NVIDIA тихо, без громких лозунгов, выпустила модель нового поколения — Nemotron-Nano-9B-v2 — и сразу встала вровень с эталонами открытого сегмента. Главная интрига — гибридная архитектура Mamba‑Transformer (Nemotron‑H), которая на сложных задачах рассуждения и длинного контекста сохраняет точность уровня Qwen3‑8B, но при этом обеспечивает до 6,3× прирост吞吐ности в типичных сценариях (например, 8k входа/16k выхода).
Для индустрии, где стоимость инференса и параллелизм — ключ, это смена повестки: “точность как у лучших, скорость — кратно выше”.
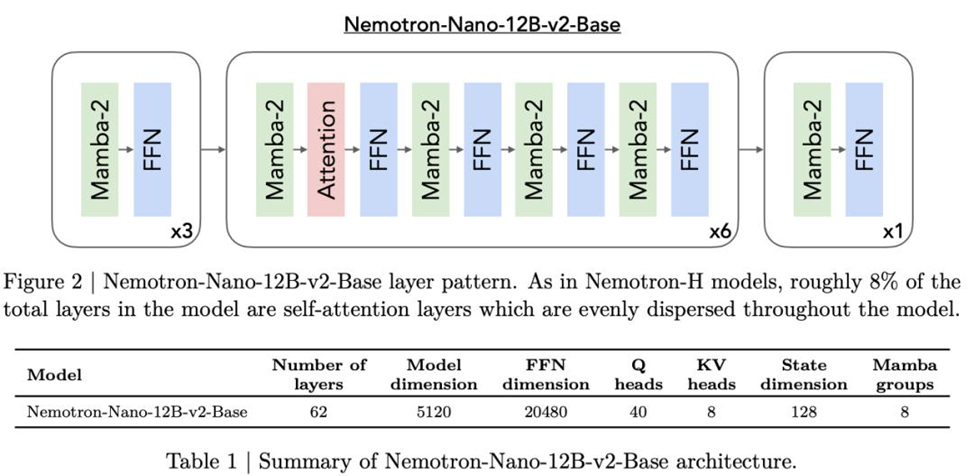
О чем модель и зачем гибрид
Nemotron‑Nano‑9B‑v2 — это 9‑миллиардная языковая модель, ориентированная на быстрый и дешевый инференс без потери качества на математике, коде, обобщенном бенчмарке рассуждений и длинном контексте. Ключ к скорости — замена подавляющей части слоев самовнимания молниеносными слоями Mamba‑2.
- Transformer славится качеством, но его самовнимание имеет квадратичную сложность O(n^2), что бьет по памяти и времени на длинных последовательностях.
- Mamba — класс SSM (структурированные модели состояния) без внимания, с линейной сложностью и избирательным механизмом, который динамически хранит нужное и отбрасывает лишнее. Она блестяще работает на сверхдлинных последовательностях, но может уступать в задачах “копирования” и чистого in‑context‑обучения.
- Гибрид Mamba‑Transformer сочетает сильные стороны обоих: Mamba‑2 берёт на себя длинные рассуждения и массовую генерацию, отдельные слои внимания сохраняют способности к копированию/сопоставлению шаблонов. Итог — “длинные мысли” летят, точность не провисает.
Как учили: “сначала — большой молот”, потом — тонкая огранка
- Предобучение на 20 трлн токенов с FP8: сначала формируют мощную 12B‑базу (Nemotron‑Nano‑12B‑v2‑Base) на смешанном корпусе высокого качества: веб, многоязычие, математика, код, академический текст. Особый упор — на аккуратно очищенные математические и кодовые наборы.
- Многоэтапное выравнивание (SFT, DPO, GRPO, RLHF): улучшение рассуждений, диалога, инструментального вызова и безопасности.
- Экстремальная компрессия Minitron: структурированная обрезка + дистилляция с доводкой 12B до 9B. Цель — чтобы одна A10G (22 ГиБ) держала 128K контекста без фокусов с памятью. Это про “инженерию под прод”.
Что показывает на бенчмарках
По заявленным результатам, Nemotron‑Nano‑9B‑v2 держится на уровне или превосходит открытые конкуренты класса 8–12B: Qwen3‑8B, Gemma3‑12B и др.
- Математика: GSM8K, MATH.
- Код: HumanEval+, MBPP+.
- Общее рассуждение: MMLU‑Pro.
- Длинный контекст: RULER‑128k.
При этом吞吐ность в сценарии 8k→16k выше до 6,3× — именно тот случай, когда “и точность, и скорость”.
