Всем привет! На моем канале в тг CraftForge я написал пост о том, что каждый может написать парсер и без глубоких знаний в программировании, просто не все хотят тратить на это время. Дальше решил проверить сколько нужно потратить времени, чтобы получить приемлемый результат, а после голосования выбор пал на площадку Озон. Давайте попробуем. Используем ИИ, чтобы получить готовый парсер в котором мы указываем ссылку на категорию товара и количество товара нужного нам. Вернуть должен в формате json ссылку на товар, название товара, цену со скидкой и без, рейтинг и количество отзывов.
Обращаюсь к ChatGPT с запросом:
“Привет, помоги мне написать парсер для маркетплейса Ozon, в конфиге указывается ссылка на категорию и количество товара, нужно получить ссылку на товар, название, цену со скидкой, цену без скидки, рейтинг и количество отзывов, используй python, предусмотри способы обхода блокировки парсеров и прокрутку страницы, чтобы получать больше карточек товара, давай добавим логирование, чтобы отлавливать ошибки и сохранять полученные данные будем в файл JSON”
Он нам говорить про структуру файлов:
config.ini
[ozon]
category_url = https://www.ozon.ru/category/noutbuki-15600/
product_limit = 50
requirements.txt
selenium
webdriver-manager
и сам код:
import time
import json
import logging
import configparser
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
# Настройка логирования
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] %(message)s",
handlers=[
logging.FileHandler("parser.log", mode='w', encoding='utf-8'),
logging.StreamHandler()
]
)
config = configparser.ConfigParser()
config.read("config.ini")
CATEGORY_URL = config["ozon"]["category_url"]
PRODUCT_LIMIT = int(config["ozon"]["product_limit"])
def get_driver():
chrome_options = Options()
chrome_options.add_argument("--headless=new")
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--window-size=1920,1080")
chrome_options.add_argument("--lang=ru-RU")
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
chrome_options.add_experimental_option("useAutomationExtension", False)
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
return driver
def scroll_to_load(driver, limit):
SCROLL_PAUSE_TIME = 1.5
loaded = 0
last_height = driver.execute_script("return document.body.scrollHeight")
while loaded < limit:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
products = driver.find_elements(By.CSS_SELECTOR, "a.tile-hover-target")
loaded = len(products)
logging.info(f"Загружено товаров: {loaded}")
def parse_products(driver, limit):
results = []
product_cards = driver.find_elements(By.CSS_SELECTOR, "div[data-widget='searchResultsV2'] div[class*='tile']")
logging.info(f"Найдено карточек: {len(product_cards)}")
for i, card in enumerate(product_cards):
try:
link_tag = card.find_element(By.CSS_SELECTOR, "a.tile-hover-target")
link = link_tag.get_attribute("href")
name = card.find_element(By.CSS_SELECTOR, "span.tsBody500Medium").text.strip()
try:
price_discount = card.find_element(By.CSS_SELECTOR, "span.tsHeadline500Medium").text
price_discount = price_discount.replace("\u2009", "").replace("₽", "")
except Exception:
price_discount = ""
try:
price_old = card.find_element(By.CSS_SELECTOR, "span.tsBody400Strike").text
price_old = price_old.replace("\u2009", "").replace("₽", "")
except Exception:
price_old = ""
try:
rating = card.find_element(By.CSS_SELECTOR, "div.ui-rating__rating").text
except Exception:
rating = ""
try:
reviews = card.find_element(By.CSS_SELECTOR, "div.ui-rating__reviews").text
reviews = reviews.replace("(", "").replace(")", "")
except Exception:
reviews = ""
product = {
"link": link,
"name": name,
"price_discount": price_discount,
"price_old": price_old,
"rating": rating,
"reviews": reviews,
}
logging.info(f"[{i+1}] Собрано: {name[:40]}...")
results.append(product)
if len(results) >= limit:
break
except Exception as e:
logging.warning(f"Ошибка при обработке карточки: {e}")
continue
return results
def main():
logging.info("Запуск парсера Ozon")
try:
driver = get_driver()
logging.info("Открываю категорию...")
driver.get(CATEGORY_URL)
time.sleep(3)
logging.info("Прокручиваю страницу...")
scroll_to_load(driver, PRODUCT_LIMIT)
logging.info("Собираю карточки...")
