Проект энтузиаста Wilson Lin по созданию поисковой системы с нуля за 2 месяца стал настоящим феноменом в IT-сообществе, набрав 415 очков на Hacker News. Этот амбициозный проект не только продемонстрировал возможности современных технологий векторного поиска, но и показал, как один разработчик может бросить вызов гигантам индустрии. В эпоху, когда Google доминирует с 93% рынка поисковых систем, появление альтернативных подходов к поиску информации открывает новые возможности для инноваций и конкуренции.
Мотивация и цели проекта
Wilson Lin столкнулся с двумя ключевыми проблемами современного поиска: ухудшением качества результатов из-за SEO-спама и ограниченностью традиционного подхода, основанного на сопоставлении ключевых слов. Вместо интеллектуального понимания контекста, большинство поисковых систем полагаются на примитивное сопоставление терминов, что не позволяет обрабатывать сложные, многосмысловые запросы.
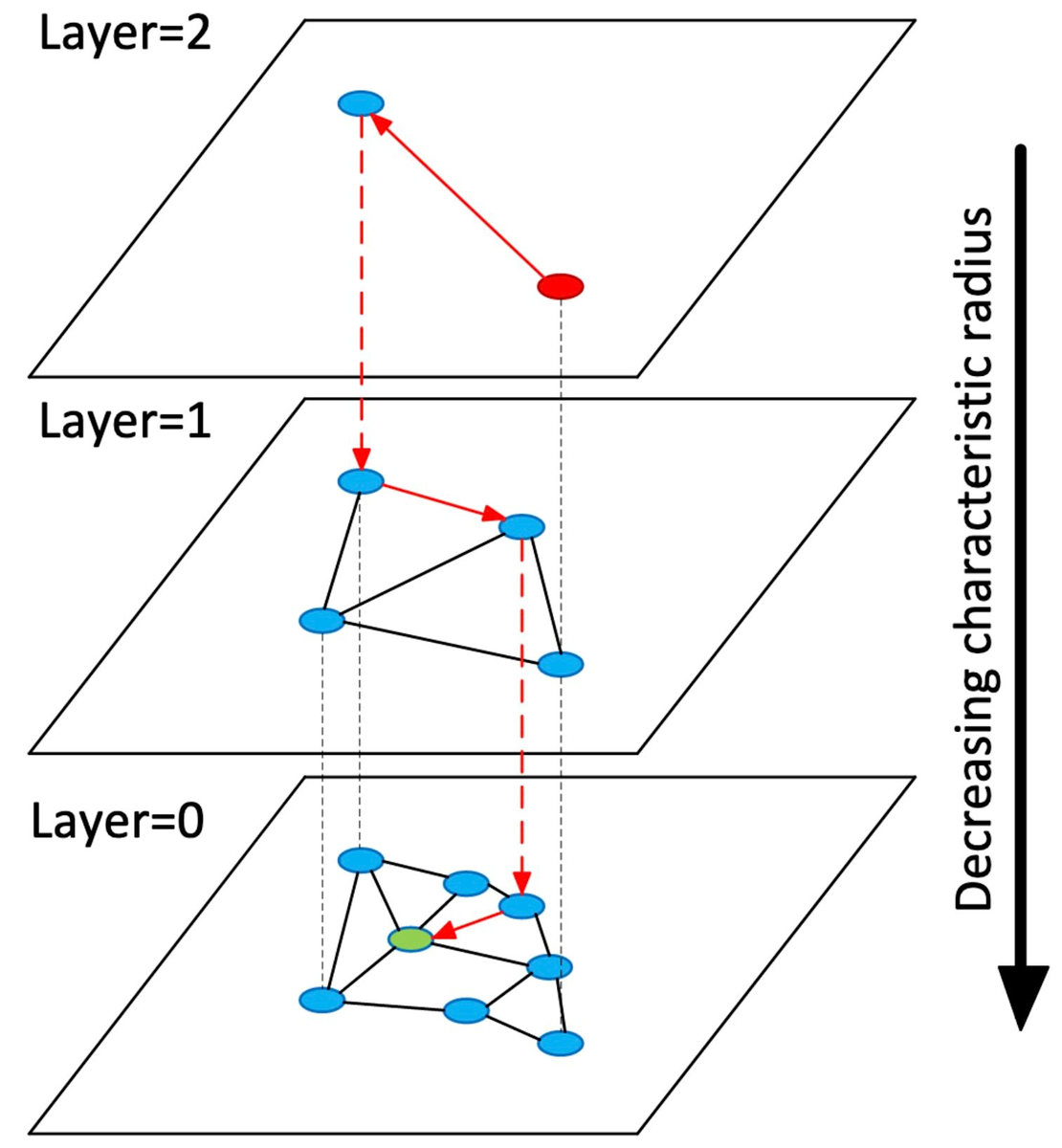
Основная идея заключалась в создании поисковой системы, которая понимает намерение, а не просто ключевые слова. Такая система должна была:
- Анализировать запросы целостно, не разбивая их на отдельные слова
- Не требовать от пользователя инженерии запросов или использования специальных операторов
- Корректно обрабатывать концептуальные и контекстные запросы
- Находить неочевидные связи между концепциями
- Быть устойчивой к SEO-манипуляциям и спаму
Техническая архитектура и масштаб
Проект впечатляет своими масштабами: кластер из 200 GPU генерировал 3 миллиарда SBERT эмбеддингов, сотни краулеров обрабатывали до 50,000 страниц в секунду, создавая индекс из 280 миллионов документов. Конечная задержка запросов составляла около 500 миллисекунд при использовании RocksDB и HNSW, распределенных по 200 ядрам, 4 ТБ оперативной памяти и 82 ТБ SSD-накопителей.