Опенсорс не для галочки: модели и, главное, данные
NVIDIA одновременно выкатила сразу три модели на Hugging Face (все поддерживают 128K контекст):
- NVIDIA‑Nemotron‑Nano‑9B‑v2 — выровненная и “подрезанная” для инференса.
- NVIDIA‑Nemotron‑Nano‑9B‑v2‑Base — подрезанная “база”.
- NVIDIA‑Nemotron‑Nano‑12B‑v2‑Base — исходная база до выравнивания/обрезки.
Но главный подарок — большой пакет предобучающих данных Nemotron‑Pre‑Training‑Dataset‑v1 (около 6,6T токенов из веба, математики, кода, SFT и многоязычных QA), структурированный на четыре направления:
- Nemotron‑CC‑v2: последовательно обработанные CommonCrawl‑срезы 2024–2025, глобальная дедупликация, переписывание Qwen3‑30B‑A3B, многоязычный QA (15 языков) для сильной многоязычной базы.
- Nemotron‑CC‑Math‑v1: 133B токенов математики, стандартизированной в LaTeX при сохранении формул и кода (Lynx+LLM pipeline). По качеству — ориентир для math‑pretrain.
- Nemotron‑Pretraining‑Code‑v1: крупный набор кода с GitHub с многоступенчатой очисткой, проверками лицензий и эвристикой качества, плюс LLM‑сгенерированные QA по 11 языкам.
- Nemotron‑Pretraining‑SFT‑v1: синтетические данные для STEM/академии/рассуждений/многоязычия: сложные MCQ, аналитические вопросы из первичных научных источников, graduate‑уровень текста, инструкции по математике/программированию/QA/логике.
Есть и sample‑набор с 10 представительными подмножествами — для быстрой репликации экспериментов.
Почему это важно
- Поворот к экономике инференса. В открытом сегменте “точность сравнялась” — побеждает тот, кто даёт больше ценности на доллар без просадки качества. Гибрид Mamba‑Transformer — практическое решение этой задачи.
- Индустриальная методология. Большая база (20T), строгие этапы выравнивания, системная компрессия и чёткая цель по железу (A10G, 128K) — это инженерия, а не демо для слайдов.
- Данные как главный дефицит. NVIDIA впервые массово делится структурированными, воспроизводимыми наборами высокого качества для математики, кода и многоязычия — именно то, чего не хватает большинству открытых проектов.
Где применять уже сегодня
- Высокопараллельные сервисы: ассистенты поддержки, извлечение фактов и длинные саммари из документов — там, где счёт идёт на запросы/секунду и стоимость токена.
- Длинный контекст: аудит и комплаенс, анализ техдоков, рефакторинг больших баз кода, юридические пайплайны.
- Специализированные задачи математики и кода: автогенерация тестов, фиксы, интерактивные туторы.
- Кост‑сенситивные и edge‑развёртывания: 9B + 128K на одной A10G — простой путь к дешёвому продакшену.
Как это смотрится на фоне рынка
- По сравнению с чистым Transformer (например, Qwen3‑8B), Nemotron‑Nano‑9B‑v2 на длинной генерации и сложных цепочках рассуждений выигрывает в吞吐ности при сопоставимой точности.
- В сравнении с “большими” моделями: SOTA‑точность по‑прежнему требует больше параметров и расходов, но для большинства приложений экономическая эффективность инференса критичнее абсолютных баллов на бенчмарках.
- На фоне осторожности Meta с открытыми релизами и фрагментированных опенсорс‑инициатив, пакет NVIDIA выглядит как “комплект для дела”: модели, данные, воспроизводимость.
Как попробовать
- Онлайновый доступ: https://build.nvidia.com/nvidia/nvidia-nemotron-nano-9b-v2
- Исследовательская страница проекта: NVIDIA Research (NVIDIA‑Nemotron‑Nano‑2)
- Модели и датасеты — на Hugging Face по именам, указанным выше.
Вывод
Открытая гонка сместилась из “кто точнее” в “кто быстрее при той же точности”. Nemotron‑Nano‑9B‑v2 показывает, что гибридные архитектуры — не эксперимент ради статьи, а работающий инструмент для продакшена: 6х ценность там, где это действительно окупается, и аккуратно выстроенная дорожка от 20T предобучения до дешевого деплоя на массовом железе. Если вам нужна производительная модель среднего класса для длинных задач и плотных очередей — это один из самых прагматичных кандидатов сезона.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru