Пока вся IT-тусовка с замиранием сердца ожидала анонса GPT-5 от OpenAI, команда Anthropic неожиданно выкатила обновление, которое может изменить правила игры в разработке. Claude Opus 4.1 не просто улучшенная версия - это совершенно новый уровень ИИ-ассистирования для программистов.
Что заставило Anthropic поспешить с релизом
Любопытно, что компания выпустила Claude Opus 4.1 в ту же неделю, на которую планируется релиз GPT-5. Совпадение? Я думаю, нет. Ранее инсайдеры сообщали, что новая модель OpenAI превосходит Claude Opus 4 в программировании - не исключено, что неожиданный выпуск обновленной версии был сделан в попытке как минимум сократить отставание.
Timing релиза говорит сам за себя. Anthropic явно не хотели отдавать пальму первенства без боя. И знаете что? Они были правы.
Что получилось на практике: цифры впечатляют
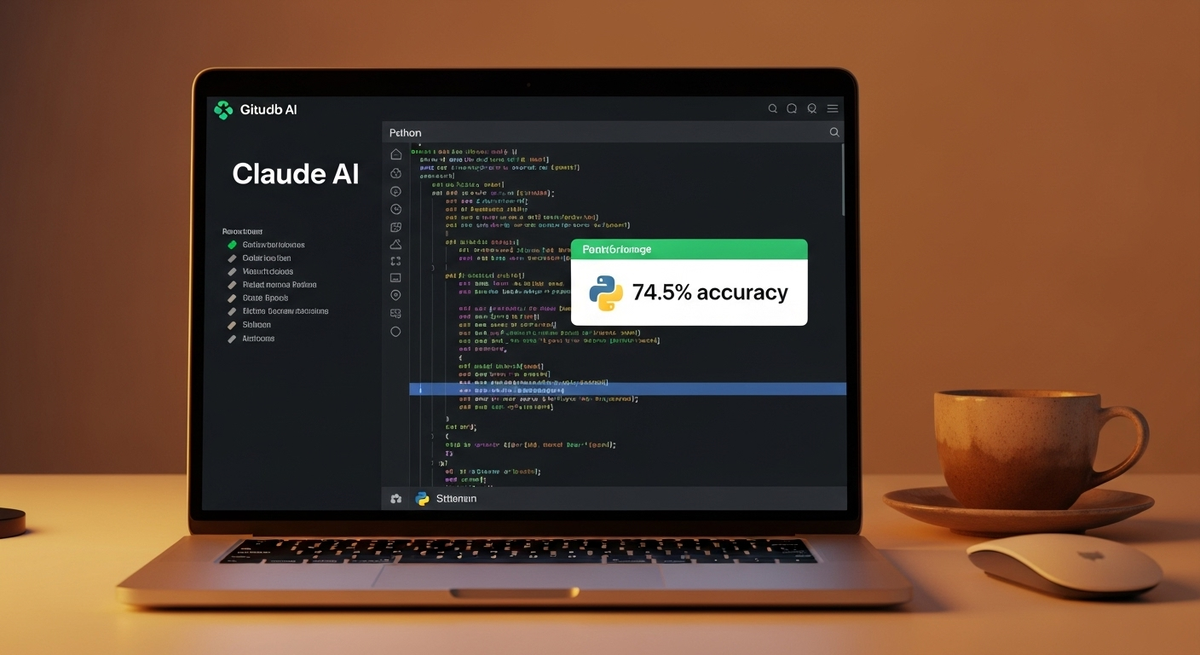
Claude Opus 4.1 достигает 74.5% точности на SWE-bench Verified против 72.5% у предыдущей версии - это самый высокий результат среди всех публично доступных моделей. Для сравнения: Claude Sonnet 3.7 показывает только 62.3%.
SWE-bench Verified - это не какие-то абстрактные задачки. Это реальные баги из open-source проектов, которые модель должна найти и исправить. Представьте: из 500 реальных проблем ИИ решает 372. Это уже не просто помощник, а полноценный член команды.
GitHub отмечает особенно заметные улучшения в рефакторинге многофайловых проектов. Rakuten Group обнаружили, что Opus 4.1 превосходно находит точные исправления в больших кодовых базах, не внося ненужных изменений и не создавая новых багов.
А вот реальная история от пользователя: "Opus 4.1 за пару часов нашел моего белого кашалота - баг, над которым я ломал голову 4 года". Человек дал модели старый и новый код, попросил найти ошибку после рефакторинга - и Opus 4.1 справился там, где другие модели пасовали.
Подводные камни: не все так радужно
Есть нюанс, о котором мало говорят. На лидерборде Aider показано, что Sonnet 4 в некоторых кодинговых тестах даже уступил своему предшественнику 3.7. Один пользователь делится: "Я попытался написать простой Python-скрипт на Sonnet 4. Приходилось по несколько раз уточнять интенцию, пока не сдался и не попробовал с 3.7 - и она решила задачу сразу".
Правда, это касается Sonnet 4, а не Opus 4.1. А вот с Opus 4.1 пока таких жалоб не поступало.
В Visual Studio Code Opus 4.1 доступен только в ask mode - то есть полноценного агентного режима пока нет. Это ограничивает возможности для автономной работы с кодом.
Кому это точно подойдет: практические советы
Если вы работаете с большими legacy-проектами - Claude Opus 4.1 станет вашим спасением. Модель показывает рекордную точность в целевых задачах кодинга: автоисправление багов, рефакторинг, написание сложных алгоритмов.
DevOps-инженерам тоже будет интересно: Claude Opus 4 способен прочитать десятки тысяч строк логов, выделить паттерны ошибок и сгенерировать сводные отчеты. В тестах с реальными логами специалисты отметили, что модель легко находит причину сбоя и предлагает фиксы.
Модель уже доступна для платных пользователей Claude, через Claude Code, API, Amazon Bedrock и Google Cloud Vertex AI. В GitHub Copilot доступна для планов Enterprise и Pro+.
Лично я считаю, что это серьезная заявка на лидерство в нише ИИ для программистов. Разработчики в Cursor называют Opus 4.1 "новым эталоном в кодинге", а Replit видит "драматический прогресс при работе с множеством файлов". Windsurf сообщает об улучшении производительности на целое стандартное отклонение - это как прыжок от джуниора к миддлу.
А вы уже тестировали Claude Opus 4.1? Поделитесь опытом - интересно сравнить с другими инструментами!
Подписывайтесь на мой Telegram канал "ProAI"
#ИИ #программирование #ClaudeOpus #разработка #инструменты