Event-Driven Architecture (EDA) — это фундаментальная концепция в современном дизайне систем, особенно в связке с микросервисами.
1. Краткое определение
Event-Driven Architecture (EDA) или событийно-ориентированная архитектура — это архитектурный паттерн, в котором работа системы строится вокруг генерации, обнаружения, потребления и реакции на события (events).
- Событие — это неизменяемый факт о том, что что-то значимое произошло в системе (например: OrderCreated, UserPaymentFailed, InventoryUpdated). Событие несет в себе данные о произошедшем, но не содержит инструкций о том, что делать дальше.
- Компоненты системы общаются асинхронно через очереди сообщений (Message Queues) или брокеры сообщений (Message Brokers), что обеспечивает слабую связанность, масштабируемость и отказоустойчивость.
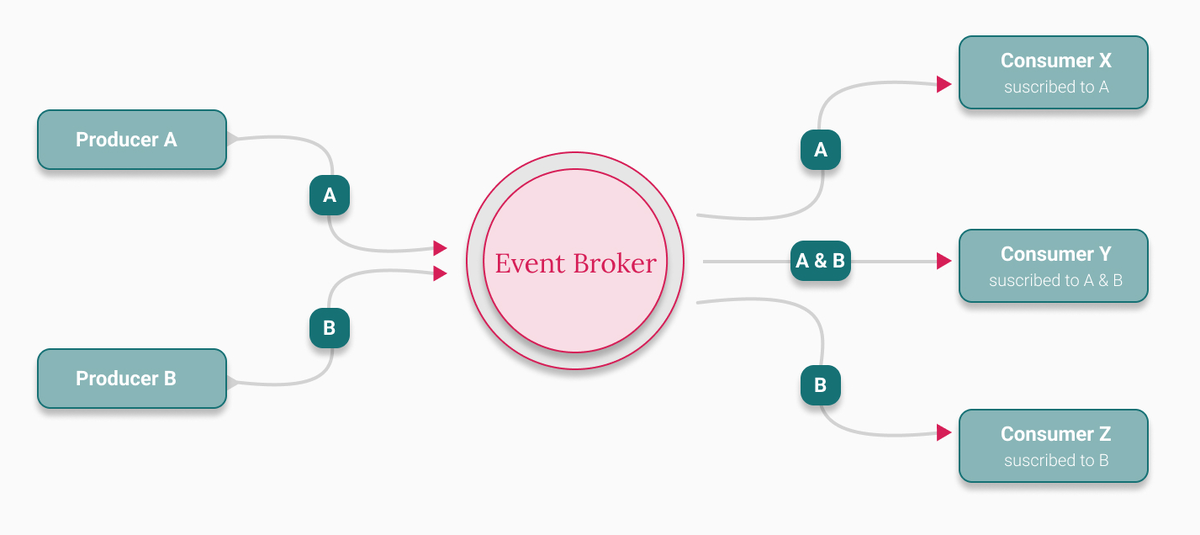
2. Ключевые компоненты EDA
- Event Producer (Источник/Продюсер): Сервис, который публикует событие в брокер, когда происходит что-то важное. Пример: OrderService публикует OrderPlaced.
- Event Consumer (Потребитель / Подписчик): Сервис, который подписывается на типы событий и обрабатывает их. Пример: EmailService подписан на OrderPlaced и отправляет подтверждение.
- Message Broker (Брокер сообщений): Посредник, который принимает события от продюсеров, маршрутизирует их и хранит до тех пор, пока потребители не обработают их. Примеры: Apache Kafka, RabbitMQ, AWS SNS/SQS, Google Pub/Sub.
3. Основные паттерны взаимодействия
а) Pub/Sub (Издатель/Подписчик)
- Как работает: Продюсер публикует (publishes) событие в топик (topic) или канал (channel). Множество потребителей могут подписаться (subscribe) на этот топик. Брокер доставляет копию события каждому подписчику.
- Аналогия: Подписка на рассылку новостей.
- Когда использовать: Когда одно событие должно запустить обработку в нескольких независимых сервисах.
- Пример: Событие UserSignedUp публикуется в топик. На него подписаны:
- EmailService (отправляет приветственное письмо)
- AnalyticsService (обновляет счетчик регистраций)
- RecommendationService (создает профиль для новых рекомендаций)
б) Message Queues (Очереди задач)
- Как работает: Продюсер отправляет сообщение (message) или задачу (task) в очередь (queue). Сообщение из очереди забирает только один из доступных потребителей (модель competing consumers). После успешной обработки сообщение удаляется из очереди.
- Аналогия: Очередь в банке, где первый свободный оператор обслуживает первого в очереди клиента.
- Когда использовать: Для распределения задач или нагрузки между несколькими экземплярами одного и того же сервиса (горизонтальное масштабирование).
- Пример: Сервис загрузки видео VideoUploadService кладет в очередь video-processing-queue сообщение ProcessVideo: video_id=123. Несколько воркеров VideoProcessor слушают эту очередь и обрабатывают видео параллельно.
*Важное замечание: Технически, очереди — это не совсем EDA в чистом виде, так как сообщение часто является командой ("обработай это"), а не событием ("это произошло"). Но на практике эти понятия тесно переплетены и используют одни и те же брокеры.
