Привет! Меня зовут Денис Куров. Все мы знакомы с ChatGPT, но у него есть фундаментальная проблема: он не знает ничего о вашей компании, ваших документах и ваших процессах. Он обучен на данных из интернета и его знания устаревают. Дообучать такие модели — долго и невероятно дорого, что было доступно лишь IT-гигантам.
До недавнего времени.
Технология RAG (Retrieval-Augmented Generation) кардинально изменила ситуацию. Она позволяет даже небольшим компаниям использовать мощь больших языковых моделей (LLM) для работы со своими, приватными данными, причём без затрат на дообучение.
💡 Что вы получите: После прочтения вы сможете за 15 минут создать работающую систему вопросов-ответов для ваших документов (инструкций, договоров, базы знаний). Прямо в Google Colab, с реальным кодом.
Как работает RAG на пальцах: аналогия с экзаменом
Представьте, что LLM (как ChatGPT) — это гениальный, но не знакомый с темой студент, которого позвали на экзамен. RAG — это его личный ассистент, который перед каждым вопросом делает три вещи:
- Слушает вопрос: "Как в нашей компании оформить отпуск?"
- Быстро находит нужную страницу в методичке (в ваших документах): находит раздел "Правила предоставления отпусков".
- Подкладывает эту страницу студенту: "Вот, отвечай строго по этому тексту".
В итоге студент-LLM даёт точный ответ на основе вашего документа, а не своих общих знаний.
Ключевое преимущество: RAG не выдумывает. Нет информации в базе — честное "не знаю", а не "галлюцинации". Это критически важно для бизнеса.
Архитектура RAG: два кита вашей системы
Любая RAG-система стоит на двух китах: Поисковике (Retriever) и Генераторе (Generator).
На первый взгляд схема может показаться сложной, но на самом деле она состоит из двух логичных и понятных процессов: Индексация (однократная подготовка ваших данных) и Генерация ответа (то, что происходит при каждом запросе пользователя).
Давайте пройдём по каждому шагу:
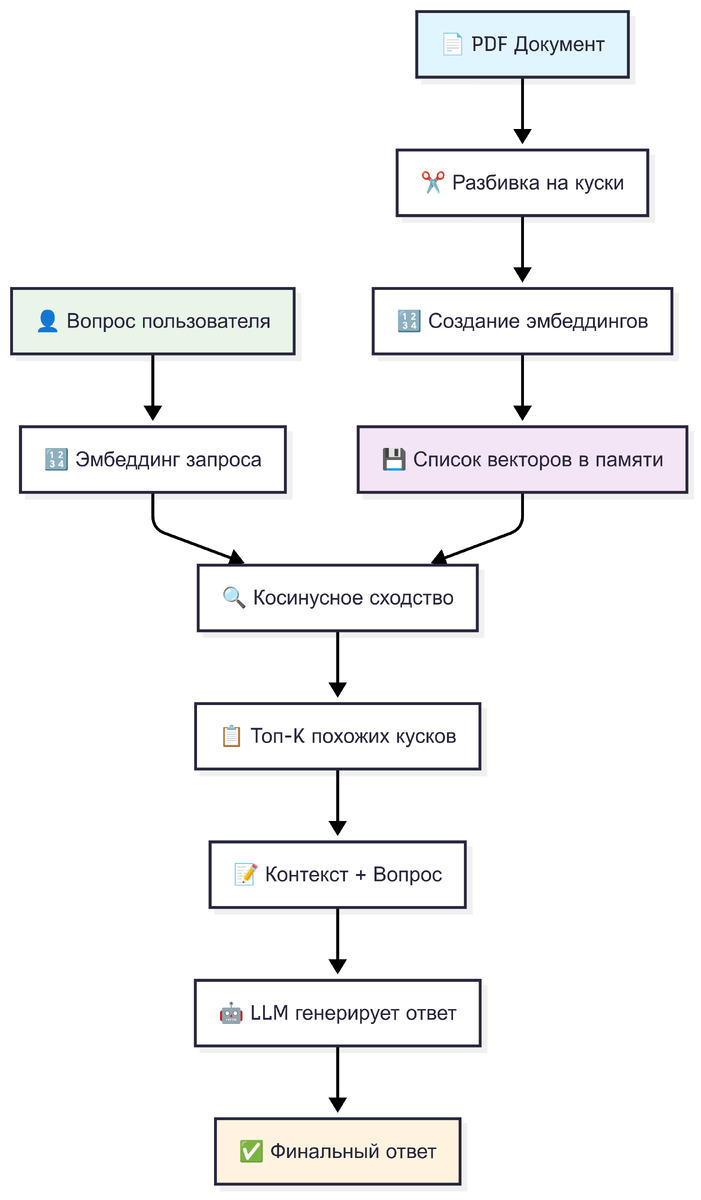
Этап 1: Индексация — Создаём нашу «умную» библиотеку (происходит один раз)
Этот этап выполняется заранее, чтобы подготовить вашу базу знаний к работе.
Шаг A → B: Разбивка на куски (Chunking)
- Что происходит: Мы берём ваш PDF-документ (или любой другой текст) и нарезаем его на небольшие, но осмысленные фрагменты — «чанки». Это могут быть абзацы, группы предложений или логические блоки.
- Зачем это нужно: Большие языковые модели (LLM) имеют ограничение на объём «памяти» (контекстное окно). Мы не можем подать в неё 100-страничный документ целиком. Разбивая текст на чанки, мы позволяем системе находить и работать только с самыми релевантными фрагментами. Это как читать книгу не целиком, а по главам и абзацам.
Шаг B → C: Создание эмбеддингов (Векторизация)
- Что происходит: Это самый важный шаг. Каждый чанк текста мы пропускаем через специальную нейросеть (embedding-модель). Она превращает смысл текста в набор чисел — вектор (или эмбеддинг).
- Зачем это нужно: Этот вектор — своего рода «координаты смысла». Тексты с похожим значением будут иметь близкие числовые векторы. Например, чанки "правила оформления отпуска" и "как взять выходные дни" окажутся «рядом» в этом многомерном пространстве смыслов. Это позволяет нам искать информацию не по ключевым словам, а по значению.
Шаг C → D: Хранение векторов
- Что происходит: Все полученные векторы вместе с исходными текстовыми чанками мы сохраняем. В нашем простом примере — это будет просто список в памяти компьютера. В промышленных системах для этого используются специальные векторные базы данных (Qdrant, Pinecone, Weaviate и др.).
- Зачем это нужно: Это и есть наша готовая база знаний, наша «умная библиотека», где у каждой «книги» (чанка) есть свой уникальный адрес в пространстве смыслов.
Этап 2: Генерация ответа — Путь одного вопроса (происходит каждый раз)
Этот конвейер запускается, как только пользователь задаёт вопрос.
Шаг E → F: Эмбеддинг запроса
- Что происходит: Мы берём вопрос пользователя ("Как получить отпуск?") и делаем с ним то же самое, что и с чанками — превращаем его в вектор с помощью той же embedding-модели.
- Зачем это нужно: Чтобы найти похожие по смыслу тексты, нам нужно «перевести» вопрос на тот же язык чисел, на котором говорит наша база знаний.
Шаг F + D → G: Косинусное сходство (Семантический поиск)
- Что происходит: Теперь у нас есть вектор вопроса и целая библиотека векторов-чанков. Система вычисляет «косинусное сходство» — математическую меру близости между вектором вопроса и каждым вектором в нашей базе.
- Зачем это нужно: Это и есть семантический поиск в действии. Вместо поиска по совпадению слов, мы ищем векторы, которые «смотрят» в том же направлении, что и вектор вопроса. Это позволяет найти релевантные чанки, даже если в них нет ни одного слова из самого запроса.
Шаг G → H: Выбор Топ-K похожих кусков
- Что происходит: Система отбирает несколько (например, 3 или 5 — это и есть «K») чанков, чьи векторы оказались наиболее близки к вектору вопроса.
- Зачем это нужно: Мы не хотим перегружать LLM лишней информацией. Мы даём ей только самые релевантные фрагменты — выжимку из всего документа, необходимую для точного ответа.
Шаг H + E → I: Формирование промпта (Контекст + Вопрос)
- Что происходит: Это момент истины. Мы собираем специальное обращение (промпт) для LLM. Оно включает в себя:Инструкцию: "Ответь на вопрос, используя только текст ниже".
Контекст: Те самые Топ-K релевантных кусков, которые мы нашли.
