
На днях Tencent выкатил в опенсорс проект, который заставил меня присвистнуть. Называется AutoCodeBenchmark. Это целый конвейер, который сам, почти без участия человека, генерирует, описывает и, что самое главное, проверяет задачи по программированию. На 20 языках.
По сути, это «вечный двигатель» для создания учебного контента. Машина, которая придумывает работу для других машин (и для нас, кожаных мешков). Я покопался в их репозитории на GitHub, и теперь готов простыми словами рассказать, как устроен этот кибер-методист.
Что такое AutoCodeBenchmark?
Если не лезть в дебри, то вся система — это два больших модуля, работающих в паре:
- AutoCodeGen — это «фабрика контента». Мозг всей операции. Именно здесь с помощью большой языковой модели (LLM) из крошечного огрызка кода выращивается полноценная задача с решением и тестами.
- MultiLanguageSandbox — это «испытательный полигон». Безопасная, изолированная среда, где весь сгенерированный код безжалостно компилируется и прогоняется. Это не дает нейросети нафантазировать нерабочую дичь.
Их совместная работа — это бесконечный цикл «придумал → проверил». AutoCodeGen генерирует идею, MultiLanguageSandbox говорит «верю» или «не верю». И так до тех пор, пока на выходе не получится качественный, работающий материал.
Как работает конвейер по созданию задач?
А теперь самое интересное — как именно из ничего получается что-то. Весь процесс разбит на несколько гениальных в своей простоте шагов.
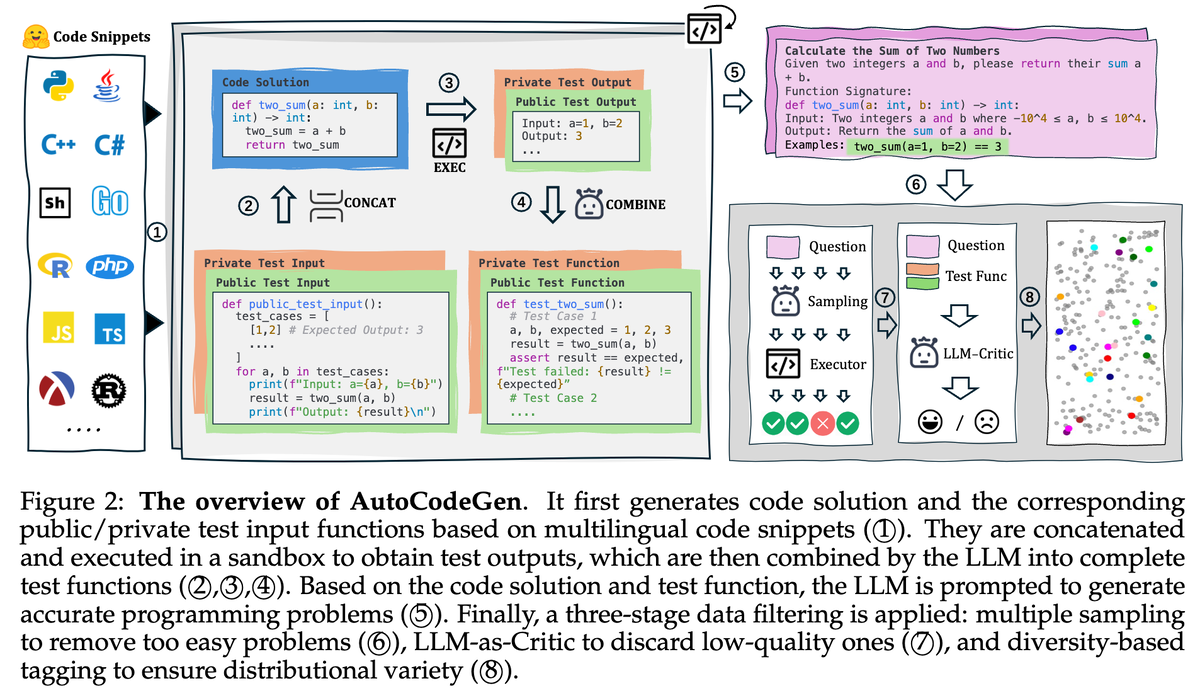
Шаг 1: Посев
Все начинается с простейшего куска кода, «семени». Например, для Python это может быть функция сложения двух чисел: def add_two_numbers(a, b): return a + b. Да, настолько примитивно.
