данных подбирался наиболее оптимальный состав статистических тестов. Перечень указывается в таблице.
Взвешенная оценка сходства - результаты множества статистических тестов сведены к Weighted Similarity (0-1).
Рассчитываемые показатели
Общий анализ
Количество слов — всего количество слов в тексте.
Количество предложений — всего количество предложений в тексте.
Средняя длина слова — усреднённый показатель количества букв в слове.
Средняя длина предложения — усреднённый показатель количества слов в предложении.
Показатели лексического разнообразия
Индекс типа-токена (Type-Token Ratio, сокращённо TTR) — это количественный показатель, широко применяемый в лингвистике и психологии для измерения лексического разнообразия текста или речи. Индекс рассчитывается путём деления числа уникальных слов ("типов") на общее количество слов ("токенов"). Чтобы преодолеть проблему длины текста средний TTR считается методом последовательного перекрывания окон (размер окна=500 слов, шаг сдвига окна=250 слов).
Процент водности — отношение количества стоп-слов на общее количество слов.
Hapax Legomena — нормированное количество уникальных слов, которые встречаются ровно один раз.
Общие слова (лексическое подобие)
Подобие по общим словам (сокращённо ПОС) — отношение суммы общих слов (слова в тексте, которые повторяются во всех исследуемых текстах) к количеству слов в тексте. Значение ПОС является интегральным и универсальным показателем, наиболее точно определяющим степень сходства-различия между текстами литературных произведений.
Как толковать: Высокий процент ЛПТ при низкой вариации указывает на высокую вероятность написания исследуемых текстов одним автором.
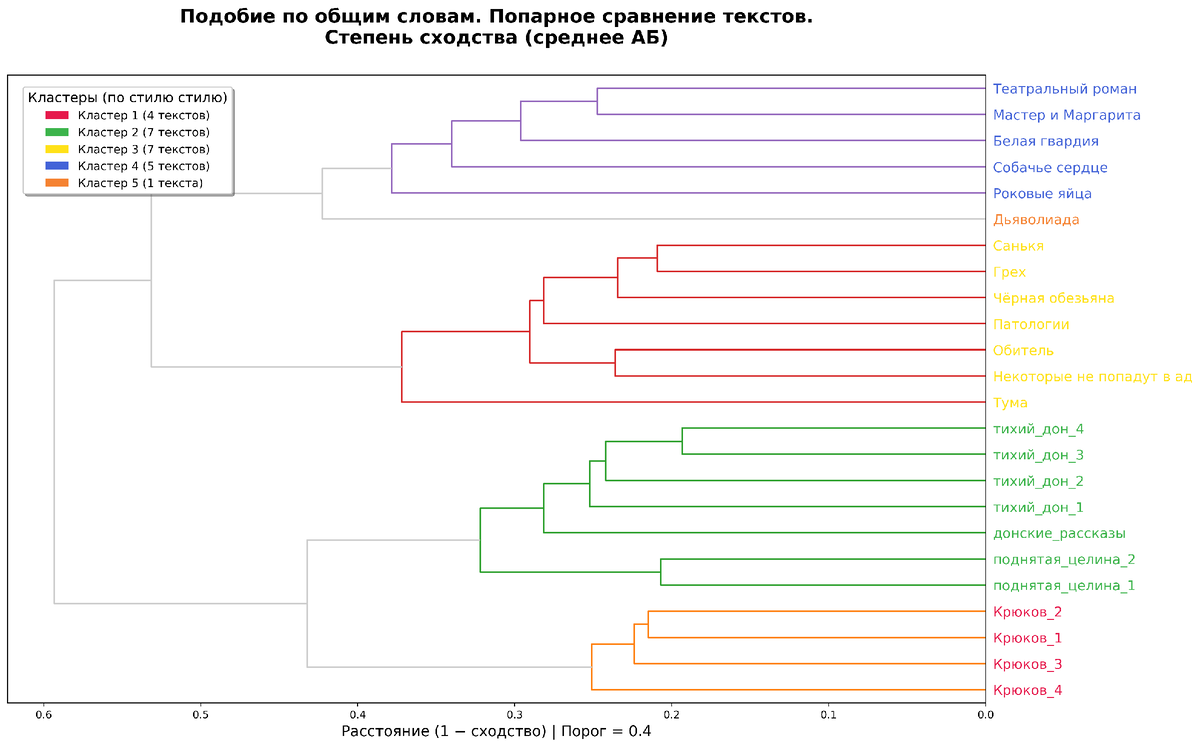
Как видно из дендрогрммы, предложенный мной метод "Сравнение текстов по общим словам (лексическое подобие)" уверенно различает авторов произведений литературной прозы и достаточно точно распределяет тексты по сходству внутри блока одного автора.