Вопрос: Исходный вопрос пользователя. - Зачем это нужно: Это аналогия экзамена с открытыми конспектами. Мы не просим модель вспоминать что-то из её глобальных знаний, а даём ей конкретный, проверенный материал и просим построить ответ на его основе.
Шаг I → J → K: Генерация и финальный ответ
- Что происходит: LLM обрабатывает наш промпт и генерирует связный, структурированный ответ, синтезируя информацию из предоставленных кусков.
- Результат: Пользователь получает точный ответ, основанный на содержании именно его документов, часто с указанием источников, из которых была взята информация. Система не "галлюцинирует", а работает как настоящий эксперт по вашей базе знаний.
Теперь, когда мы разобрались в теории, давайте воплотим каждый из этих шагов в коде!
Пошаговая реализация: от теории к практике
Давайте соберём нашу систему. Весь код можно запустить в бесплатном Google Colab.
>>>>>>>>>>>> ссылка на Google Collab
Шаг 1: Подготовка окружения
🔑 Получение API-ключа Nebius Studio
Шаг 1: Регистрация на Nebius Studio
- Перейдите на studio.nebius.com/playground
- Нажмите кнопку "Sign in" в правом верхнем углу
- Выберите способ регистрации (Google, GitHub или email)
- Подтвердите регистрацию
Шаг 2: Создание API-ключа
- После входа в систему нажмите "Get API key"
Дайте ключу понятное название (например, "RAG Tutorial")
- Скопируйте созданный API-ключ - он понадобится в коде!
⚠️ Важно: Сохраните ключ в безопасном месте - после создания его нельзя будет посмотреть повторно.
📋 Ячейка 1: Установка зависимостей
Что происходит:
- !pip install устанавливает необходимые библиотеки в Google Colab
- import fitz - это PyMuPDF библиотека для работы с PDF файлами
- import OpenAI - клиент для работы с API (совместим с Nebius)
- import numpy - для математических операций с векторами
- from google.colab import files - для загрузки файлов в Google Colab
Зачем это нужно:
Эти библиотеки - основа нашей RAG-системы. PyMuPDF извлекает текст из PDF, OpenAI общается с языковой моделью, NumPy вычисляет сходство между векторами.
📁 Ячейка 2: Загрузка PDF файла
Что происходит:
- files.upload() открывает диалог выбора файла в браузере
- uploaded.keys() получает имя загруженного файла
- pdf_filename = list(uploaded.keys())[0] берет первый (и единственный) файл
- with open() сохраняет файл на диск виртуальной машины Google Colab
Результат:
После выполнения этой ячейки у вас будет PDF файл, доступный для дальнейшей обработки в системе.
📄 Ячейка 3: Извлечение текста из PDF
Что происходит:
- fitz.open(pdf_path) открывает PDF файл для чтения
- doc.page_count возвращает количество страниц в документе
- doc.load_page(page_num) загружает конкретную страницу
- page.get_text() извлекает весь текст с этой страницы
- text += добавляет текст каждой страницы к общему тексту
Результат:
Вся текстовая информация из PDF объединяется в одну большую строку extracted_text.
✂️ Ячейка 4: Разбиение текста на фрагменты (Chunking)
Что происходит:
- range(0, len(text), n - overlap)
Создает последовательность начальных позиций для разрезания текста с шагом n - overlap.
Пример: n=1000, overlap=200 → шаг = 800 символов
Позиции: 0, 800, 1600, 2400 и т.д. - text[i:i + n]
Вырезает фрагмент от текущей позиции i до i + n.
Длина каждого фрагмента: строго n символов (кроме последнего).
Пример:Фрагмент 1: text[0:1000]
Фрагмент 2: text[800:1800]
Фрагмент 3: text[1600:2600] - Механизм перекрытия:
Между фрагментами есть область дублирования размером overlap:Фрагмент 1: [0 ... 1000] → Конец 1 в позиции 1000
Фрагмент 2: [800 ... 1800] → Начало 2 в позиции 800
Область [800 1000] (200 символов) входит в оба фрагмента → это перекрытие.
Давайте разберём как это работает на конкретном тексте. Возьмём отрывок из технической документации:
Исходный текст (500 символов):
"Микросервисная архитектура позволяет создавать масштабируемые системы. Однако она требует тщательного планирования взаимодействия служб. Ключевые аспекты включают управление распределенными транзакциями, обеспечение отказоустойчивости и согласованность данных. При неправильном проектировании возникнет дублирование логики и усложнение мониторинга. Оптимальный размер сервиса должен соответствовать бизнес-возможностям."
Разделение с параметрами n=250, overlap=50
Шаг: 250 - 50 = 200 символов
Позиции: 0, 200, 400
Фрагмент 1: [0:250]
Микросервисная архитектура позволяет создавать масштабируемые системы. Однако она требует тщательного планирования взаимодействия служб. Ключевые аспекты включают управление распределенными транзакциями, обеспечение отказоустойчивости и согласованность данных. При неправ
Фрагмент 2: [200:450]
и согласованность данных. При неправильном проектировании возникнет дублирование логики и усложнение мониторинга. Оптимальный размер сервиса должен соответствовать бизнес-возможностям.
Почему перекрытие важно:
Допустим, у нас текст:
"...микросервисы требуют тщательного проектирования границ. Неверное определение этих границ...".
Без перекрытия (overlap=0):
- Фрагмент 1: "...микросервисы требуют тщательного проектирования границ. Неверно"
- Фрагмент 2: "е определение этих границ..."
Проблема:
- Слово "Неверно" оторвано от "определение"
- Потерян смысл: "Неверное определение" → превратилось в два бессвязных слова.
- Анализатор (эмбеддинги, NLP-модели) не поймёт связь между фрагментами.
Тот же текст с перекрытием (overlap=50):
- Фрагмент 1: "...проектирования границ. Неверное определение этих..."
- Фрагмент 2: дание этих границ..."
Преимущества:
- Фраза Неверное определение целиком входит в первый фрагмент
- Второй фрагмент содержит определение этих → чёткая связь с первым.
- Итог: ключевые концепции (проектирование границ, их определение) сохранены в обоих фрагментах.
🔐 Ячейка 5: Настройка API и создание эмбеддингов
🎯 Что мы получим после выполнения:
- Подключение к API Nebius Studio
- Готовые эмбеддинги для поиска по смыслу
- Семантическую карту наших знаний
🔑 Шаг 1: Активация доступа к API
Первым делом подключаем наш секретный ключ от Nebius Studio (который мы получили в самом начале):
🧠 Шаг 2: Магия эмбеддингов — что это такое?
Эмбеддинг — это способ превратить текст в математику. Представьте, что у каждого куска текста есть "ДНК" из чисел, который описывает его смысл.
Когда нейросеть читает фразу "Завтра будет дождь", она не просто видит буквы. Она понимает концепции: погода, время, прогноз. И записывает это понимание в виде списка из 3584 (размерность зависит от модели) чисел, например:
[0.23, -0.87, 1.45, 0.02, -0.91, ... еще 3579 чисел]
🔬 Наглядный пример: библиотека знаний
Представим, что мы обрабатываем корпоративную базу знаний IT-компании. У нас есть три документа:
📄 Документ 1 — Техническая инструкция:
"При возникновении ошибки сервера необходимо проверить логи приложения. Откройте терминал и выполните команду tail -f /var/log/app.log для мониторинга событий в реальном времени."
📄 Документ 2 — HR-политика:
"Сотрудник имеет право на компенсацию сверхурочных часов. Заявление подается через внутреннюю систему не позднее 5 рабочих дней после выполнения работ."
📄 Документ 3 — Руководство по отладке:
"Если приложение работает медленно, первым делом проанализируйте системные журналы. Используйте команду grep ERROR /var/log/system.log для поиска критических сообщений."
🧮 Что происходит при создании эмбеддингов:
Для документа 1:
- Нейросеть видит: "ошибка", "сервер", "логи", "терминал", "команда"
- Понимает контекст: техническая диагностика системных проблем
- Создает вектор: [0.89, -0.12, 0.67, -0.34, ...]
Для документа 2:
- Нейросеть видит: "сотрудник", "компенсация", "сверхурочные", "заявление"
- Понимает контекст: HR-процедуры и трудовые вопросы
- Создает вектор: [-0.23, 0.78, -0.91, 0.45, ...]
Для документа 3:
- Нейросеть видит: "приложение", "медленно", "журналы", "grep", "ERROR"
- Понимает контекст: техническая диагностика производительности
- Создает вектор: [0.82, -0.09, 0.71, -0.28, ...]