4. Зачем использовать EDA? (Плюсы)
- Слабая связанность (Loose Coupling): Сервисы-продюсеры не знают и не зависят от сервисов-потребителей. Они просто "кричат в пустоту" о том, что что-то случилось. Это позволяет легко добавлять новую функциональность, просто подписывая новые сервисы на события.
- Асинхронность: Продюсер не блокируется, ожидая ответа от потребителей. Это повышает отзывчивость и пропускную способность системы.
- Масштабируемость: Потребители могут масштабироваться независимо друг от друга. Можно легко добавить больше воркеров для обработки очереди с большим количеством сообщений.
- Отказоустойчивость (Resilience):
- Буферизация: Брокер сообщений действует как буфер. Если потребитель упал, сообщения накапливаются в очереди/топике и будут обработаны после его восстановления.
- Изоляция сбоев: Падение одного потребителя не влияет на продюсера и других потребителей. - Гибкость и эволюционность: Новая бизнес-логика внедряется созданием новых потребителей, а не изменением существующих сервисов.
5. Сложности и минусы (Подводные камни)
- Сложность гарантированной доставки (Guaranteed Delivery): Нужно правильно настраивать подтверждение обработки (acknowledgement) и политики повторных попыток (retry policies), чтобы не потерять сообщения.
- Порядок сообщений (Message Ordering): В распределенных системах сложно гарантировать порядок доставки сообщений. Для некоторых сценариев (например, OrderCreated -> OrderUpdated -> OrderShipped) это критично. Решения: партиционирование в Kafka.
- Идемпотентность (Idempotency): Из-за retry-логики потребитель может получить одно и то же сообщение несколько раз. Потребитель должен быть идемпотентным: повторная обработка одного и того же сообщения не должна приводить к побочным эффектам (например, списывать деньги с карты дважды).
- Сложность мониторинга и отладки: Трассировка запроса, который проходит через несколько асинхронных шагов, становится нетривиальной задачей. Требуются инструменты вроде Distributed Tracing (Jaeger, Zipkin).
- Согласованность данных (Eventual Consistency): EDA почти всегда приводит к eventual consistency. Данные в системе не согласованы мгновенно. Это неприемлемо для некоторых финансовых операций, где нужна строгая согласованность (strong consistency).
6. Как проектировать систему с использованием EDA? (Практические шаги)
- Определите События:
- Используйте язык бизнес-домена: PaymentCompleted, ShipmentDelayed, StockLevelChanged.
- Сделайте события неизменяемыми фактами (facts).
- Включайте в событие всю необходимую информацию(например, в OrderPlaced должен быть order_id, customer_id, список товаров). - Выберите правильный Брокер:
- Kafka: Для высоких нагрузок, долгосрочного хранения, потоковой обработки. Гарантирует порядок в пределах партиции.
- RabbitMQ: Для сложной маршрутизации, рабочих очередей (background jobs). Классический брокер сообщений.
- AWS SQS/SNS: Простота использования в облаке, managed-сервис, не нужно администрировать. - Спроектируйте Потребителей:
- Продумайте идемпотентность. Используйте idempotency_key или проверяйте, обрабатывалось ли сообщение с таким event_id ранее.
- Настройте логику повторных попыток и Dead Letter Queue(DLQ) для сообщений, которые постоянно не обрабатываются.
- Учитывайте возможность параллельной обработки и ее влияние на порядок сообщений. - Смоделируйте Отказоустойчивость:
- Что, если брокер упадет ?(Нужны продюсеры, которые могут буферизовать сообщения локально до его восстановления).
- Что, если потребитель будет падать при обработке одного и того же сообщения ?(Сообщение попадет в DLQ, нужен процесс для анализа таких сообщений). - Продумайте Мониторинг:
- Мониторьте длину очередей (queue length). Растущая очередь — признак того, что потребители не успевают.
- Внедрите трейсинг (OpenTelemetry) для отслеживания цепочки событий. Мониторьте ошибки и DLQ.
7. Пример проектирования системы
Задача: "Спроектируйте систему для интернет-магазина с использованием EDA".
Ответ:
- Ключевые события: OrderPlaced, PaymentProcessed, PaymentFailed, InventoryReserved, InventoryOutOfStock, OrderShipped.
- Сервисы и их роли:
- OrderService: Принимает заказ, публикует событие OrderPlaced.
- PaymentService: Подписан на событие OrderPlaced - обрабатывает оплату, публикует событие PaymentProcessed или PaymentFailed.
- InventoryService: Подписан на событие OrderPlaced, резервирует товар, публикует событие InventoryReserved или InventoryOutOfStock.
- ShippingService: Подписан на событие PaymentProcessed и InventoryReserved. Только после получения обоих событий запускает процесс доставки и публикует событие OrderShipped.
- NotificationService: Подписан на все ключевые события и отправляет email/SMS-уведомления пользователю. - Схема Saga: Этот поток, где успешное выполнение заказа зависит от последовательности событий, является реализацией паттерна Saga для управления распределенными транзакциями. В случае PaymentFailed, нам понадобится компенсирующее действие(Compensation Action) (например, CancelInventoryReservation).
- Компенсирующее действие(Compensation Action) – это операция, предназначенная для отмены или обратного изменения результатов предыдущей транзакции, в случае, если основная операция не может быть успешно завершена или произошла ошибка. Оно является неотъемлемой частью реализации надежных распределенных систем, работающих в асинхронном режиме.
Данный дизайн делает каждый сервис независимым и сфокусированным на своей задаче.