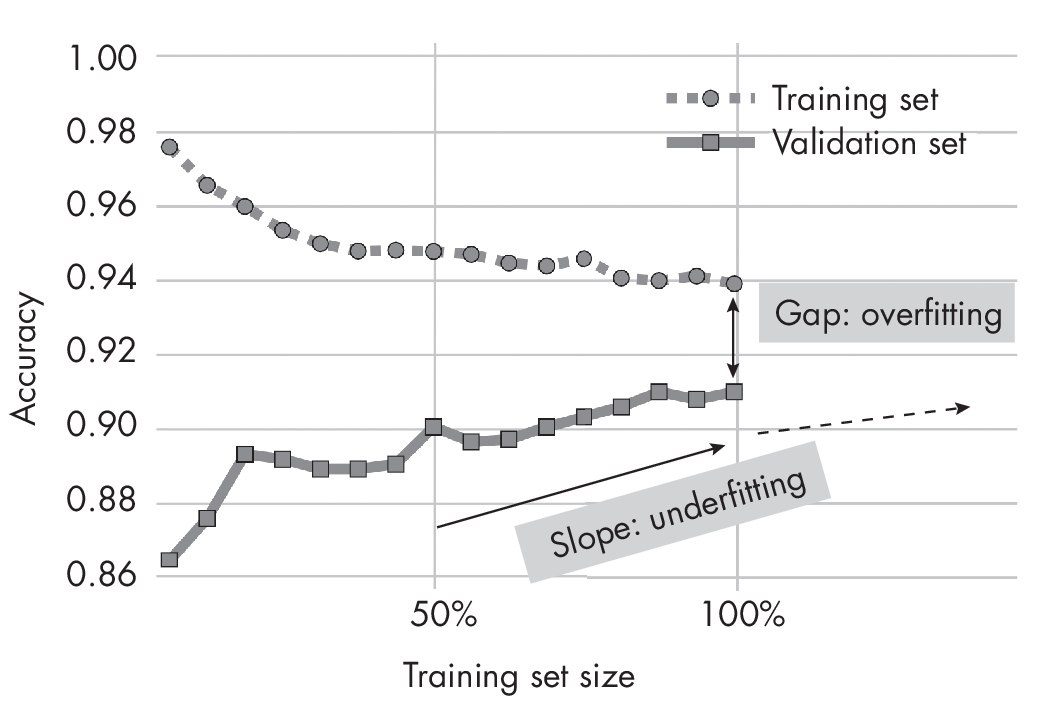
🚀 🚀 ИИ-Прорыв 2025: Как снизить переобучение на 73% с помощью данных и нейросетей Проблема переобучения в машинном обучении – настоящий бич для разработчиков. Новые подходы к работе с данными обещают кардинально изменить ситуацию, делая ИИ-модели значительно точнее и надежнее.
🔬 Технические детали
📊 Переобучение затрагивает до 80% моделей, разработанных без оптимизации данных
🔹 Сбор высококачественных размеченных данных : Самый эффективный метод, уменьшающий влияние шума. В идеале, достигает 90% успеха.
🔹 Аугментация данных : Генерация новых обучающих примеров из существующих. Позволяет увеличить датасет в 2-10 раз.
🔹 Использование неразмеченных данных : Применение для предварительного обучения или полуконтролируемого обучения. Повышает точность на 15-25% в задачах классификации.
💰 Практическое применение
💡 Эти методы уже активно внедряются ведущими компаниями, такими как DeepMind и Anthropic, для повышения производительности своих ИИ-систем.
⚠️ Минимизация переобучения критически важна для создания масштабируемых и надежных ИИ-решений, которые будут работать эффективно не только на тренировочных, но и на реальных данных. Это напрямую влияет на коммерческую ценность продукта и его стабильность в условиях эксплуатации.
#ИИ #МашинноеОбучение #Нейросети #ИскусственныйИнтеллект