products = parse_products(driver, PRODUCT_LIMIT)
driver.quit()
logging.info(f"Получено {len(products)} товаров.")
with open("results.json", "w", encoding="utf-8") as f:
json.dump(products, f, ensure_ascii=False, indent=2)
logging.info("Результаты сохранены в results.json")
except Exception as e:
logging.error(f"Критическая ошибка: {e}")
if __name__ == "__main__":
main()
Копируем в VSCode, редактируем конфиг:
category_url = https://www.ozon.ru/category/noutbuki-15692/
product_limit = 5
запускаем… и ничего нет(
Начинаем разбираться…
код запускается, принты пишутся, но результата нет, а нет его, потому что он ищет не те теги, теперь включаемся мы. Шаблон он нам дал, нужно определить правильные теги и искать уже по ним.
Открываем ссылку выбираем нужную карточку и нажимаем «Посмотреть код»
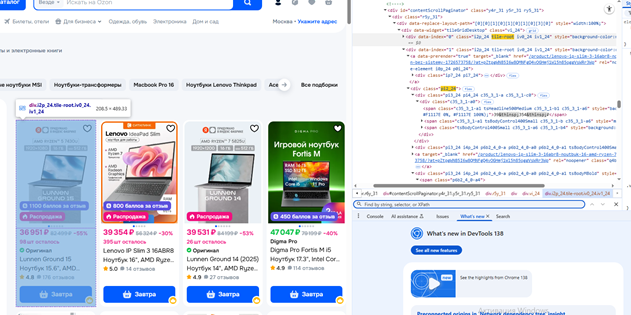
Видим что карточка идет в теге div с классом “tile-root”, а gpt ищет div[data-widget='searchResultsV2'] div[class*='tile'], сложно и ненужно, заменяем на (By.CLASS_NAME, "tile-root")
Смотрим дальше...
Ссылку он ищет вот так: (By.CSS_SELECTOR, "a.tile-hover-target")
Заменяем на (By.CSS_SELECTOR, "a")
Название и цену он сделал нормально
Для названия – "span.tsBody500Medium"
Для цены - "span.tsHeadline500Medium"
А вот цена без скидки он ищет через "span.tsBody400Strike"
А на самом деле "span.tsBodyControl400Small"

Рейтинг и отзывы он ищет через "div.ui-rating__rating" и "div.ui-rating__reviews", что естественно не так
Ищем сами и получаем - div.tsBodyMBold ,в котором есть span`ы с значениями рейтинга и отзывов
Редактируем:
spans = card.find_element(By.CSS_SELECTOR, "div.tsBodyMBold").find_elements(By.TAG_NAME, "span"))
rating = spans[0].text
reviews = spans[3].text
Запускаем и получаем адекватный результат
[
{
"link": "https://www.ozon.ru/product/lunnen-ground-15-noutbuk-15-6-amd-ryzen-5-7430u-ram-16-gb-ssd-512-gb-amd-radeon-graphics-2134285447/?at=WPtN1KjYztKk31xjHMNqw33TY2p7z5i1G1MOXF28KMnv",
"name": "Lunnen Ground 15 Ноутбук 15.6\", AMD Ryzen 5 7430U, RAM 16 ГБ, SSD 512 ГБ, AMD Radeon Graphics, Windows Home, (LL5FAWL03), голубой, Русская раскладка",
"price_discount": "36951",
"price_old": "82499",
"rating": "4.8",
"reviews": "176 отзывов"
},
...
Дальше можно дорабатывать как угодно, искать другие значения, бороться с защитой и ускорять обработку, но это уже другая история.
Из проделанной работы могу сделать вывод:
ИИ создает отличную основу - 90% кода уже рабочие
Но без человека не обойтись - в моем случае потребовалось только поправить теги, но в других ситуациях могут быть:
- Антибот-системы
- Динамическая подгрузка данных
- Капчи
Цель была не в идеальном парсере, а в проверке:
Время от запроса до рабочего кода: ~20 минут (с учетом правок)
Уровень навыков: минимальный (достаточно понимать структуру HTML)
Можно углубляться:
- Добавить обработку разных вариантов верстки
- Настроить обход защиты
- Сделать сохранение в Excel
Но главное - ИИ действительно сокращает путь от идеи до результата в разы.
P.S. ChatGPT кстати не заточен под программирование, есть куда более специализированные нейронки