Нормализация и обработка контента
Первым этапом конвейера обработки стала нормализация HTML-контента для извлечения семантического текста. Wilson Lin разработал мини-спецификацию для обработки веб-страниц:
- Структурная консистентность: приведение таблиц и списков к единому формату
- Семантическая фильтрация: сохранение только значимых текстовых элементов (p, table, pre, blockquote, ul, ol, dl)
- Очистка: удаление скриптов, атрибутов, пустых элементов и навигационных элементов
- Контекстуализация: использование семантических элементов как <article> или ARIA-ролей для выделения основного контента
Инновационный подход к сегментации
Ключевой инновацией стала интеллектуальная сегментация текста на предложения с сохранением семантического контекста. Вместо простого деления по количеству символов, Wilson Lin использовал:
Семантический контекст: каждое предложение дополнялось заголовками разделов, метками таблиц и ведущими утверждениями
Цепочечные зависимости: специально обученная модель DistilBERT определяла зависимости между предложениями, создавая цепочки контекста для обеспечения полноты смысла
Векторизация с SBERT
Для создания эмбеддингов использовались модели SBERT (Sentence-BERT), которые генерируют векторные представления предложений, улавливающие их семантическое значение. SBERT решает проблему скорости традиционного BERT: вместо 65 часов на поиск среди 10,000 предложений, SBERT создает эмбеддинги за 5 секунд и выполняет сравнения за 0.01 секунды.
Алгоритм HNSW и векторный поиск
Для быстрого поиска по миллиардам векторов Wilson Lin использовал алгоритм HNSW (Hierarchical Navigable Small World), который создает многоуровневую графовую структуру для приближенного поиска ближайших соседей.
HNSW работает по принципу:
Иерархическая структура: алгоритм создает многоуровневый граф, где верхние уровни содержат меньше узлов и служат для быстрой навигации
Жадный поиск: начиная с входной точки на верхнем уровне, алгоритм жадно движется к ближайшему соседу до достижения локального минимума
Спуск по уровням: после достижения локального минимума алгоритм спускается на нижний уровень и продолжает поиск
Масштабирование и шардинг
По мере роста индекса Wilson Lin столкнулся с ограничениями памяти. Решением стало равномерное шардирование HNSW на 64 узла, что позволило сохранить низкую задержку и высокую точность, поскольку каждый шард запрашивается параллельно. Это сохранило качество полного HNSW-индекса без квантизации или деградации.