Морфологический разбор
Нормализованное количество POS-тегов (Part-of-Speech tags):
- NOUN (существительное),
- VERB (глагол),
- INFN (инфинитив),
- ADJF (прилагательное краткое),
- ADJS (прилагательное полное),
- ADV (наречие).
Распределение слов по длине
Длина слова — количество символов в слове. В таблице представлено нормализованное количество слов длиною от 1 символа до 19 символов включительно и отдельной строкой — сумма всех слов длиною от 20 и более символов.
Коэффициент вариации рассчитан для каждой длины слова, что позволяет оценить степень их изменчивости и разнообразия.
Сравнительный анализ текстов большого объёма по длине слова теряет свою значимость, поскольку, как показывает практика, средние значения стремятся к своему математическому ожиданию, что не позволяет выявить тенденции. В связи с этим решил использовать интегральный показатель — удельный вес слов различной длины, а именно: слов длиной от 1 до 3 символов, от 4 до 9 символов и 10+ символов. Такой подход позволит более эффективно выявлять и анализировать тенденции в распределении слов по длине.
Частотность букв
В таблице представлено нормализованное количество букв в анализируемом тексте. Для каждой буквы вычисляется коэффициент вариации, что позволяет оценить степень ее изменчивости относительно среднего значения.
Сортировка букв осуществляется по эталону, который был разработан на основе частотного словаря современного русского языка, составленного О. Н. Ляшевской и С. А. Шаровым (Частотный словарь современного русского языка на материалах Национального корпуса русского языка. М.: Азбуковник, 2009). Этот эталон служит ориентиром для сравнительного анализа.
Сравнительный анализ текстов большого объёма по частотности букв теряет свою значимость, поскольку средние значения стремятся к математическому ожиданию, соответствующему эталону СКРЯ. В таких условиях выявление тенденций становится затруднительным. Тем не менее корреляция и F-тест с эталоном позволяют обнаружить наиболее ярко выраженные тенденции.
Таблица частотности позволяет выявить аномалии в распределении букв по коэффициенту вариации. Исследование таких аномалий может предоставить дополнительную информацию для дальнейшего анализа и интерпретации данных.
Частотность двубуквенных сочетаний
Биграммы считаются внутри слова. Таблично представлены: Топ-20 биграмм для каждого текста, Пересечение биграмм всех текстов, где сравнивается вероятность пересечения в общем количестве биграмм для каждого текста.
Графики
Дендрограммы, радиальные графики.
Выводы
Предложенная методика сравнения текстов на основе статистических тестов и математического анализа позволяет определить степень вероятности сходства-различия между текстами, которая может быть использована, в том числе, при установлении авторства произведений.
Важно отметить, что математико-статистические методы не предназначены для оценки качественных, эстетических или содержательных характеристик художественного текста. Их функция ограничивается количественным анализом: сравнением статистических показателей, по которым можно установить степень схожести-различия текстов с заданным уровнем достоверности.
Благодарности
Выражаю особую благодарность Искусственному Интеллекту, который значительно ускорил мою работу. Я не специалист по программированию, имею только базовые понятия, и без помощи ИИ корпел бы по старинке на Jupyter Notebook.
Надо признать, что ни один, из всех популярных ИИ не смог реализовать с первого раза требуемый мне алгоритм действий в окончательно рабочем виде. Пришлось компилировать и оптимизировать код при помощи 4 различных ИИ, пока не получил желаемый результат.
Чем мне помог ИИ:
- представил примеры использования необходимых библиотек Python,
- помог составить список стоп-слов,
- исправил ошибки в программном коде,
- разъяснил современную терминологию, используемую при анализе текстов, что позволило мне выбрать наиболее оптимальные параметры для сравнения.
- ознакомил с современными методами машинной обработки текстов,
- написал итоговый программный код в рабочем виде.
Уведомление о защите авторских прав
Авторское право на представленный метод сравнения текстов возникает автоматически с момента его публикации и не требует дополнительной регистрации.
Запрещается:
- Полное или частичное копирование материалов
- Распространение без разрешения правообладателя
- Модификация и переработка контента
- Использование в коммерческих целях без договора.
Любое использование данного метода допускается только при наличии письменного согласия правообладателя и заключении соответствующего договора.