
Описание
Допустим ваша компания проводит опросы своих клиентов каждый месяц. И в итоге получает среднюю оценку своей работы — MOS (Mean Opinion Score).
Наша задача: узнать доверительный интервал полученной средней оценки в каждом месяце.
Дано: файлик с оценками клиентов. Колонки:
- 'date' — дата оценки клиента,
- 'clients_month' — количество всех клиентов за месяц,
- 'id_client' — идентификатор клиента,
- 'points' — проставленный балл клиента.
Далее открываем Jupyter notebook, пишем:
# Импорт библиотек
import numpy as np
import pandas as pd
import plotly.graph_objects as go
1. Исходные данные
# Читаем данные
df = pd.read_excel('mos_data.xlsx')
df.info()
# Удаляем ячейки без оценки
df = df[df['points'].notna()]
# Переводим дату опроса в месяц и год
df['month'] = df['date'].dt.to_period('M')
# Порядок в колонках
df = df[['date', 'month', 'id_client', 'clients_month', 'points']]
2. Количество оценок в месяце опроса
df_cnt_pnt = df.groupby(by='month', as_index=False).agg(pnt_cnt=('points', 'count'))
df = df.merge(df_cnt_pnt, how='left', on='month')
3. Стандартное отклонение (STD или σ) 'points' в текущем месяце
df_std = df.groupby(by='month', as_index=False).agg(pnt_std=('points', 'std'))
df = df.merge(df_std, how='left', on='month')
4. Среднее 'points' в текущем месяце
df_avg = df.groupby(by='month', as_index=False).agg(pnt_avg=('points', 'mean'))
df = df.merge(df_avg, how='left', on='month')
5. Стандартная ошибка (SE) 'points' в текущем месяце
Стандартная ошибка среднего с поправкой на конечную популяцию вычисляется по формуле:
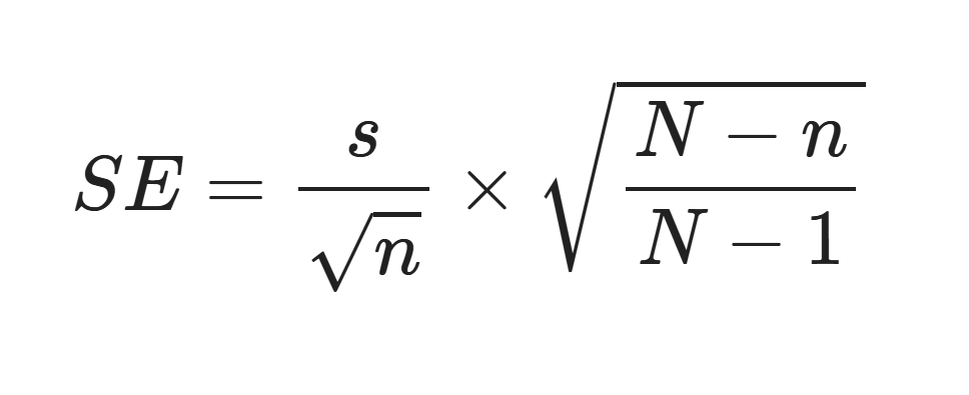
SE — стандартная ошибка среднего (standard error), показатель, который измеряет, насколько среднее значение выборки может отклоняться от истинного среднего генеральной совокупности.
- s — стандартное отклонение выборки, показывает, насколько сильно значения в выборке разбросаны относительно её среднего.
- n — размер выборки, количество наблюдений или ответов в выборке.
- N — общий размер популяции (генеральной совокупности), то есть общее количество клиентов или единиц, из которых берётся выборка.
# Стандартная ошибка (SE)
df['se'] = (df['pnt_std'] / np.sqrt(df['pnt_cnt']))*(np.sqrt((df['clients_month'] - df['pnt_cnt'])/(df['clients_month'] - 1)))
6. Доверительный интервал 'points' в текущем месяце
Число z (z-оценка) — это значение стандартизованной нормально распределённой случайной величины, соответствующее выбранному уровню доверительной вероятности (95%).