🎯 Магия семантической близости
Когда мы сравниваем эти векторы:
📊 Сходство между документами:
- Документ 1 ↔ Документ 3: 87% сходства (оба про техническую диагностику)
- Документ 1 ↔ Документ 2: 12% сходства (разные области)
- Документ 2 ↔ Документ 3: 15% сходства (разные области)
🔍 Поиск в действии
Пользователь спрашивает: "Почему система тормозит и как это исправить?"
- Превращение вопроса в вектор:Нейросеть понимает: проблемы с производительностью + поиск решения
Создает вектор вопроса: [0.79, -0.11, 0.69, -0.31, ...] - Поиск ближайших документов:Сравнивает с документом 1: 72% сходства
Сравнивает с документом 2: 8% сходства
Сравнивает с документом 3: 91% сходства ← WINNER! - Результат:Система находит документ 3 как самый релевантный
ChatGPT получает этот контекст и отвечает про анализ логов
Хотя в вопросе не было слов "логи" или "grep"!
🎭 Почему это работает лучше обычного поиска?
Обычный поиск по ключевым словам:
- Вопрос: "система тормозит"
- Найдет: только документы со словами "система" и "тормозит"
- Пропустит: документ 3 (там слова "приложение медленно")
Семантический поиск через эмбеддинги:
- Понимает: "тормозит" = "медленно" = "проблемы с производительностью"
- Находит все релевантные документы, даже с другими словами
- Ищет по смыслу, а не по буквам!
⚡ Шаг 3: Создаем эмбеддинги
🎯 Что такое эмбеддинг-модель?
Эмбеддинг-модель — это специально обученная нейросеть, которая умеет "читать" текст и превращать его в числовые векторы. Это как переводчик с человеческого языка на математический.
Ключевые особенности эмбеддинг-моделей:
🌍 Мультиязычность — понимают разные языки (русский, английский, китайский...)
🧠 Семантическое понимание — улавливают смысл, а не только слова
⚡ Скорость работы — быстро обрабатывают большие объемы текста
🎯 Специализация — оптимизированы для поиска и сравнения текстов
🛠️ Выбор модели в Nebius Studio
В Nebius Studio доступно несколько эмбеддинг-моделей с разными характеристиками:
В примере мы используем bge-multilingual-gemma2 — надежная мультиязычная модель с хорошим балансом характеристик. Но вы можете выбрать любую другую в зависимости от ваших потребностей.
💻 Код для создания эмбеддингов
Пример результат выполнения:
🎉 Получено 725 эмбеддингов
📏 Размерность каждого вектора: 3584
🏆 Итог этого шага:
Мы создали семантическую карту знаний:
- ✅ 725 векторов (по одному на каждый чанк)
- ✅ Каждый вектор кодирует полный смысл фрагмента
- ✅ Готовая основа для поиска по смыслу (а не по ключевым словам)
🔍 Ячейка 6: Семантический поиск по эмбеддингам
🎯 Что мы создаем:
Интеллектуальную систему поиска, которая найдет самые релевантные кусочки текста для любого вопроса пользователя — не по ключевым словам, а по смыслу.
🧮 Косинусное сходство — математика близости
Чтобы сравнить два эмбеддинга (вектора), нам нужна математическая формула. Косинусное сходство — идеальный инструмент для этого:
🎨 Визуальная аналогия косинусного сходства
Представьте два эмбеддинга как стрелки в 3584-мерном пространстве:
- Зеленый (0.89): стрелки смотрят в одну сторону → высокое сходство
- Желтый (0.02): стрелки перпендiculярны → никакой связи
- Красный (-0.31): стрелки в разные стороны → противоположный смысл
🔍 Функция семантического поиска
🎭 Как это работает пошагово:
- Превращаем вопрос в эмбеддинг — используем ту же модель, что и для документов
- Сравниваем с каждым фрагментом — вычисляем косинусное сходство
- Сортируем по релевантности — от самого похожего к наименее похожему
- Возвращаем топ-3 — самые подходящие фрагменты для ответа
🌟 Пример работы:
Вопрос пользователя: "типы взаимодействия микросервисов"
- Создается эмбеддинг вопроса: [0.79, -0.11, 0.69, -0.31, ...]
- Сравнивается с 725 фрагментами документации по микросервисам
- Находятся релевантные фрагменты с высокими баллами сходства:
🔍 Найденные фрагменты:
Возвращаются 3 лучших совпадения для генерации ответа
🎯 Почему это работает:
- Хотя пользователь не использовал точные слова из документа, система нашла разделы про "команды, запросы и события"
- Семантический поиск понял, что "типы взаимодействия" = "стили взаимодействия" = "способы общения микросервисов"
- Даже сокращенный запрос без контекста дал точные результаты!
🤖 Ячейка 7: Формирование ответа через LLM
(Финальный штрих: Превращаем фрагменты в осмысленный ответ)
🎯 Цель ячейки:
Взять найденные в документах фрагменты (из ячейки 6) и сгенерировать на их основе честный, структурированный ответ на вопрос пользователя. Это последний шаг в конвейере RAG: мы даём LLM "открытый учебник" и спрашиваем: "Прочитай и ответь".
🧠 Ключевой компонент: Функция generate_response()
Параметры:
- query: Вопрос пользователя (строка).
- context_chunks: Список релевантных фрагментов текста (в нашем случае top-3).
- model: Выбранная языковая модель. "Qwen/Qwen3-4B-fast"
Что это за модель?
- ✅ Генеративная языковая модель (LLM), а НЕ эмбеддинг-модель!
- 👉 Назначение: Создание связного текста (отчетов, инструкций, ответов на вопросы).
- 👉 Эмбеддинг-модель (из ячейки 5): Превращала текст в числа (text → vector).
- 👉 Эта LLM: Превращает числа/контекст в осмысленный текст (context → ответ).
🔧 Как работает функция: Пошаговый алгоритм
1️⃣ Задание ограничений через системный промпт
system_prompt = "Вы — помощник по работе с текстами. Отвечайте только на основе предоставленного контекста. Если ответа нет — напишите: 'У меня недостаточно информации для ответа.'"
Зачем это нужно:
- 🛡 Блокировка галлюцинаций: Модель не может добавлять информацию "из головы".
- 🎯 Честность: Если в контексте нет ответа — признается в нехватке данных.
- ⚖ Безопасность: Ответы основаны только на предоставленных документах.
2️⃣ Агрегация контекста
Технические детали:
- Разделитель \n\n предотвращает смешение смыслов между фрагментами.
3️⃣ Формирование полного запроса к LLM
Зачем это нужно:
"Упаковываем" данные для модели в понятный формат: сначала дать "информацию", потом задать "вопрос".
4️⃣ Вызов генеративной модели
Зачем это нужно:
Отправляем "собранный конструктор" (правила + данные + вопрос) в языковую модель, чтобы она сгенерировала ответ.
Технические детали (просто):
- model — указываем, какой именно "мозг" будем использовать (в нашем случае Qwen/Qwen3-4B-fast).
- temperature=0 — самое важное! Включаем "режим максимально точного ответа".
→ При temperature=0 модель никогда не фантазирует, а всегда выбирает самый очевидный вариант из текста.
→ Это гарантирует, что на одинаковый вопрос вы получите одинаковый ответ. - messages — список инструкций в строгом порядке:Сначала {"role": "system"} — правила игры ("Отвечай только по контексту!").
Потом {"role": "user"} — ваш вопрос + документ.
📬 Шаг 5: Финальный ответ
🚀 Итоги: Чем ячейка 7 меняет правила игры
1️⃣ Превращает поиск в знание:
Эмбеддинги нашли фрагменты (Ячейка 5–6), а LLM дала экспертный ответ (Ячейка 7).
2️⃣ Гарантирует доверие:
temperature=0 + system_prompt = никакой лжи, только факты из документа.
3️⃣ Экономит часы работы:
Вместо чтения 100 страниц — точный ответ за 10 секунд.
4️⃣ Масштабируется до бесконечности:
Та же инфраструктура сработает для любого вопроса к любым документам!
🎉 Заключение: Ваш путь в мир умных систем
🏆 Что мы построили?
За эти 15 минут вы создали настоящую RAG-систему, которая:
✅ Понимает смысл, а не просто ищет ключевые слова
✅ Работает с вашими данными без дорогостоящего дообучения
✅ Честно признается в незнании вместо выдумывания фактов
✅ Масштабируется от одного PDF до корпоративной базы знаний
Это не просто код — это фундамент для решения реальных бизнес-задач.