Оптимизация RocksDB
Для хранения данных использовалась тщательно настроенная конфигурация RocksDB, оптимизированная для записи и использующая возможности NVMe SSD. Ключевые оптимизации включали:
- Максимизация дискового I/O: увеличение количества фоновых задач и синхронизации
- BlobDB: хранение больших значений в отдельных файлах для снижения write amplification
- Большие кэши блоков: использование до 32 ГБ оперативной памяти для кэширования
- Партиционированные индексы: повышение производительности точечных поисков
Сравнение подходов к векторному поиску
График показывает кардинальные различия между подходами:
- Традиционный поиск по ключевым словам обеспечивает низкое потребление памяти (10 ГБ), но точность составляет всего 60%
- HNSW в памяти достигает 95% точности, но требует 2.8 ТБ оперативной памяти для 1 миллиарда векторов
- CoreNN на дисках достигает 96% точности при использовании всего 96 ГБ оперативной памяти
Эволюция к CoreNN
Успех проекта привел к созданию CoreNN — открытой векторной базы данных, решающей ключевые ограничения HNSW:
Использование дешевых дисковых накопителей: стоимость в 40-100 раз ниже по сравнению с оперативной памятью
Бесшовное масштабирование: от 1 до 1 миллиарда векторов в одном индексе
Живые обновления: upsert и delete операции выполняют локальные оптимизации графа без полной перестройки
Конкурентные запросы: поддержка одновременных запросов и обновлений без блокировки
CoreNN использует инновационный подход с "дополнительными соседями" (backedge deltas) для минимизации write amplification при вставке новых узлов, избегая дорогостоящих перезаписей существующих узлов.
Современный контекст: рынок векторных баз данных в 2025 году
Проект Wilson Lin оказался пророческим — рынок векторных баз данных в 2025 году переживает взрывной рост. По данным аналитиков, объем рынка достиг 18,000 крор рупий (2.2 млрд долларов) в 2024 году и прогнозируется рост до 90,000 крор рупий (10.6 млрд долларов) к 2032 году при ежегодном темпе роста свыше 21%.
Лидеры рынка 2025
Pinecone остается лидером управляемых решений с долей рынка 60.4%, предлагая полностью управляемую облачную платформу без необходимости управления инфраструктурой
Milvus доминирует среди open-source решений, обеспечивая исключительную производительность при обработке миллиардов векторов
Weaviate выделяется гибридной архитектурой, объединяющей векторный поиск с графами знаний
Qdrant привлекает внимание расширенными возможностями фильтрации и дружелюбным API
ИИ-поисковые системы: новая эра
Параллельно с развитием векторного поиска, рынок ИИ-поисковых систем демонстрирует впечатляющий рост. По состоянию на август 2025 года:
ChatGPT лидирует с долей 60.4%, расширив возможности поиска через SearchGPT
Perplexity захватил 6.5% рынка с ростом в 13% за квартал, специализируясь на точности и ссылках на источники
Google Gemini держит 13.5% рынка, интегрируя ИИ в традиционный поиск
Изменение поведения пользователей
Данные показывают значительный сдвиг в поведении пользователей:
- Органический трафик Google снизился с 94.80% в 2024 году до 93.05% в 2025 году
- ИИ-трафик вырос в 4 раза: с 0.02% до 0.13% глобально
- В США ИИ-поиск достиг 0.14%, обогнав некоторые традиционные поисковые системы
Технологические инновации
Transformer и нейронный поиск
Проект Wilson Lin опирался на революцию transformer-архитектуры, представленной Google в статье "Attention Is All You Need" 2017 года. Иронично, что Google, изобретя трансформеры, упустил первую волну ИИ-поиска, позволив OpenAI и другим стартапам занять лидирующие позиции.
M3-Embedding и многоязычность
Современные модели эмбеддингов, такие как M3-Embedding, демонстрируют беспрецедентную универсальность в многоязычности, многофункциональности и мультигранулярности. Эти модели способны работать с различными языками, типами поиска и размерами входных данных до 8192 токенов.
Оптимизация производительности
Исследования показывают, что высокая размерность векторов не всегда коррелирует с лучшими результатами. Модель OpenAI text-embedding-3-large с 3072 измерениями может быть урезана до 256 измерений с минимальной потерей качества, обеспечивая экономию ресурсов в 12 раз.
Retrieval-Augmented Generation (RAG)
Проект Wilson Lin предвосхитил развитие RAG — методики, которая стала краеугольным камнем современных ИИ-систем. RAG позволяет большим языковым моделям обращаться к внешним знаниям, комбинируя параметрическую память модели с непараметрической памятью в виде векторных индексов.
Эволюция RAG
RAG эволюционировал от простых (Naive RAG) к продвинутым (Advanced RAG) и модульным (Modular RAG) подходам:
Naive RAG: простой процесс индексации, поиска и генерации
Advanced RAG: включает предварительную обработку, оптимизацию поиска и постобработку
Modular RAG: гибкие модули для специализированных задач
Бенчмарки и оценка качества
Проект внес вклад в развитие методологий оценки эмбеддингов. MTEB (Massive Text Embedding Benchmark) стал стандартом оценки, а в 2025 году появился MMTEB, охватывающий более 500 задач на 250+ языках.
