VK опубликовала обновлённую модель RuModernBERT с открытым доступом. Она предназначена для обработки русского разговорного языка и работает без подключения к внешним сервисам. Модель может анализировать длинные тексты целиком и выполнять локальную обработку, снижая нагрузку на системы.
Инструмент подходит для задач по работе с текстом — извлечение информации, анализ тональности, поиск и ранжирование. Модель справляется с длинными и сложными запросами. Это позволяет находить точные ответы: документы, видео, товары или другие материалы.
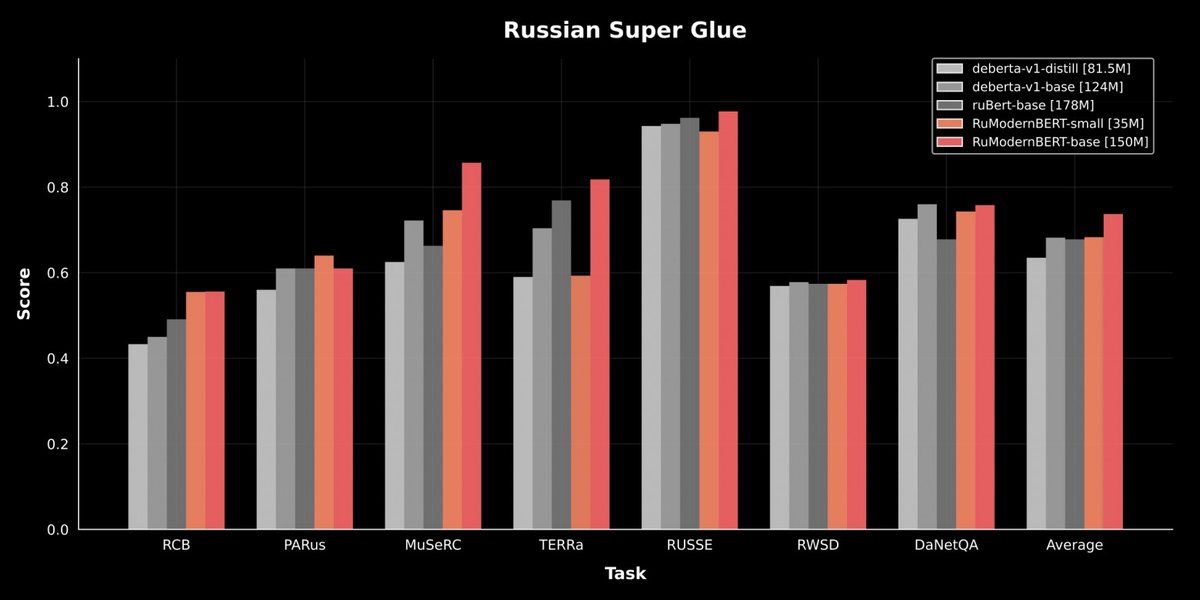
Обучение RuModernBERT проходило на 2 триллионах токенов, включая русский, английский языки и программный код. Поддерживается контекст до 8192 токенов. Источниками данных стали книги, статьи, посты и комментарии, что делает модель пригодной для анализа современной речи, включая разговорную.
Модель доступна в вариантах на 150 и 35 миллионов параметров. Это даёт выбор между более мощной и лёгкой версией в зависимости от задачи. Также представлены улучшенные версии USER и USER2. Они оптимизированы для поиска и группировки данных. USER2 умеет сокращать объём обрабатываемой информации с сохранением точности.
Модель отличается высокой скоростью: обработка длинных текстов в 2–3 раза быстрее, обучение и запуск — на 10–20% эффективнее по сравнению с ModernBERT*. По результатам тестов, RuModernBERT показывает лучшие результаты по пониманию русского языка.
Модель уже внедрена в сервисы VK, которые ежедневно используют миллионы человек. Скачать её можно через платформу Hugging Face.