
Как обеспечить надёжность ваших данных? Узнайте о лучших практиках проектирования схем данных и автоматизации бизнес-процессов!
Data structures: проектируем надёжную схему данных
Строить схемы хранения данных — всё равно что возводить крепость на века. Ошибёшься на старте – не обрадуешься позже ни при какой погоде. Мир цифровых технологий изобилует острыми углами, и одна из самых коварных ловушек – небрежное, с плеча спроектированное хранение данных. Наш сегодняшний гайд посвящён тому, как проектировать действительно надёжные и эффективные схемы данных, с учётом лучших практик, требований бизнеса, тонкостей алгоритмов, да ещё и со щепоткой русской души.
Для кого и зачем нужна схема данных
Схема данных — это формальный план того, как информация живёт внутри приложения или системы. Главная цель — эффективно, надёжно и структурированно хранить, извлекать, изменять и удалять данные. Даже если вы разрабатываете небольшой сервис или мобильное приложение, грамотная схема данных помогает:
- избегать дублирования и ошибок;
- обеспечивать целостность и точность данных;
- ускорять работу с данными и поддерживать масштабирование;
- упрощать сопровождение, развитие и интеграцию с другими сервисами.
Иными словами, схема данных – это фундамент, на котором будет построен весь цифровой дом. А мы ведь знаем: "Без фундамента и дом не дом".
Крупные кейсы: когда автоматизация меняет правила игры
Пирожочки, реальность такова: даже самые бодрые маркетинговые отделы компаний не всегда добиваются приличного интернет-трафика. Но что если я скажу, что всё это можно поставить на поток с помощью автоматизации — и не вбухать ни рубля? Вот наглядные картинки того, как это работает.
Website traffic, созданный целиком автоматизированными инструментами:
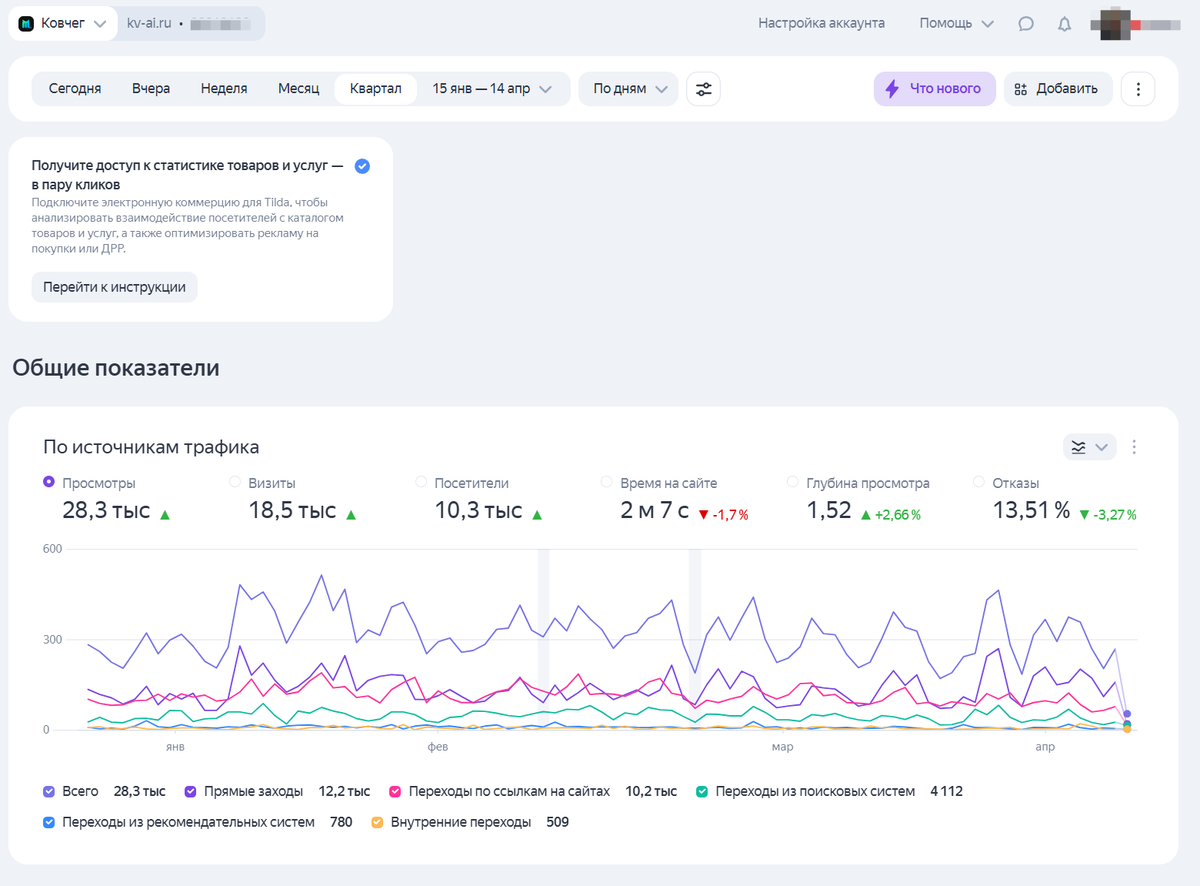
График роста посещаемости сайта благодаря полному циклу автоматизации — ноль затрат на рекламу. Бизнес результат доступен даже без команды маркетологов.
ДЗЕН-трафик: вся лента — на автомате:
Публикации пестрят охватами — всё сгенерировано скриптами и нейросетями, человек палец о палец не ударил. Так растят каналы новой волны.
