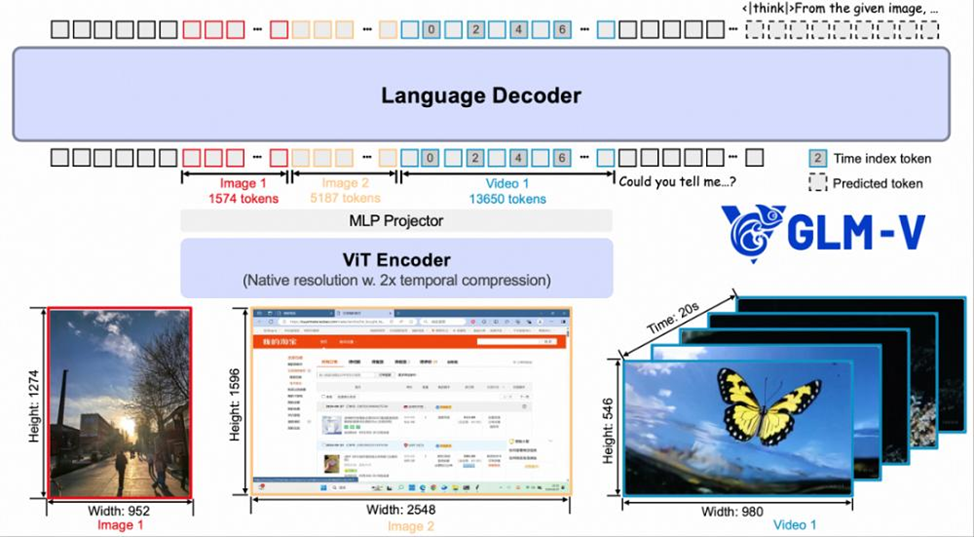
Zhipu AI представила и открыла GLM‑4.5V — новое поколение мультимодальной модели понимания визуальных данных. Модель тренирована на текстовой базе GLM‑4.5‑Air, продолжает «мыслящую» линию GLM‑4.1V‑Thinking, насчитывает 106 млрд параметров (MoE с ~12 млрд активных) и получила ручной переключатель режима «Thinking».
Для разработчиков — открытый код, FP8‑квантизованные веса, настольный ассистент и щедрый бесплатный пакет API на 20 млн токенов.
Ссылки на релиз и демо:
- Репозиторий: GitHub — https://github.com/zai-org/GLM-V
- Коллекции весов: Hugging Face — https://huggingface.co/collections/zai-org/glm-45v-68999032ddf8ecf7dcdbc102; ModelScope — https://modelscope.cn/collections/GLM-45V-8b471c8f97154e
- Демо‑приложение (настольный ассистент): https://huggingface.co/spaces/zai-org/GLM-4.5V-Demo-App
- Онлайн‑пример воссоздания веб‑страницы: https://chat.z.ai/space/f00sx6s4jgp1-art
Что умеет на практике
- Тонкая визуальная дифференциация. Модель распознаёт отличия между крылышками McDonald’s и KFC, аргументируя по цвету прожарки, текстуре корочки и т. п. Это хороший индикатор семантического «зрения», а не лишь OCR.
- «Угадай место по фото». За 7 дней участия GLM‑4.5V заняла 66‑е место на сайте соревнований, обойдя 99% игроков. При этом в сложных кейсах без явных ориентиров модель может ошибаться (в одном тесте спутала уголок Линьиньсы с локацией на Цинчэншане), но демонстрирует прозрачный ход рассуждений и опорные признаки.
- GUI‑понимание и агентные сценарии. На скриншотах интернет‑магазина считает скидки, перепроверяет вывод и объясняет шаги. Линейка агент‑фреймворков AutoGLM уже использует GLM‑4.5V как визуальный «мозг».
- Код по скриншоту/видео. По записи экрана или снимку веб‑страницы генерирует HTML/CSS/JS с приближённым внешним видом и частично восстанавливает логику. В одном из тестов по скриншоту модель выдала верстку за ~10 минут с высокой визуальной схожестью (хотя без интерактивов — их лучше подавать через видеозапись).
- Документы, PDF, слайды. Суммирует, переводит, извлекает таблицы и графики, опираясь на «визуальное чтение», а не голый OCR, что снижает каскадные ошибки и лучше сохраняет структуру.
- Визуальная локализация. По вопросу находит и маркирует целевой объект, возвращает координатные рамки — полезно для инспекций, ретейла, геонаблюдений.
Внутренняя валидация Zhipu: из 42 бенчмарков по картинкам, видео, документам и GUI‑агентам GLM‑4.5V лидирует в 41 относительно моделей сопоставимого класса (Step‑3, Qwen2.5‑VL и др.).
Что под капотом
- Контекст и модальности. 64K мультимодальный контекст, входы — изображения, видео, файлы, текст. Для видео — 3D‑свертки; для высоких разрешений и экстремальных пропорций — двукратная бикубическая интерполяция; для пространственно‑временной «геометрии» — 3D‑RoPE.
- Три фазы обучения. Предобучение на крупной мультимодальной смеси с упором на длинный контекст; SFT с явными образцами цепочек рассуждений (CoT) для причинно‑следственного и мультимодального понимания; RL‑этап с мультирежимной системой вознаграждений, сочетающей RLVR и RLHF, таргетно усиливающей STEM‑задачи, локализацию и агентные умения.
Открытость и инструменты
- Доступность. Веса и код доступны на GitHub/HF/ModelScope; есть FP8‑вариант. Для пользователей — приложение‑просмотрщик на Mac (Apple Silicon).
- Онлайн‑опыт. Модель уже подключена в z.ai (можно загрузить картинку/видео, включить «режим размышления») и в приложениях «Чистый диалог» от Zhipu.
- Настольный ассистент (open source). Умеет делать скриншоты, запись экрана и передавать в GLM‑4.5V для задач от код‑помощи до анализа видео/документов.
- API и квоты. На BigModel.cn запущен API с бесплатным пакетом 20 млн токенов. Биллинг заявлен от 2 RMB за 1 млн входных токенов и 6 RMB за 1 млн выходных; поддержаны изображение, видео, файлы и текст.
Ограничения и ожидания
- В задачах «угадай локацию» без явных ориентиров возможны уверенные, но неверные гипотезы — важно смотреть на объяснение и не полагаться безусловно.
- Воссоздание интерфейсов по статике передаёт стиль и структуру, но интерактивы требуют видеоданных и итераций.
- FP8 и большие контексты снижают барьер входа, но для масс‑инференса и агентных пайплайнов стоит учитывать бюджет латентности и стоимость вывода.
Почему это важно
Визуальная компетентность — ключ для агентов, которые взаимодействуют с компьютером и реальным миром, а не только с текстом. GLM‑4.5V сочетает сильное «зрение», управляемое размышление и практичную открытость: можно локально экспериментировать, собрать настольный ассистент, встроить в робофлоу инспекций или GUI‑автоматизацию — и всё это с низким порогом входа.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru