Vision-Language модели (VLM) кардинально расширяют границы автоматизации тестирования — особенно там, где плохо справляются традиционные инструменты. Canvas, SVG, динамически генерируемые элементы, сложные графические интерфейсы: все это остается «слепыми зонами» для классических фреймворков, привязанных к DOM-структурам и статическим селекторам. Но для моделей это не проблема. Они не читают HTML — они смотрят на экран, как это делает пользователь.
Мы решили проверить, насколько эффективно VLM справится с автоматизацией тестирования интерактивных карт. В нашем кейсе модель работала с Яндекс.Картами, выполняя полноценный сценарий:
- Поиск организации по названию,
- Построение маршрута между двумя точками,
- Проверку, проходит ли маршрут через указанный город,
- Валидацию корректности отображения информации на карте.
Тест-кейс для проверки работы Яндекс.Карт
На скриншоте показан интерфейс платформы BugBuster — инструмента для автоматизации UI-тестирования с использованием Vision-Language моделей. Тест описан на естественном языке без использования кода или селекторов. В шагах указано, как пользователь должен взаимодействовать с интерфейсом. Ожидаемые результаты отмечены желтыми «лампочками».
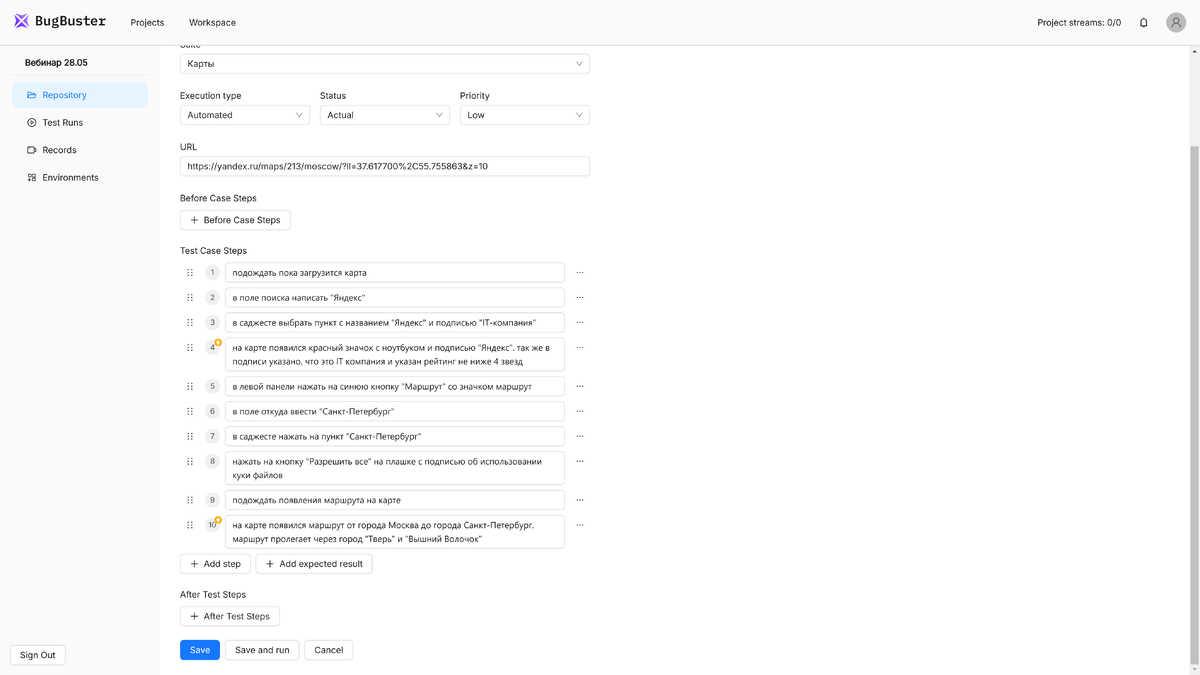
Сценарий 1: Тест пройден
Модель успешно выполнила все шаги. Она распознала поле поиска, ввела запрос, выбрала нужную организацию, построила маршрут и проверила его визуальное отображение. Платформа не просто зафиксировала успех — она предоставила детализированный отчет с пошаговым объяснением. И все это — без единой строчки кода и без доступа к внутренней структуре приложения.
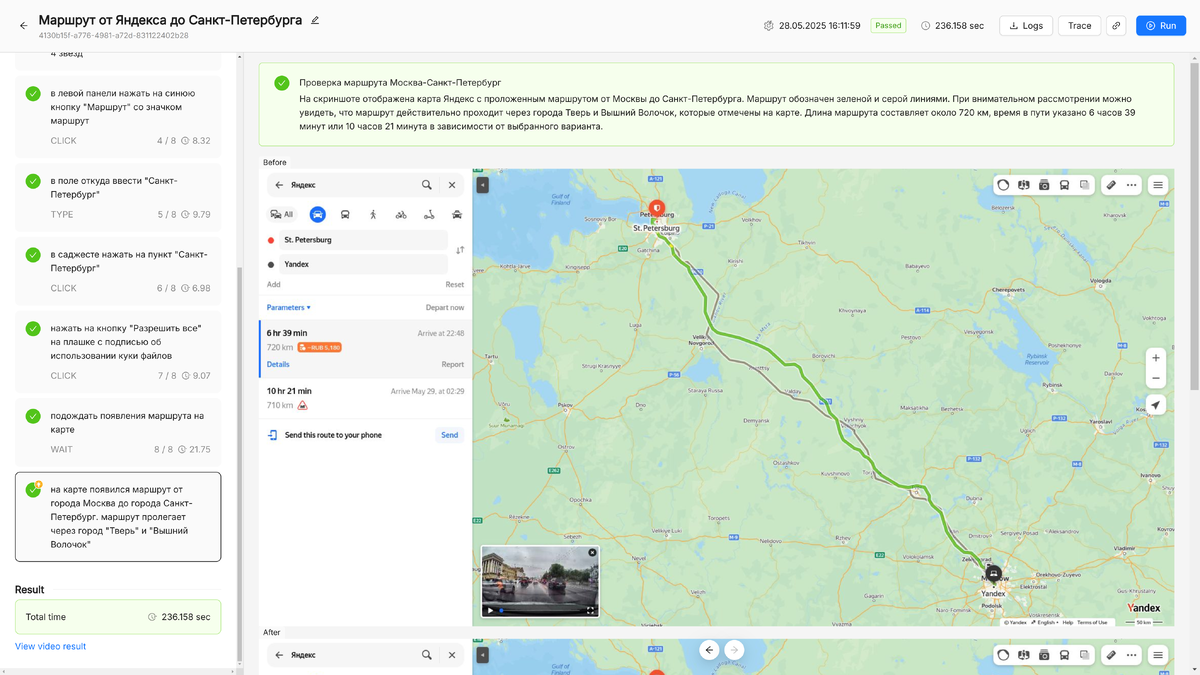
Сценарий 2: Тест не пройден
Во втором случае маршрут не проходил через указанный город. VLM проанализировала визуальное положение города относительно линии маршрута, использовала геопространственные подсказки (названия, расположение на карте) и пришла к правильному выводу. При этом система не просто зафиксировала ошибку — она визуализировала проблему на скриншоте, выделив город и маршрут, и объяснила логику проверки на естественном языке.
Начните тестировать без кода — зарегистрируйтесь на платформе BugBuster и запустите первый тест уже через 5 минут.