value_z = 1.96
df['down_interval'] = df['pnt_avg'] - (value_z * df['se'])
df['up_interval'] = df['pnt_avg'] + (value_z * df['se'])
7. Дисперсия (степень отклонения от среднего) 'points' в текущем месяце
df_variance = df.groupby('month', as_index=False).agg(pnt_var=('points', 'var'))
df = df.merge(df_variance, how='left', on='month')
# Смотрим, что получилось
df.info()
8. Визуализация среднего 'points' и доверительного интервала
fig = go.Figure()
# Линия со средним значением 'points'
fig.add_trace(go.Scatter(
····x=df['date'], y=df['pnt_avg'],
····mode='lines+markers',
····name='Среднее points'))
# Заливка доверительного интервала
fig.add_trace(go.Scatter(
····# сначала по основному порядку
····x=np.concatenate([df['date'], df['date'][::-1]]),
····# потом в обратном
····y=np.concatenate([df['up_interval'], df['down_interval'][::-1]]),
····fill='toself',
····fillcolor='rgba(0,100,80,0.2)',
····line=dict(color='rgba(255,255,255,0)'),
····hoverinfo='skip', showlegend=True,
····name='Доверительный интервал 95%'))
fig.update_layout(
····title='points с 95% доверительным интервалом по месяцам',
····xaxis_title='Месяц', yaxis_title='points',
····template='plotly_white',
····height=700, width=1050)
fig.show()
9. Допущенная ошибка 'points'
value_z = 1.96 # для 95% доверия
def error_from_sample_size(N, s, n, z=value_z):
····# Обработка NaN и нулевых значений s и n
····if np.isnan(s) or s == 0 or n == 0 or np.isnan(n):
········return np.nan
····# Вычисление ошибки по формуле
····E = z * s * np.sqrt((N - n) / (n * (N - 1)))
····return E
# Добавим столбец 'sample_error' с ошибкой для каждой строки в df
df['sample_error'] = df.apply(
····lambda row: error_from_sample_size(
········N=row['clients_month'],
········s=row['pnt_std'],
········n=row['pnt_cnt']),
····axis=1)
# Смотрим что получилось
display(df[['month', 'clients_month', 'pnt_std', 'pnt_cnt', 'sample_error']].drop_duplicates(ignore_index=True))
10. Необходимый размер выборки
Размер выборки рассчитывается по формуле:
- n — необходимый размер выборки;
- N — общий размер генеральной совокупности (общее число клиентов для данного месяца)
- z — z-значение, соответствующее заданному уровню доверия (например, для 95% доверия z ≈ 1.96)
- s — стандартное отклонение оценок в популяции (можно рассчитать по данным выборки)
- E — максимально допустимая ошибка выборки (то есть допустимая погрешность оценки среднего значения, например, 1 означает ошибку ±0.1)
# Константы
confidence_level = 0.95
alpha = 1 - confidence_level
value_z = 1.96 # для 95% доверия.
# Либо считаем: value_z = stats.norm.ppf(1 - alpha / 2)
# Максимально допустимая ошибка выборки
E = 0.1
def required_sample_size(N, s, z=value_z, E=E):
····numerator = N * (z**2) * (s**2)
····denominator = (E**2) * (N - 1) + (z**2) * (s**2)
····n = numerator / denominator
····return np.ceil(n) # Округляем в большую сторону
# Добавим новый столбец в df с расчетом необходимого размера выборки
df['sample_size'] = df.apply(
····lambda row: required_sample_size(
········N=row['clients_month'],
········s=row['pnt_std'] if not np.isnan(row['pnt_std']) else 1.0 # подставить 1 при отсутствии std),
····axis=1)
display(df[['month', 'clients_month', 'sample_error', 'sample_size', 'pnt_cnt']].drop_duplicates(ignore_index=True))
# Округление до сотых долей
df['se'] = round(df['se'], 2)
df['down_interval'] = round(df['down_interval'], 2)
df['pnt_std'] = round(df['pnt_std'], 2)
df['pnt_avg'] = round(df['pnt_avg'], 2)
df['down_interval'] = round(df['down_interval'], 2)
df['up_interval'] = round(df['up_interval'], 2)
df['pnt_var'] = round(df['pnt_var'], 2)
df['sample_error'] = round(df['sample_error'], 2)
# Берём для показа только нужные колонки
df_show = df[['month', 'pnt_cnt', 'sample_error', 'sample_size', 'clients_month', 'pnt_std', 'pnt_avg', 'se', 'down_interval', 'up_interval', 'pnt_var']]
df_show = df_show.drop_duplicates(ignore_index=True)
display(df_show)
- month — месяц опроса.
- pnt_cnt — количество полученных ответов в месяце опроса.
- sample_error — предел допустимой неопределенности (точности) с вероятностью 95%.
- sample_size — рекомендованная выборка по клиентам с точностью 'points' ±0.1.
- clients_month — всего клиентов в месяце опроса.
- pnt_std — стандартное отклонение 'points' по выборке в месяце опроса.
- pnt_avg — среднее значение 'points' по выборке в месяце опроса.
- se — стандартная ошибка, отклонение среднего 'points' от истинного среднего всей совокупности в месяце опроса.
- down_interval — нижнее значение диапазона, в котором с 95% вероятностью находится истинное значение измеряемого параметра.
- up_interval — верхнее значение диапазона, в котором с 95% вероятностью находится истинное значение измеряемого параметра.
- pnt_var — дисперсия, это показатель степени разброса данных вокруг их среднего значения в месяце опроса.
Итоги
- С помощью данного кода можно узнать необходимый размер выборки для заданной точности исследования.
- Можно рассчитать доверительный интервал (ДИ) уже проведённого исследования и узнать погрешность для данной выборки.
- Также можно визуализировать и наглядно показать результаты исследования с помощью библиотеки plotly express.