Новые метрики
Современные бенчмарки фокусируются на:
- Многоязычности: оценка работы с различными языками
- Длинных документах: обработка контекста до 32,000 токенов
- Специализированных доменах: код, медицина, право
- Эффективности: соотношение качества и вычислительных ресурсов
Влияние на индустрию
Стартапы и инновации
Проект Wilson Lin вдохновил волну стартапов в области поиска:
Brave Search разработала независимый индекс с акцентом на приватность
Perplexity сфокусировалась на точности и цитировании источников
You.com предлагает персонализированный ИИ-поиск
Mojeek создала 100% независимый индекс
Приватность и альтернативы
Растущие проблемы приватности стимулируют развитие альтернативных поисковых систем:
- DuckDuckGo лидирует в privacy-first поиске с долей 0.86% глобально
- Startpage предлагает результаты Google без отслеживания
- Ecosia комбинирует поиск с экологическими инициативами
Вызовы и ограничения
Вычислительная сложность
Несмотря на успехи, масштабирование векторного поиска остается сложной задачей:
- Curse of dimensionality: производительность снижается с ростом размерности
- Memory bandwidth: ограничения пропускной способности памяти
- Index maintenance: сложность обновления больших индексов
Quality vs Scale Trade-offs
Исследования показывают фундаментальные компромиссы:
- Большие модели не всегда означают лучшее качество
- Scaling laws могут достигать пределов
- Инженерные оптимизации часто важнее размера модели
Будущее векторного поиска
Мультимодальность
Современные системы движутся к мультимодальному поиску, обрабатывающему текст, изображения, аудио и видео в едином векторном пространстве. Это открывает возможности для более естественного и интуитивного взаимодействия.
Edge Computing
Развитие edge computing позволяет выполнять векторный поиск локально на устройствах пользователей, обеспечивая низкую латентность и приватность.
Специализированные решения
Индустрия движется к специализированным решениям для различных доменов:
- Enterprise search: поиск по корпоративным данным
- E-commerce: рекомендательные системы
- Healthcare: поиск по медицинским данным
- Legal: анализ правовых документов
Экономическая эффективность
Проект Wilson Lin продемонстрировал, что качественный векторный поиск может быть экономически эффективным. CoreNN показал возможность снижения стоимости инфраструктуры в 40-100 раз при сохранении качества.
Cost Optimization Strategies
Ключевые стратегии оптимизации затрат:
- Quantization: снижение точности векторов для экономии памяти
- Compression: сжатие индексов без значительной потери качества
- Caching: интеллектуальное кэширование частых запросов
- Auto-scaling: автоматическое масштабирование под нагрузку
Социальное влияние
Демократизация поиска
Проекты как Wilson Lin демократизируют технологии поиска, показывая, что инновационные решения могут создаваться небольшими командами или даже индивидуальными разработчиками. Это снижает барьеры входа и стимулирует конкуренцию с технологическими гигантами.
Open Source движение
Растущая экосистема open-source векторных баз данных и поисковых систем обеспечивает альтернативы проприетарным решениям, предотвращая монополизацию критически важных технологий.
Заключение
Проект Wilson Lin по созданию поисковой системы с 3 миллиардами нейронных эмбеддингов стал катализатором революции в области информационного поиска. За два месяца разработки один энтузиаст продемонстрировал возможности современных технологий векторного поиска и нейронных эмбеддингов, опередив многие корпоративные исследования.
Ключевые достижения проекта:
Техническая инновация: демонстрация масштабируемости HNSW и эффективности SBERT для семантического поиска
Экономическая эффективность: доказательство возможности создания высококачественных поисковых систем с ограниченными ресурсами
Влияние на индустрию: стимулирование развития векторных баз данных и альтернативных поисковых систем
Open Source вклад: создание CoreNN как открытой платформы для дальнейших инноваций
В 2025 году мы видим плоды этих усилий: взрывной рост рынка векторных баз данных, появление ИИ-поисковых систем и формирование новой парадигмы информационного поиска. Проект показал, что будущее поиска лежит не в механическом сопоставлении ключевых слов, а в глубоком понимании семантики и намерений пользователей.
Эта революция только начинается. С развитием мультимодальных моделей, улучшением эффективности алгоритмов и растущим вниманием к приватности, мы движемся к эре поистине интеллектуального поиска, где машины будут понимать нас так же хорошо, как мы понимаем друг друга.