Шаг 2: Эволюция
Этот «зародыш» отправляется нейросети с промптом в духе: «Эй, сделай из этой примитивной функции что-то по-настоящему сложное и полезное. А еще напиши к этому пару простых тестов для примера и десяток сложных, с пограничными случаями».
LLM «эволюционирует» идею. Из сложения чисел может получиться, например, функция для подсчета суммы вложенных массивов с разными типами данных.
Шаг 3: Первая проверка в «песочнице»
Сгенерированное решение и тесты тут же летят на проверку в MultiLanguageSandbox. На этом этапе важно понять — код вообще запускается? Не падает с ошибкой? Если да — едем дальше. Если нет — в мусорку.
Шаг 4: Гениальный ход — тесты на основе фактов
И вот тут начинается магия. Система не просто верит нейросети на слово. Она берет код решения, тестовые вызовы из шага 2 и реальный вывод, который получился в песочнице на шаге 3. Все это снова отправляется LLM с новой задачей.
Мы не просто просим нейросеть написать тесты из головы. Мы даем ей фактические, проверенные данные о поведении кода и просим обернуть их в формат assert'ов.
Это ключевой момент. Нейросеть не фантазирует, какими должны быть результаты, а работает с уже подтвержденными фактами. Качество тестов на выходе получается на порядок выше.
Шаг 5: Финальный штрих — описание задачи
Когда у системы есть проверенное решение и проверенные тесты, она снова обращается к LLM: «А теперь, дружище, напиши под все это красивое и понятное условие задачи для человека. Сделай описание, формат ввода-вывода и используй простые тесты в качестве примера».
Вуаля! На выходе мы имеем готовую задачу, которую можно давать студентам, использовать на собеседованиях или в олимпиадах.
MultiLanguageSandbox: Почему это не просто "запуск скрипта"
Может показаться, что «песочница» — это просто запуск кода в консоли. Но там все куда хитрее.
Во-первых, безопасность. Весь код выполняется от имени специального пользователя с урезанными правами. Он не может ходить в интернет (кроме разрешенных адресов), не может получить доступ к файловой системе за пределами своей клетки. Даже если нейросеть сгенерирует вредоносный код, он останется заперт.
Во-вторых, гибкость. Вся логика компиляции и запуска для 30+ языков описана в простом конфигурационном файле. Это позволяет легко добавлять новые языки.
В-третьих, оптимизация. Например, для Java реализован пул постоянно запущенных JVM. Это экономит кучу времени, так как не нужно для каждого теста поднимать тяжеловесную виртуальную машину с нуля.
Что все это значит?
Появление таких инструментов, как AutoCodeBenchmark, — это не просто технологический прикол. Это серьезный звоночек для всей индустрии IT-образования.
- Конец ручного создания контента. Зачем методисту неделями выдумывать и выверять задачи начального и среднего уровня, если машина может генерировать их сотнями в час? Ценность простого контента стремится к нулю.
- Угроза для «курсов-конвейеров». Те онлайн-школы, чей главный продукт — это набор предзаписанных лекций и типовых задач, оказываются в уязвимом положении. Если ядро их продукта можно сгенерировать автоматически, за что тогда платит студент?
- Смещение ценности в сторону менторства. Как я уже не раз говорил, образование — это не про информацию. Это про мотивацию, обратную связь, сообщество и личный пример. Ценностью становятся не задачи, а живой эксперт, который проверяет твой код, направляет твою мысль и делится реальным опытом. То, что машина пока еще делать не научилась.
Больше таких разборов и мыслей — в моем Telegram-канале PythonTalk.
Как думаете, когда нейросети начнут не только писать код и задачи к нему, но и проводить собеседования? Кажется, ждать осталось недолго.