Всё это стало возможным благодаря платформам автоматизации, нейросетям и грамотной работе с данными. Если хочется лично повторить путь — регистрируйтесь на Make.com (инструмент гиперавтоматизации). Там всё это становится рутиной, а не героизмом.
Популярные типы структур данных и где они нужны
Структуры данных — как набор инструментов в мастерской: выбирайте подходящее — не промахнётесь. Табличка для памяти, для чего какие структуры нужны:
Структура Где применяется Преимущества Массивы Простой список, где важен быстрый доступ Быстро читать по индексу Стеки История действий; отмена; парсеры LIFO (last-in, first-out); просто управлять Очереди Планировщики задач; обработка событий FIFO (first-in, first-out) Связные списки Динамические данные, частые вставки/удаления Нет фиксированного размера, легко вставлять Деревья Иерархии, каталоги, файлы Идеальны для поиска и сортировки Поисковые деревья БД, карта сайта, быстрый поиск Быстрый поиск, сортировка Графы Социальные сети, маршруты Анализ сложных отношений Хэш-таблицы Кеши, словари, быстрый доступ Быстрый поиск по ключу Trie (Префиксные деревья) Поиск слов, автодополнение Эффективное хранение больших словарей
Каждая структура — оптимальный ответ на свой класс задач. Например, когда мне нужно быстро перелопачивать миллионы товаров, я беру не гигантский массив, а дерево поиска — экономия времени, даже кофе остыть не успеет.
Классика жанра: этапы проектирования схемы данных
Проектировать схему данных — всё равно что планировать стройку: без поэтапного движения потом всё рассыплется.
1. Анализ требований
С этого начинается всё: изучаем кто, как и зачем будет пользоваться системой, прописываем все бизнес-процессы, не пропуская мелочей. Кто-то скажет: "Подумаешь, детали!" А ведь в деталях кроется светлое будущее всей разработки.
2. Концептуальная модель
Отбрасываем детали хранения, смотрим на сущности с высоты птичьего полёта. Строим ER-диаграммы — рисуем кружочки и квадраты, соединяем стрелочками. Главное, чтобы в голове щёлкнуло: кто с кем и почему.
3. Логическая модель
Углубляемся: добавляем атрибуты, определяем ключи, нормализуем структуру (никаких двойных записей, никаких лишних полей). Привязываемся к реляционным или NoSQL решениям. Именно тут можно решить, использовать ли привычные таблицы или прыгнуть в графовую БД.
4. Физическое проектирование
Пора раскладывать сущности по таблицам, создавать индексы, задавать ограничения целостности. Вот тут возникает самая нервная работа: все хотят скорость, все нервничают за безопасность и стабильность.
5. Реализация и тестирование
Здесь решение становится ощутимым. Данные начинают ходить по системе, схемы проходят краш-тест производительностью. А если что-то заглючило, рукава закатываются — и снова миграции, оптимизации, рефакторинги.
Пирожочки, никогда не ведитесь на простоту процесса — за каждой красивой диаграммой стоит тонна нервной работы.
Лучшие практики проектирования схем данных
Простота
Меньше сложностей — меньше ошибок. Когда последние картинки структуры понятны новичку — вот тогда вы близки к успеху. Все эти "магические объекты" и "волшебные поля" — зло для поддержки.
Гибкость
Бизнес оживает — и ваши данные должны быть готовы к переменам. Меняли маркетинговую стратегию? Готовьтесь к новым сущностям, к новым связям, к миграциям.
Документирование
Лично я без подробной документации схему не запускаю. Пусть даже в самом общем виде: почему эта таблица тут, кто её использует, зачем столько внешних ключей. Верните себя в прошлое через пару месяцев — вот кто оценит вашу дотошность.
Производительность
Огромный массив данных — всегда потенциальная головная боль. Индексы на горячих полях, регулярная оптимизация запросов — спасают от микролагов и масштабных простоев.
Безопасность и целостность
Каждый внешний ключ — это щит. Каждое ограничение — броня. Защищайте данные не только от дурака, но и от ошибок непредсказуемых скриптов и багов.
Избыточность — враг
Копирование одних и тех же данных в разных таблицах только ради “быстрого доступа” — ловушка. Лучше потратить день на продуманную нормализацию, чем месяцы на вылавливание рассинхрона.
Итерации — закон жизни
Невозможно составить “вечную” схему. Всё будет меняться: клиенты капризничают, интеграции растут, рынок закручивает гайки. Не жмите на тормоза — меняйтесь легко.
Видео для вдохновения
Как оптимизировать и автоматизировать бизнес-процессы / Кейс Make.com — На экране показывают живую автоматизацию типичного офиса. Не “теория”, а прямо рабочие скрипты для Make.com и других платформ, которые дают такой трафик, как на скриншотах выше.
Кулинарная метафора: выбор структуры — как выбор посуды
Русская кухня славится посудой под свои шедевры: чугунок для каши, самовар для чая, горшок для мясного — и в данных тот же подход. Выберешь не ту структуру — либо пригорит, либо пересохнет.
- Нужно хранить сотни однотипных строк? Массив или хеш-таблица.
- Есть родитель-дитя? Дерево.
- Блиц-поиск по уникальному ключу? Хеш-таблица.
- Полная прозрачность и взаимосвязи? Граф, иначе строй не продержится.
Этот образ навсегда закрепился у меня в голове после работы с системой логистики — выбрали массивы вместо связей, а потом пользователи добивались “родословных” по товарам неделями. После переделки на граф — всё облетело, как по маслу.
Типовые ошибки и как их избежать — проверено кровью и потом
Нет анализа процессов
“Мы же итак знаем, что надо!” — И потом переделывать годовую схему, потому что выяснилось: процесс на деле сложнее, чем думали.
Чума дублирования
Сказали “на всякий случай скопировать” — и спустя месяц устроили парад рассинхрона, когда email клиента везде разный.
Плевать на индексы
Улыбаются все — пока таблица маленькая. Потом приходят запросы на минуту, админы в панике, бизнес теряет деньги.
Типы вперемешку
Телефон или email в одном поле потому что “так быстрее”? Вспомните об этом в дальнейших интеграциях и аналитике — придётся потом вылавливать “иголки в стоге сена”.
Выбор структуры “по привычке”
Всегда использовали реляционную БД? Не значит, что и для big data, и статейников это лучший путь. Один мой знакомый всю СРМ на NoSQL построил, и теперь вспоминает с содроганием — пришлось заново строить логику для простых операций поиска.
Горячие тренды и инструменты по работе с данными
- ER-диаграммы: Как котлован для фундамента — всё хорошо пока стройка под контролем. Используйте dbdiagram.io, Draw.io, российские корпоративные системы моделирования — и всегда визуализируйте структуру на этапе обсуждений.
- Автоматизация миграций: Без неё — как без сварочного аппарата на стройке, всё врозь. Рекомендую посмотреть на Liquibase или Flyway, если цените своё время и нервы команды.
- Интеграция с BI: Ни одна аналитика не полетит, если схема кривая. Когда строите отчёты по десяткам сущностей — только хорошая архитектура спасёт от вечных “где взять эти данные”.
Золотые правила (по-русски), проверенные практикой
- “Семь раз отмерь — один отрежь”: лучше неделя на обсуждение, чем год потом на переделки.
- “Береги честь смолоду, а структуру — на старте!”: любые изменения в корне схемы через год будут дорого стоить.
- “Тише едешь — дальше будешь”: не гнаться за последними технологиями, если задачи штатные.
- “Любишь кататься — люби и на схему смотреть”: ревью, дебаты, коллективная проработка схемы уберегут от одиночных ошибок.
SEO-ключевые слова: органичное внедрение для Яндекс и Google
Пирожочки, если вас волнует вопрос эффективности хранения данных, запишите — структуры данных, проектирование базы данных, схема данных, бизнес-процессы, эффективность хранения данных, индексация, нормализация, концептуальная модель, логическая модель, физическое проектирование, оптимизация производительности, лучшие практики проектирования, визуализация ER-диаграмм, целостность данных, масштабируемость, архитектура данных, инструменты проектирования, документация схемы, безопасность данных, автоматизация миграций, аналитика данных. Все эти ключи — не украшение, а сугубая необходимость современных систем, если вы цените место в поисковой выдаче.
Где учиться новому
Если тема вам близка и зацепила — рекомендую подписаться на канал о нейросетях, автоматизации бизнес-процессов и платформе Make. Там публикуют схемы, кейсы, новости — и курс по тому, как самому собрать бизнес на гиперавтоматизации данных.
Make.com — регистрация на платформе гиперавтоматизации
Хотите научиться автоматизации рабочих процессов с помощью сервиса make.com и нейросетей ? Подпишитесь на наш Telegram-канал
Тактика внедрения: схемы данных как инструмент автоматизации
Автоматизация процессов невозможна без четкой и выверенной архитектуры данных. Каждый ваш скрипт, интеграция или парсер питается данными, как плотоядный зверёк, — дашь не ту структуру, и результаты будут повергающими в уныние. Пирожочки, когда вы ставите во главу угла структуры данных и правильное проектирование базы данных, ваши бизнес-процессы перестают буксовать.
Тут выигрывает не самый "технологичный", а самый системный архитектор. Когда вы на старте задали грамотную схему, последующая автоматизация собирается, словно конструктор: Make, Zapier, любые трубы данных проглатывают потоки без неожиданных падений.
Реальный кейс из жизни
Мне довелось внедрять автоматизацию для бизнеса, где команда мечтала о ночных продажах. До этого их база напоминала московские пробки: данные смешаны, трафик подвисает. Проект стартовал с простого: разобрали сущности по полочкам, жёстко назначили ключи, отрезали всю “вату”. Итог: за первую неделю автоматизированного трафика через Make.com люди собрали больше входящих заявок, чем отдел продаж за весь сезон.
Пошаговая схема построения современной архитектуры данных
1. Определите границы и сущности
Выпишите каждую сущность, исходя из бизнес-логики. Важна конкретика: не «товар вообще», а конкретные параметры и взаимодействия.
2. Разложите взаимосвязи
Используйте ER-диаграммы — визуально, просто, со стрелочками. Рисуйте, как в школе на доске: кто с кем, кто от кого зависит, кто кого ограничивает или поддерживает. Это ваш будущий навигатор для автоматизации.
3. Примените нормализацию
Снимите все излишества — лишние поля, дубли, типовые ловушки вроде «столбец Х иногда пустует». Пусть каждая таблица выполняет только свою роль.
4. Запланируйте индексацию под нагрузку
Предполагайте реальные кейсы: что если ваша публикация станет виральной или количество пользователей удвоится за месяц? Заложите индексы на горячие поля, чтобы не словить ступор.
5. Документируйте и ревьюйте
Проще договориться на берегу, чем чинить утонувшую схему. Документация — ваш спасательный круг. Всегда понимайте, кто за какие данные отвечает, что где лежит и зачем.
Инструменты и техно-рутину переводим в автопилот
Сейчас нет времени вручную латать таблицы и пересобирать отчёты. Новый стандарт — автоматические миграции, интеграции, визуальная сборка пайплайнов. Всё это для тех, кто ставит архитектуру на первое место.
Универсальные решения сегодня:
- dbdiagram.io или Draw.io — чтобы описывать структуру рабочей базы словами и схемами.
- Liquibase и Flyway — автоматизация внедрения изменений каждой новой версии схемы.
- BI-платформы и аналитика — перестаёте носиться между сводными таблицами, а строите единую экосистему данных.
Для новичков и практиков шикарный вход — серия разборов на одном из лучших каналов по автоматизации работы и бизнес-процессов с нейросетями и платформой Make. Смотрите: Make.com для начинающих: первые автоматизации | Второе занятие.
Автоматизация и связь с внешними нейросетями
Мир быстро идёт в сторону "no code". Уже не нужно быть спецом по сетевым протоколам — главное, чтобы схема данных давала постраничный, детализированный, безопасный доступ. Тот же Make.com воспринимает любые ваши таблицы и списки как единый язык, если структура продумана.
Когда задача — автоматизировать генерацию изображений для карточек товара, подключите SORA API, а структуру дайте чёткую: ссылку на товар, параметры генерации, метаданные результата. Цепочка сборки сразу станет очевиднее: видео SORA API, автоматизация создания изображений, баннеров, карточек товаров и прочего через make.com раскрывает похожие практические схемы.
Что обязательно учесть архитектору схемы
1. Валидируйте входящие данные
Не полагайтесь на "чистоту" данных на входе — стройте стену из валидаций. Пропускайте только то, что соответствует назначенному типу.
2. Постоянно ручайтесь за целостность
Формируйте механизмы отката, создавайте историю изменений — это спасение и для легального аудита, и для внутреннего спокойствия.
3. Думаете про масштаб сейчас, а не в будущем
Если вы уже на старте разделили схему на куски (например, отдельные таблицы для больших сущностей или архивные "лоджики"), то сохраните себе месяцы на переезд.
4. Автоматизируйте миграции
Это защита от неожиданного коллапса после внедрения новых фич.
Практика реальных интеграций
Пирожочки, расскажу, как автоматизация стала дыханием для интернет-магазина. На вход: база товаров, клиентов, заказов — всё как у всех, только связи прописаны явно (кто, когда, где купил, статусы, логистические метаданные). Подключили Make.com и начали автогенерировать картинки и баннеры новых товаров, постить их в Telegram, VK, Дзен — каждый шаг автоматизирован.
Возьмите пример с видео Полная автоматизация Дзен: От идеи до публикации за 5 минут с Make.com, ChatGPT и Midjourney — там всё от схемы до пайплайна, никаких "магических" ручных шагов. Такая реализация невозможна, если ваш фундамент (схема данных) — кривая и рыхлая.
