
Команда из лаборатории T-Bank AI Research представила метод, позволяющий не только наблюдать за тем, как работает большая языковая модель (LLM), но и управлять её «мышлением» — без дополнительного обучения и изменения архитектуры. Свои разработки они представили на Международной конференции ICML 2025 в Канаде. По словам авторов, это большой шаг в сторону более прозрачного и безопасного искусственного интеллекта.
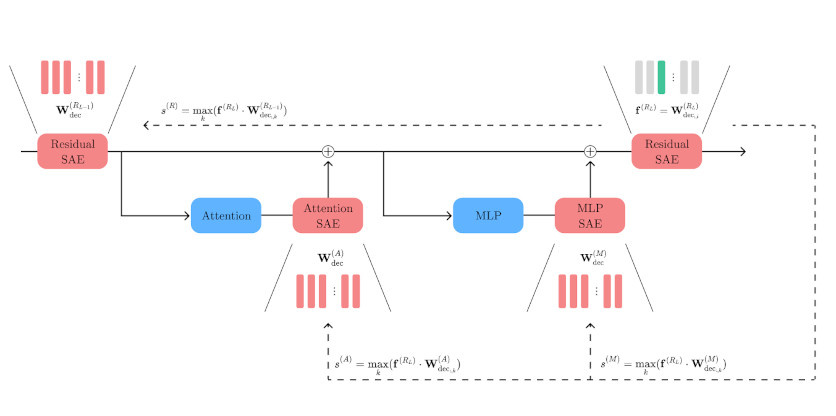
Новый метод, получивший название SAE Match, позволяет отслеживать, как внутри модели появляются, меняются или исчезают смысловые признаки — например, определённый стиль, тема или тон. Исследователи разработали своего рода «карту смыслов» внутри нейросети, которая показывает, как информация проходит через разные модули модели.
Раньше такие методы служили лишь для наблюдения — то есть учёные могли понять, почему модель сгенерировала тот или иной ответ. Теперь они могут точечно менять поведение ИИ — усиливая или подавляя нужные признаки в процессе генерации текста. Это значит, что можно управлять, например, стилем или темой текста, не переписывая всю модель и не обучая её заново. Такой подход особенно полезен в задачах безопасности, когда нужно заранее исключить нежелательные темы в диалоге с чат-ботом.
Исследователи доказали, что вмешательство на нескольких уровнях — одновременно в разных частях модели — даёт куда более точные результаты, чем изменения в одном месте. И при этом не ухудшает качество текста. Ещё один плюс: этот метод подходит для уже обученных моделей, не требует дополнительных данных и доступен даже небольшим исследовательским группам, что делает открытие особенно ценным.
Фактически теперь разработчики могут не только наблюдать за тем, как «думает» ИИ, но и управлять этим процессом. Это открывает путь к более предсказуемому и этичному искусственному интеллекту.