🎥 ДОЛГОСРОЧНАЯ ПАМЯТЬ В ВИДЕОМОДЕЛЯХ: РЕШЕНИЕ ОТ СТЭНФОРДА И ADOBE
Задумывался, почему видео-модели искусственного интеллекта быстро «забывают» события из далёкого прошлого? 🤔 Это мешает им планировать и принимать решения в динамичных условиях.
Почему это важно? Потому что долгосрочная память — ключ к сложным задачам и глубокому пониманию сцен.
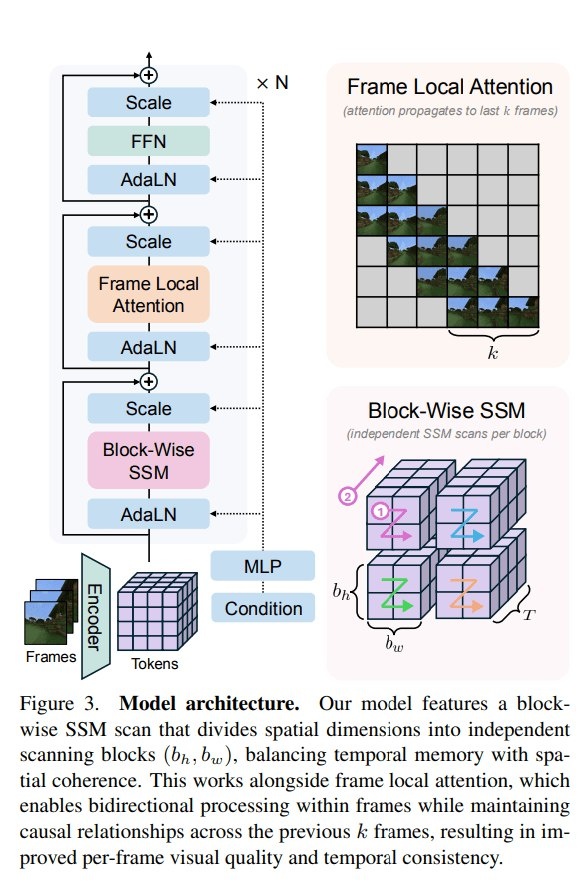
Учёные из Стэнфорда, Принстона и Adobe придумали, как расширить память видео-моделей без перегрузки процессора. Они объединили продвинутые State-Space Models (SSMs) с блоковой обработкой видео и плотным локальным вниманием.
📌 Главный трюк — разбивать видео на блоки, запоминая ключевую информацию между ними и дополнять это локальным вниманием для чёткости деталей. Так модель и «видит» далеко в прошлое, и остаётся точной.
Вдобавок, они ввели diffusion forcing — обучение, которое заставляет модель держать согласованность по длинным отрезкам, и frame local attention — ускоряющую механизм внимания для быстрой работы.
Проверили подход на сложных задачах