В мире искусственного интеллекта большие языковые модели (LLM) уже давно вышли за пределы простого решения задач и написания текстов. Сегодня перед ними стоит новый вызов: смогут ли они стать реальными помощниками для инженеров на стройке, а не только «виртуальными экспертами»? Ответ на этот вопрос начала искать команда исследователей из Канады и США, представив первую в мире масштабную систему оценки инженерных навыков ИИ — DrafterBench.
Зачем нужен DrafterBench?
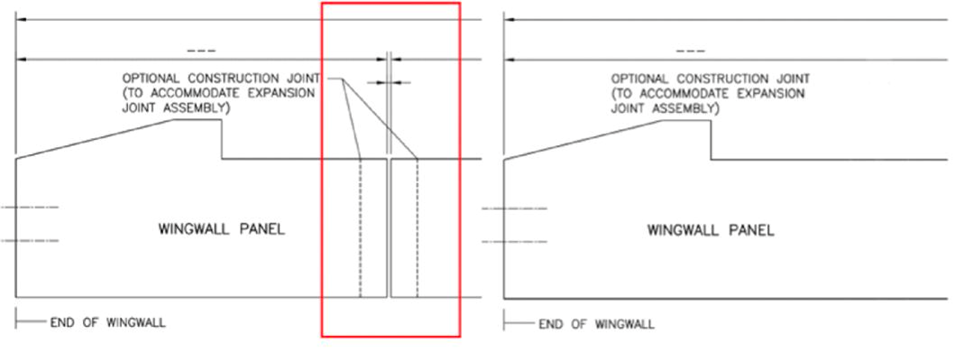
В строительстве и архитектуре одна из самых рутинных и трудоёмких задач — внесение изменений в инженерные чертежи. Ежедневно тысячи инженеров и чертёжников корректируют детали: сдвигают балки, увеличивают диаметр труб, добавляют подписи к элементам. Эти задачи требуют внимательности, точности и умения следовать сложным инструкциям, но не всегда высокой квалификации. Автоматизация здесь особенно востребована.
DrafterBench — это первый масштабный бенчмарк, который позволяет проверить, насколько современные LLM способны понимать инженерные задания, вычленять детали, выстраивать цепочки инструментов и критически оценивать корректность своих действий.
Как работает DrafterBench?
В основе DrafterBench — 1920 реальных задач по внесению изменений в чертежи, собранных из 20 проектов и охватывающих 12 типов команд. Модели должны не просто «угадать» ответ, а выполнить серию действий: понять задание, выбрать и правильно вызвать нужные инструменты, корректно передать параметры и выполнить все пункты инструкции.
Оценка идёт по четырём ключевым направлениям:
- Понимание структурированных данных: может ли модель выделить из разных формулировок задания все важные детали?
- Управление инструментами: умеет ли ИИ выстраивать цепочку действий, правильно комбинировать и вызывать инструменты?
- Следование инструкциям: способна ли модель выполнить длинную команду без пропусков и ошибок?
- Критическое мышление: может ли ИИ заметить неясности, противоречия или пробелы в задании и корректно их обработать?
Для прозрачности оценки разработана система «двойных инструментов»: вместо реального изменения чертежа модель формирует структурированный отчёт в формате JSON, где фиксируются все шаги, параметры и переменные. Это позволяет точно понять, где и почему модель ошиблась.
Каковы результаты?
В тестировании участвовали ведущие модели: OpenAI GPT-4o/o1, Claude 3.5 Sonnet, Deepseek-V3-685B, Qwen2.5-72B-Instruct, LLaMA3-70B-Instruct. Все они показали неплохие результаты на простых задачах (средний балл — выше 65 из 100), а лидером стал OpenAI o1 (79,9 балла). Однако до реальных требований стройплощадки им ещё далеко.
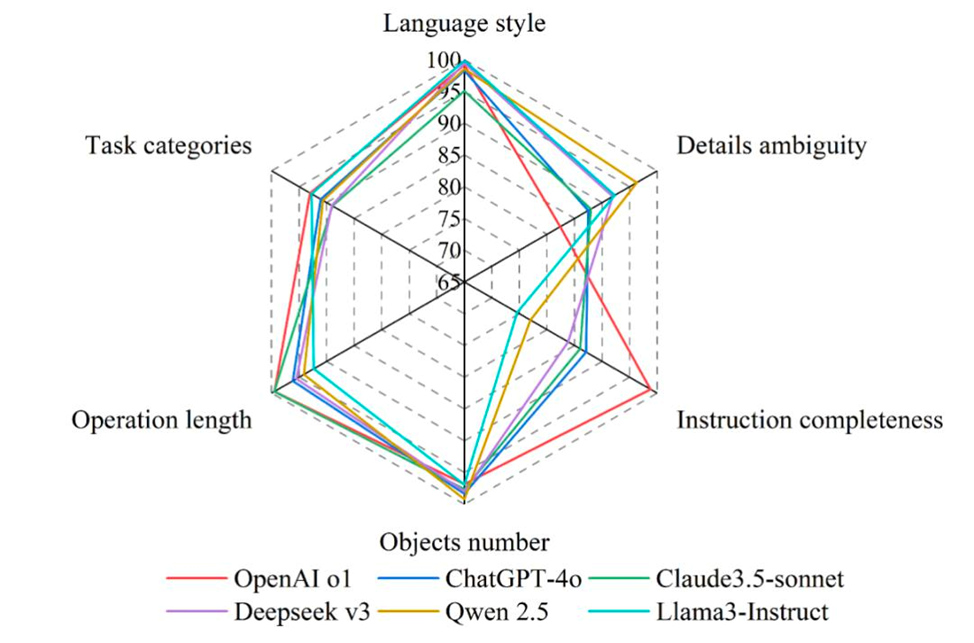
Самые частые ошибки — неясные параметры, сбои в передаче переменных, неправильная последовательность вызова инструментов, путаница в логике. Даже если большая часть шагов выполнена верно, одна ошибка в цепочке приводит к провалу всей задачи. В итоге, хотя точность отдельных действий достигает 60%, полностью корректно выполненных заданий — лишь около 40%.
Почему это важно?
DrafterBench впервые позволяет оценить не просто «умеет ли» ИИ работать с инженерными задачами, а «насколько хорошо» он это делает. Для реального внедрения в строительстве и проектировании нужны не только умные, но и надёжные, устойчивые к ошибкам цифровые помощники.
Исследователи планируют расширять бенчмарк: добавить задачи по проверке чертежей, контролю соответствия стандартам, автоматизации ведения строительных журналов. Это поможет сделать LLM действительно полезными для инженеров и проектировщиков.
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru