Автор: Рогов.А
Уровень: Сложный В файле электронной таблицы в каждой строке содержатся шесть натуральных чисел. Определите количество строк таблицы, для которых выполнены оба условия:
в строке хотя бы одно число повторяется дважды (ровно 2 раза);
каждое из повторяющихся дважды (ровно 2 раза) чисел превышает каждое неповторяющееся. Опасная задача потому что автор учитывает ситуацию, когда список uncopied пустой, что может вызывать ошибку при использовании функции max(). Больше разборов на эту и другие задачи вы можете найти в нашем Телеграм канале: Информатика ЕГЭ | itpy 👨💻 Подписывайтесь на наш канал по теории Python: Азим вкатывается в IT | itpy 💻 Вы найдете тут много полезного!
Автор: Рогов.А
Уровень: Сложный
Условие задачи:
В файле электронной таблицы в каждой строке содержатся шесть натуральных чисел. Определите количество строк таблицы, для которых выполнены оба условия:
в строке хотя бы одно число повторяется дважды (ровно 2 раза);
каждое из повторяющихся дважды (ровно 2 раза) чисел превышает каждое неповторяющееся.
Теоретическая справка:
Опасная задача потому что автор учитывает ситуацию, когда список uncopied пустой, что может вызывать ошибку при использовании функции max().
Код решения:
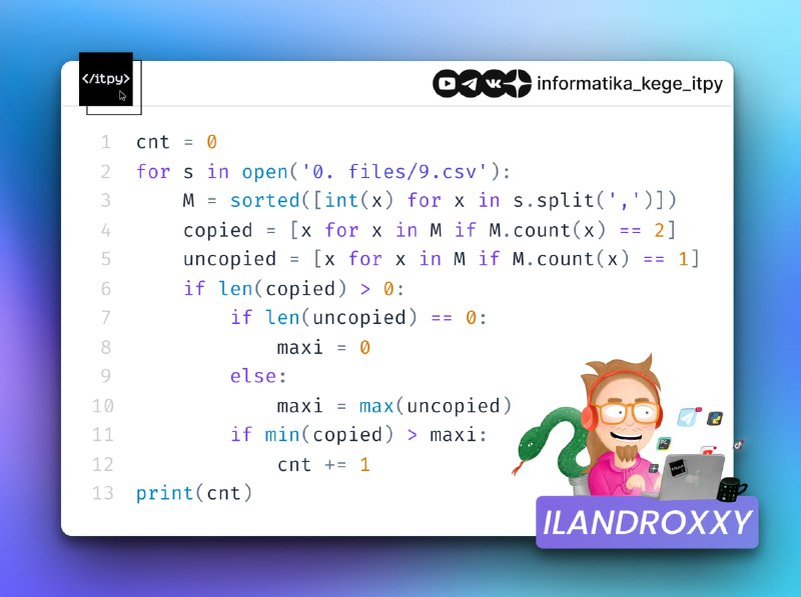
Комментарии к коду:
- cnt = 0
- Создаём переменную-счётчик cnt и инициализируем её нулём.
- Будет хранить количество строк, удовлетворяющих условию. - for s in open('0. files/9.csv'):
- Открываем файл '0. files/9.csv' для чтения.
- Циклом for перебираем каждую строку s из файла. - M = sorted([int(x) for x in s.split(',')])
- Разбиваем строку s по запятым с помощью s.split(',').
- Каждый элемент преобразуем в целое число int(x).
- Полученный список чисел сортируем по возрастанию sorted().
- Результат сохраняем в переменную M. - copied = [x for x in M if M.count(x) == 2]
- Создаём список copied с помощью генератора списка.
- Включаем в него элементы x из M, которые встречаются ровно 2 раза (M.count(x) == 2).
- Это будут числа-дубликаты в текущей строке. - uncopied = [x for x in M if M.count(x) == 1]
- Аналогично создаём список uncopied.
- Включаем элементы, которые встречаются только 1 раз (M.count(x) == 1).
- Это уникальные числа в текущей строке. - if len(copied) > 0:
- Проверяем, есть ли в строке дубликаты (длина списка copied больше 0).
- Если нет, то пропускаем дальнейшие проверки для этой строки. - if len(uncopied) == 0:
- Проверяем, есть ли в строке уникальные числа.
- Если уникальных чисел нет (uncopied пуст) - maxi = 0
- Устанавливаем maxi (максимальное уникальное число) в 0,
- так как сравнивать будем с минимальным дубликатом. - else:
- Если в строке есть уникальные числа: - maxi = max(uncopied)
- Находим максимальное число среди уникальных и сохраняем в maxi. - if min(copied) > maxi:
- Проверяем условие: минимальное число из дубликатов больше maxi.
- Если условие выполняется: - cnt += 1
- Увеличиваем счётчик подходящих строк на 1. - print(cnt)
- После обработки всех строк выводим итоговое значение счётчика cnt.
Больше разборов на эту и другие задачи вы можете найти в нашем Телеграм канале: Информатика ЕГЭ | itpy 👨💻
Подписывайтесь на наш канал по теории Python: Азим вкатывается в IT | itpy 💻 Вы найдете тут много полезного!