Автоматизация рабочих и бизнес-процессов: куда двигаться дальше
Доходит до тонкостей: только те, кто заранее продумал архитектуру, могут в любой момент внедрять новые источники данных, машинное обучение, или даже автогенерацию лидов с разных площадок. Как там говорят — “место силы” каждого проекта скрыто в его фундаменте.
Вы уже можете:
- По одному клику запускать автозаполнение карточек товаров изображениями или seo-описаниями.
- Мгновенно собирать отклик с соцсетей, пушить статусы заказов клиентам, рассылать уведомления.
- Подключать любые современные решения: от Telegram-ботов до генерации обложек и видео для Дзен — примеров хватает на год вперёд.
Смотрите, как это реализуется на практике:
Генерация 1000 лидов без вложений: ChatGPT и Make для любого бизнеса
Полная автоматизация блога: SEO-контент на автопилоте с Make.com, Perplexity, ChatGPT и WordPress
От спама до продаж: Как создать идеального нейросетевого Telegram-админа на Make.com
Держим всё под контролем: рекомендации для архитектора
- Таблицы — всегда только под задачи. Добавили новый сервис — добавьте нужную сущность, но не смешивайте логику.
- Каждый внешний ключ прописан осознанно. Если связь сложная — делайте отдельную таблицу-связку.
- Бэкапы и журналирование: все изменения должны быть обратимыми и прозрачными для любого админа или бэкендерщика.
- Документируйтесь и ревьюйтесь — чем больше людей увидело схему, тем меньше фатальных багов вы встретите.
Заключение: схемы данных как ваша личная система безопасности
Стройка цифрового бизнеса начинается с чертежей. Слишком часто их игнорируют, торопятся прыгнуть к коду, а потом месяцами разгребают нестыковки. Правильная схема данных — не “бумажная работа”, а ваша страховка, лайфхак и двигатель технического прогресса.
Ваш план действий:
Выделить время на подходящий инструмент моделирования, проговорить бизнес-кейсы, продумать масштабируемость — и только после этого погружаться во внедрение автоматизации с такими платформами, как Make.com. В этом пути пригодится не только опыт, но и практические видео, рассылки и разборы, которые делают сообщество сильнее.
Храните данные мудро — и система всегда будет работать на вас, а не против. Итоговая команда из идеальной схемы, гибкой автоматизации и ваших амбиций растопчет любые маркетинговые и технические барьеры, увеличивая трафик, лиды и прибыль, даже не открывая рекламных бюджетов.
Поддерживать прирост можно, используя все инструменты на полную
Если нужен готовый старт — вот прямые гайды для самостоятельной практики:
Хотите быть в курсе последних новостей о нейросетях и автоматизации? Подпишитесь на наш Telegram-канал: https://t.me/maya_pro
Полезные видео и разборы, о которых шла речь:
Как оптимизировать и автоматизировать бизнес-процессы / Кейс Make.com
SORA API , автоматизация создания изображений, баннеров, карточек товаров и прочего через make.com
Полная автоматизация Дзен: От идеи до публикации за 5 минут с Make.com, ChatGPT и Midjourney
Генерация 1000 лидов без вложений: ChatGPT и Make для любого бизнеса
Полная автоматизация блога: SEO-контент на автопилоте с Make.com, Perplexity, ChatGPT и WordPress
От спама до продаж: Как создать идеального нейросетевого Telegram-админа на Make.com
Make.com для начинающих: первые автоматизации | Второе занятие
Ссылки для самостоятельного старта
– Регистрация Make.com
– Обучение по make.com
– Блюпринты по make.com
– Канал о нейросетях и автоматизации
Хотите научиться автоматизации рабочих процессов с помощью сервиса make.com и нейросетей ? Подпишитесь на наш Telegram-канал