Всем привет! Я — практикующий исследователь данных, и на этом канале делюсь тем, что реально работает в IT. Никакой сухой теории, только личный опыт, рабочие инструменты и грабли, на которые я уже наступил за вас. Рад, что вы здесь!
В первой части я разбирал базу, без которой в аналитике трудновато: от описательных статистик до p-value. Мы научились понимать, о чём говорят данные, и доказывать, что наши выводы — не просто удачное совпадение.
Но мир данных естественно глубже, чем кажется на первый взгляд. Если первая статья была про то, как научиться читать карту (данные), то эта — про то, как прокладывать по ней маршруты, объезжать пробки и даже предсказывать, где они возникнут. 🚀
Почему мы продолжаем копать?
Освоив базу, ты можешь ответить на вопрос "что произошло?". Но бизнес всегда хочет знать больше: "почему это произошло?", "что будет дальше?" и "какой из пяти вариантов лучше?". Инструменты из этой статьи помогут ответить именно на эти вопросы. Они позволяют сравнивать множество групп, строить прогнозы и оценивать, насколько ваши результаты не только статистически, но и практически значимы.
Более глубокие концепции и как их использовать
1. Доверительные интервалы: не точка, а диапазон
Описательная статистика из первой части даёт нам точечные оценки (например, средний чек — 5100 рублей). Но насколько мы уверены в этой цифре? Если мы возьмём другую выборку, среднее почти наверняка будет другим. Доверительный интервал (ДИ) — это диапазон, в котором с определённой вероятностью (обычно 95%) лежит истинное среднее всей генеральной совокупности.
Пример кода:
import numpy as np
from scipy import stats
data = df['revenue']
# Строим 95% доверительный интервал для среднего
confidence_level = 0.95
degrees_freedom = len(data) - 1
sample_mean = np.mean(data)
sample_standard_error = stats.sem(data)
confidence_interval = stats.t.interval(confidence_level, degrees_freedom, sample_mean, sample_standard_error)
print(f"Среднее: {sample_mean:.2f}")
print(f"95% доверительный интервал: ({confidence_interval[0]:.2f}, {confidence_interval[1]:.2f})")
# Пример вывода:
# Среднее: 5100.00
# 95% доверительный интервал: (4950.50, 5249.50)
Применение: Теперь, отчитываясь перед бизнесом, ты говоришь не "средний чек — 5100", а "мы на 95% уверены, что реальный средний чек всех наших клиентов лежит в диапазоне от 4950 до 5250 рублей". Это звучит гораздо профессиональнее и честнее, показывая естественную изменчивость данных.
Лайфхак: На собеседовании могут спросить: "Что означает 95% доверительный интервал?". Правильный ответ: "Если мы возьмём 100 разных выборок и для каждой построим такой интервал, то примерно 95 из них будут содержать истинное среднее".
2. Дисперсионный анализ (ANOVA): когда групп больше двух
В A/B-тесте мы сравниваем две группы с помощью t-теста. А что, если у нас A/B/C/D-тест? Например, мы тестируем 4 разных заголовка для рекламного объявления. Проводить кучу t-тестов (группа A с B, A с C, A с D, B с C и т.д.) — плохая идея, потому что это раздувает вероятность ошибки (ошибки первого рода).
ANOVA (Analysis of Variance) приходит на помощь. Она проверяет нулевую гипотезу о том, что средние всех групп равны, против альтернативы, что хотя бы одно среднее отличается.
Пример кода:
from scipy.stats import f_oneway
# Данные по конверсии для 4 версий заголовков
group_a = [0.12, 0.15, 0.11, 0.14]
group_b = [0.18, 0.20, 0.17, 0.19]
group_c = [0.10, 0.12, 0.13, 0.11]
group_d = [0.19, 0.21, 0.22, 0.20]
f_statistic, p_value = f_oneway(group_a, group_b, group_c, group_d)
print(f"p-value: {p_value:.4f}")
if p_value < 0.05:
print("Есть значимая разница хотя бы между одной парой групп!")
# Пример вывода: "p-value: 0.0001"
Применение: Если p-value < 0.05, мы отвергаем H0 и заключаем: "Заголовки работают по-разному". После этого уже можно использовать специальные тесты (например, тест Тьюки), чтобы понять, какие именно группы отличаются друг от друга.
Лайфхак: ANOVA — это как t-тест на стероидах, о котором мы говорили в прошлой статье. На собесе могут спросить: "Почему нельзя просто провести много t-тестов?". Я бы ответил: "Это увеличивает кумулятивную ошибку. При 20 сравнениях с уровнем значимости 0.05 вероятность ошибиться хотя бы раз достигает почти 100%".
3. Линейная регрессия: предсказываем будущее
Корреляция из первой части показывает, есть ли связь между переменными. Регрессия идёт дальше: она моделирует эту связь и позволяет делать прогнозы. Простейший вариант — линейная регрессия, которая описывает связь уравнением прямой y = kx + b.
Пример кода:
from sklearn.linear_model import LinearRegression
import numpy as np
# Допустим, у нас есть данные по тратам на рекламу и выручке
X = df[['ad_spend']] # Траты на рекламу
y = df['revenue'] # Выручка
model = LinearRegression()
model.fit(X, y)
# Предсказываем, какая будет выручка, если потратить на рекламу 1000
predicted_revenue = model.predict(np.array([[1000]]))
print(f"Прогноз выручки: {predicted_revenue[0]:.2f}")
print(f"Коэффициент R-квадрат: {model.score(X, y):.2f}")
# Пример вывода:
# Прогноз выручки: 23555.34
# Коэффициент R-квадрат: 0.05
Применение: С помощью регрессии можно ответить на вопросы типа: "Сколько мы заработаем, если вложим в маркетинг 1 млн рублей?" или "Как изменится время на сайте, если мы ускорим загрузку на 0.1 секунды?". Коэффициент R-квадрат показывает, какой процент изменчивости "y" объясняется нашей моделью.
Лайфхак: Не забывай проверять условия применимости линейной регрессии (линейность, гомоскедастичность, нормальность остатков). На собесе вопрос "Что такое R-квадрат?" достаточно популярен. Объясняй просто: "Это доля дисперсии зависимой переменной, объясняемая нашей моделью. Если R-квадрат 0.7, значит, 70% изменений в выручке мы можем объяснить изменениями в рекламных тратах".
4. Критерий хи-квадрат (χ²): когда данные — не числа
Что делать, если мы работаем с категориальными данными? Например, мы хотим понять, зависит ли выбор тарифа ("Базовый", "Стандарт", "Премиум") от города пользователя ("Москва", "СПб", "Регионы").
Критерий хи-квадрат сравнивает наблюдаемые частоты с ожидаемыми (теми, которые были бы, если бы зависимости не было).
Пример кода:
from scipy.stats import chi2_contingency
import pandas as pd
# Таблица сопряженности: наблюдаемые частоты
data = {'Москва': [50, 30, 10], 'СПб': [40, 40, 20], 'Регионы': [100, 80, 50]}
obs = pd.DataFrame(data, index=['Базовый', 'Стандарт', 'Премиум'])
chi2, p_value, _, _ = chi2_contingency(obs)
print(f"p-value: {p_value:.4f}")
if p_value < 0.05:
print("Есть значимая связь между городом и выбором тарифа!")
# Пример вывода
# p-value: 0.1120
Применение: Идеально для анализа результатов опросов, категорий товаров, пользовательских сегментов. Можно проверить, кликают ли на разные дизайны баннеров с одинаковой частотой или нет.
Лайфхак: Хи-квадрат не говорит о силе или направлении связи, а только о её наличии. Если p-value низкий, мы знаем, что переменные связаны, но для понимания как именно нужно смотреть на таблицу сопряженности.
Новые грабли и как их избежать
- Проводить t-тесты вместо ANOVA. Как уже говорили, это раздувает ошибку. Если групп 3 и больше — твой выбор ANOVA.
- Экстраполяция в регрессии. Не пытайся предсказать выручку для рекламного бюджета в 10 млн, если твоя модель обучалась на данных до 100 тыс. Результат будет ненадёжным.
- Не проверять условия моделей. Регрессия и другие модели имеют свои допущения. Их игнорирование ведёт к неверным выводам.
- Путать статистическую и практическую значимость. При очень больших выборках даже крошечная, бесполезная разница может стать статистически значимой (p < 0.05). Всегда смотри на размер эффекта: разница в 0.001% конверсии может быть не важна для бизнеса, даже если p-value очень низкий.
Лайфхаки для аналитиков 2.0
- Начинай с вопроса. Прежде чем применять сложный метод, сформулируй бизнес-вопрос. Это поможет выбрать правильный инструмент.
- Изучи байесовский подход. Это альтернатива классической (фреквентистской) статистике, которая отлично себя показывает при малом количестве данных и позволяет обновлять выводы по мере их поступления.
- Общайся с неопределённостью. Используй доверительные интервалы, чтобы показать, что твои результаты — это не истина в последней инстанции, а наиболее вероятная оценка.
- Сегментируй. Часто общий вывод скрывает интересные инсайты. Проведи анализ не для всех пользователей, а для разных сегментов (новые/старые, мобильные/десктоп).
**Ну и бонус, чтоб глаз радовался.
График 1: Зависимость выручки от рекламы с "умной" детализацией
Этот график — не просто точки на плоскости. Это scatterplot, который показывает сразу три вещи:
- Основную зависимость: как выручка (revenue) растёт с увеличением трат на рекламу (ad_spend).
- Сравнение групп: точки раскрашены в зависимости от группы A/B-теста (control vs test).
- Размер заказа: размер каждой точки зависит от количества товаров (quantity).
Такой график позволяет одним взглядом оценить корреляцию, увидеть, есть ли разница в поведении групп, и заметить самые крупные заказы.
Код для построения (пайтон):
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Загружаем наши данные
df = pd.read_csv('sales_data.csv')
# Настраиваем стиль и размер графика
sns.set_theme(style="whitegrid")
plt.figure(figsize=(14, 8))
# Строим график
scatter_plot = sns.scatterplot(
data=df,
x='ad_spend',
y='revenue',
hue='group', # Раскрашиваем по группам A/B-теста
size='quantity', # Размер точки зависит от кол-ва товаров
sizes=(20, 200), # Диапазон размеров точек
alpha=0.7, # Прозрачность, чтобы видеть наложения
palette='viridis' # Красивая цветовая схема
)
# Добавляем заголовок и подписи осей
plt.title('Зависимость выручки от расходов на рекламу', fontsize=16)
plt.xlabel('Расходы на рекламу (у.е.)', fontsize=12)
plt.ylabel('Выручка (у.е.)', fontsize=12)
plt.legend(title='Группа A/B-теста')
plt.grid(True)
plt.show()
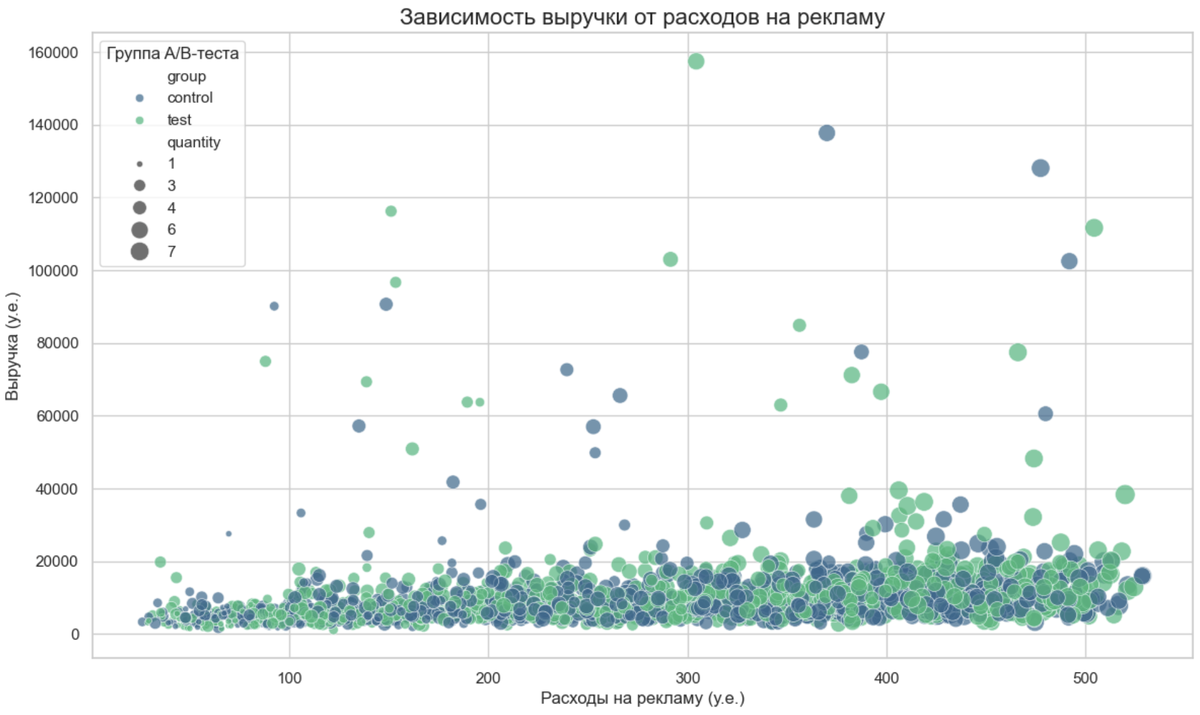
Что мы здесь видим? Чёткую положительную тенденцию: больше тратим на рекламу — больше зарабатываем. Видно, что точки тестовой группы (жёлтые) в среднем располагаются чуть выше, а самые большие круги (крупные заказы) разбросаны по всему графику.
График 2: Элегантное сравнение A/B-теста
Вместо скучных столбчатых диаграмм можно использовать violin plot (скрипичный график). Он показывает не только медиану и квартили (как box plot), но и саму форму распределения данных. Это идеальный способ наглядно показать результаты A/B-теста.
Код для построения (пайтон):
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Загружаем данные
df = pd.read_csv('sales_data.csv')
# Настраиваем стиль
sns.set_theme(style="whitegrid")
plt.figure(figsize=(10, 8))
# Строим violin plot
sns.violinplot(
data=df,
x='group',
y='revenue',
palette='muted', # Спокойная цветовая палитра
inner='quartile', # Внутри покажем квартили
linewidth=1.5
)
# Добавляем точки для наглядности (stripplot)
sns.stripplot(
data=df,
x='group',
y='revenue',
color='k', # Черный цвет
alpha=0.05, # Сделаем почти прозрачными
jitter=0.2 # Немного разбросаем по горизонтали
)
# Добавляем заголовок и подписи
plt.title('Распределение выручки в контрольной и тестовой группах', fontsize=16)
plt.xlabel('Группа', fontsize=12)
plt.ylabel('Выручка (у.е.)', fontsize=12)
plt.show()
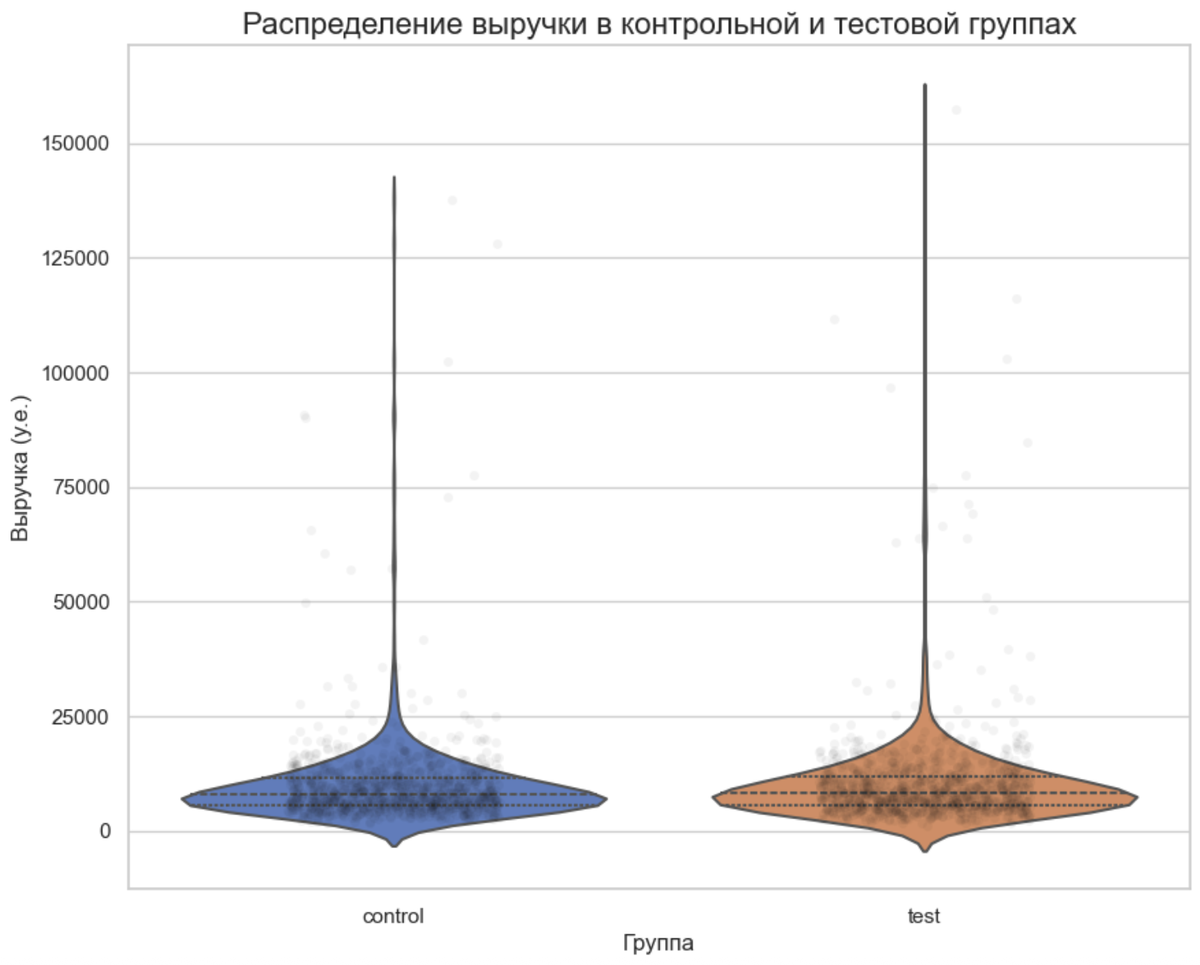
Что мы здесь видим? "Скрипка" для тестовой группы (test) немного "пузатее" в верхней части и смещена вверх по сравнению с контрольной. Это визуальное подтверждение того, что в тестовой группе выручка в среднем действительно выше. Широкая нижняя часть обеих "скрипок" показывает, что большинство заказов приносят небольшую выручку, а тонкие "хвосты" уходят вверх — это наши редкие, но дорогие заказы (выбросы).
Итоги второй части
Мы добавили в наш арсенал мощные инструменты: доверительные интервалы для честной оценки, ANOVA для сравнения многих групп, регрессию для прогнозов и хи-квадрат для анализа категорий. Теперь ты можешь не просто констатировать факты, но и строить модели, предсказывать результаты и давать бизнесу более глубокие и обоснованные ответы.
Статистика — это бесконечный путь, но с каждым шагом ты становишься всё более ценным специалистом. Не бойся копать глубже! 🧑💻
Я не претендую на истину в последней инстанции, просто рассказываю, как иду по пути аналитика. Спасибо, что дочитали! 😎 Подписывайтесь 👇👇👇, лайкайте 👍🏽👍🏽, пишите в комментах пожелания, вопросы, замечания. Буду рад любой активности. Впереди разборы инструментов, навыков и IT-фишек!