Первая реакция любого, кто работает с Pandas и видит пропуски в данных? Правильно, вызвать df.isna().sum(). Получить аккуратную табличку с цифрами, кивнуть и почувствовать себя хозяином положения.
А теперь давайте посмотрим на реальный пример. Никаких стерильных учебных датасетов, к которым все привыкли. У нас в руках данные каротажа по скважинам в Норвежском море — куча геологических измерений для поиска нефти. И как любые реальные данные, они дырявые, как швейцарский сыр.
И вот вы загружаете это, вызываете df.isna().sum() и видите столбик цифр. Но что эти цифры говорят вам на самом деле? Знать, сколько данных пропущено — это как знать вес пациента, не измеряя его температуру, давление и пульс. Это лишь первый, самый поверхностный шаг. Гораздо важнее понять, КАК они пропущены:
- Есть ли в этих пропусках какая-то система?
- Они случайны, как опечатка, или это сигнал о сломанном датчике?
- Если в строке нет значения X, значит ли это, что там не будет и значения Y?
Простой подсчет NaN не ответит ни на один из этих вопросов. А без ответов вы рискуете либо удалить половину ценной информации командой dropna(), либо «замазать» дыры средним значением, исказив все скрытые связи в данных.
Чтобы перейти от слепого подсчета к реальной диагностике, нам нужен инструмент, который превратит сухую таблицу в наглядную карту. И здесь на сцену выходит missingno.
Визуальный аудит: от цифр к инсайтам
missingno — это не просто библиотека для красивых графиков. Это философия визуального аудита данных. Она даёт четыре мощных инструмента, каждый из которых — как отдельный прибор в арсенале диагноста.
Устанавливается стандартно: pip install missingno. А дальше начинается магия.
msno.bar(): Общая температура по больнице
Это, по сути, графический аналог isna().sum(). Он мгновенно показывает, какая доля данных присутствует в каждом столбце.
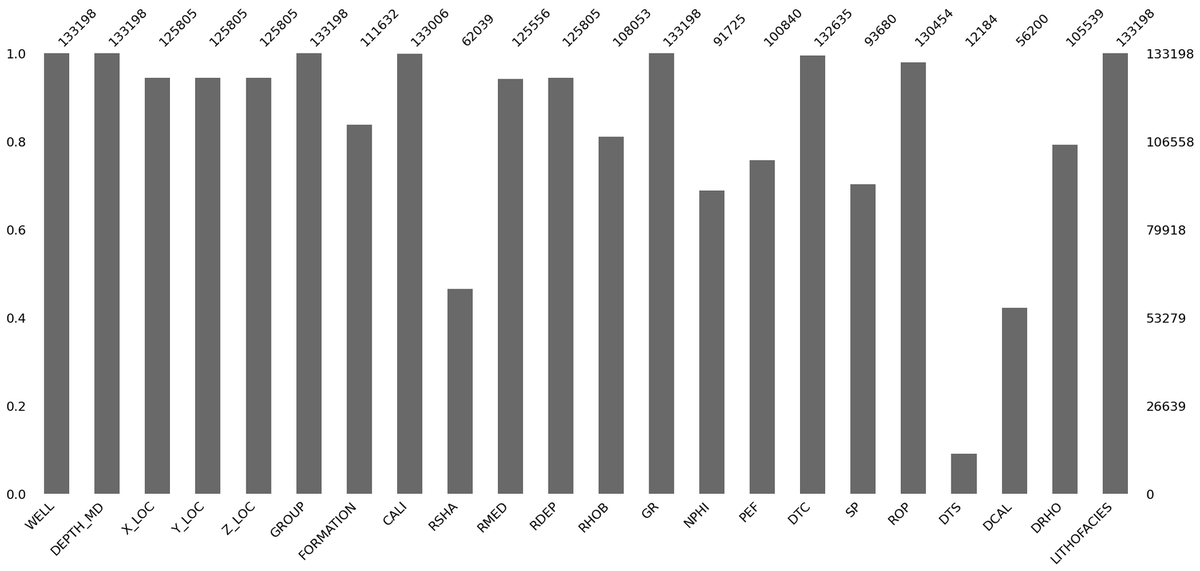
Как его читать:
- Ось Y — полнота данных от 0.0 (пусто) до 1.0 (полностью заполнено).
- Ось X — наши столбцы.
- Цифры сверху — количество НЕпропущенных значений.
Это быстрый, удобный первый шаг. Вы сразу видите аутсайдеров — столбцы, где данных почти нет (привет, DTS и DCAL из примера).
Полезно? Да. Достаточно? Категорически нет. Этот график всё ещё не показывает нам расположение пропусков. Чтобы заглянуть внутрь, нам нужен следующий инструмент.
И вот тут начинается самое интересное...
msno.matrix(): Рентген вашего датафрейма
Матричный график — это, пожалуй, главный и самый мощный инструмент в missingno. Он позволяет буквально заглянуть внутрь датафрейма и увидеть точное расположение каждого пропущенного значения. Это не просто график, это рентгеновский снимок ваших данных.
Как его читать:
- Черные области — это данные, которые у нас есть.
- Белые полосы и точки — это пропуски (NaN).
- Спарклайн справа — гениальная штука. Это мини-график, который показывает «здоровье» данных по строкам. Чем выше линия, тем больше дыр в этом участке датафрейма.
Что мы видим на этом «снимке»?
- Пропуски не случайны. Они образуют огромные белые блоки. Это кричит о том, что данные отсутствуют не точечно, а целыми сегментами. Вероятно, для каких-то скважин или на определенных глубинах эти измерения просто не проводились.
- Есть горячие точки. Спарклайн справа рваный. Это значит, что есть целые группы строк, где данных не хватает катастрофически.
- Визуальная корреляция. Посмотрите на столбцы X_LOC, Y_LOC, Z_LOC и RDEP. Белые горизонтальные «шрамы» в них появляются и исчезают синхронно. Это прямое подтверждение гипотезы: если пропало одно — пропали и остальные.
Матричный график переводит наш анализ с уровня «сколько» на уровень «где и как». Но что если мы хотим измерить эту синхронность численно?
msno.heatmap(): Детектор скрытых связей
Мы уже подозреваем, что пропуски связаны. Тепловая карта создана, чтобы измерить эту связь количественно. Она вычисляет корреляцию отсутствия данных (nullity correlation) между столбцами.
Как её читать:
- Светлые тона (близко к 1): Сильная положительная корреляция. Если значение отсутствует в одном столбце, оно с высокой вероятностью отсутствует и в другом.
- Темные тона (близко к 0): Связи нет. Пропуски в этих столбцах живут своей жизнью.
- Отрицательные значения (редкость): Если в одном пусто, то в другом густо.
Что нам это даёт? Мы видим яркий светлый квадрат в области столбцов RDEP, RMED, X_LOC, Y_LOC, Z_LOC. Они — настоящая банда. Пропадают почти всегда вместе. А вот DTS и RSHA — одиночки. Их проблемы с данными — их личные проблемы, не связанные с другими.
А чтобы увидеть всю иерархию этих связей, есть дендрограмма.
msno.dendrogram(): Генеалогическое древо пропусков
Дендрограмма группирует столбцы с похожими паттернами пропусков. Это как построить генеалогическое древо, где близкие родственники — это столбцы, чьи пропуски ведут себя похоже.
Столбцы, которые объединяются низко (ближе к 0), — ближайшие родственники с почти идентичной структурой пропусков. Чем выше по дереву происходит объединение, тем дальше родство.
Здесь мы снова видим клан «идеальных» (полностью заполненные столбцы, объединенные на уровне 0), клан «геопозиции» (X_LOC, Y_LOC, Z_LOC и другие) и «дальних родственников» вроде DTS, которые ни на кого не похожи.
Так что со всем этим делать?
Библиотека missingno не заполняет пропуски за вас. Она делает нечто более важное — дает вам исчерпывающую информацию для принятия осознанного решения.
Вместо гадания на кофейной гуще у нас есть четкий план действий:
- Столбец DTS: Пропущено >85% данных. Пытаться его лечить — значит, скорее всего, навредить. Вердикт — удалить.
- Кластер X_LOC, Y_LOC, Z_LOC, RDEP: Теряют данные синхронно. Если удалять строки с пропусками, то с учетом всей группы. Удаление строк по X_LOC почти наверняка убьет те же строки для Y_LOC и Z_LOC.
- Столбцы с умеренными пропусками (FORMATION, RHOB и т.д.): Их пропуски не связаны. Значит, для каждого можно подбирать свою, индивидуальную стратегию заполнения (импутации).
Простой вызов df.isna().sum() никогда не дал бы нам такой глубины. Визуальный анализ превращает рутинную проблему в интересный квест, после которого вы знаете о своих данных на порядок больше. А хорошее знание данных — это и есть ключ к сильным моделям.
🔥 Полный пошаговый разбор этого кейса с кодом и всеми графиками я уже оформил в подробную статью. Забирайте в базе знаний на моем сайте, чтобы всегда иметь под рукой.
👉 Пропуски в данных — не приговор: Полное руководство
А обсудить свои кейсы и задать вопросы можно в нашем телеграм-канале. Там материалы, которые не попадают в блог. Подписывайтесь!
👉 PythonTalk в Telegram