Привет! Я Денис Куров, и сегодня мы поговорим о, возможно, самом недооцененном, но критически важном этапе в жизни любой языковой модели — о токенизации. Если вы думаете, что это просто техническая деталь, то вы сильно ошибаетесь. Это фундамент. Выбор токенизатора существенно влияет на эффективность, скорость и качество работы модели, хотя архитектура и данные играют не менее важную роль. Это первое и одно из самых весомых решений, которое принимают разработчики LLM (Large Language Models).
1. Что такое токенизация?
По сути, токенизация — это процесс перевода нашего богатого и бесконечного человеческого языка на язык математики — язык чисел. Нейросеть — это гигантская функция. Она не понимает иронии, не читала Достоевского. Она понимает только векторы и матрицы. Наша задача — превратить строку "мама мыла раму" в массив [123, 456, 789].
Как это сделать правильно?
2. Главная дилемма: гибкость против смысла
Первая мысль, которая приходит в голову, — создать гигантский словарь для каждого слова и дать ему уникальный номер:
"мама" → 1, "мыла" → 2, "раму" → 3.
Однако этот подход (word-level tokenization) сталкивается с суровой реальностью.
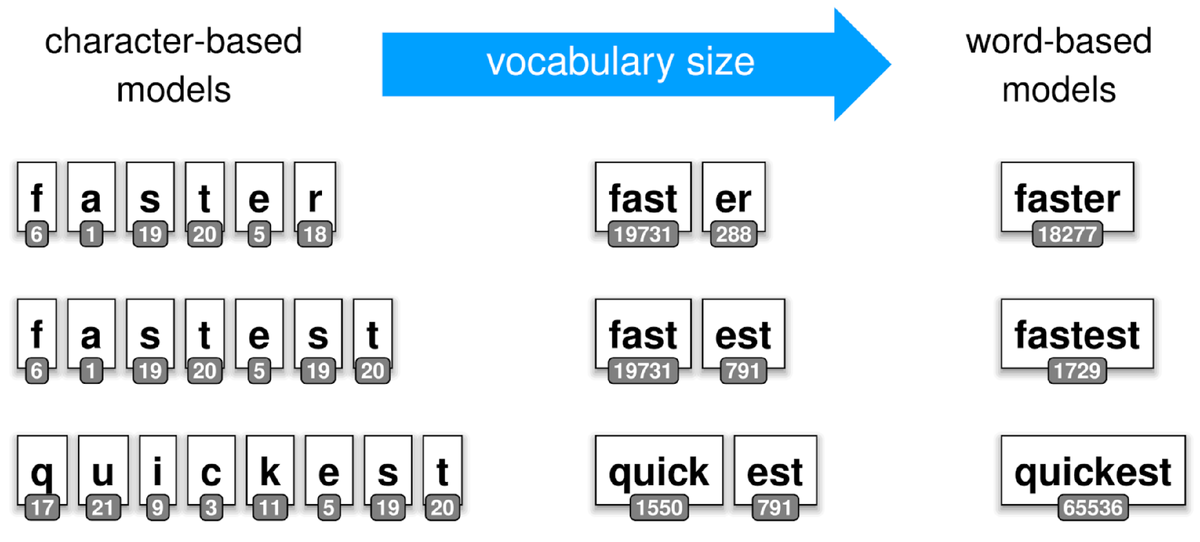
Крайность #1: Кодирование по словам (Word-level)
Плюсы: Каждое слово — это целое понятие, несет много смысла.
Минусы:
- Огромный словарь: В русском языке сотни тысяч слов. При добавлении всех форм, имен, брендов, сленга и опечаток, словарь разрастается до миллионов. Хранить такой гигантский словарь в памяти GPU — крайне неэкономично.
- Избыточность регистра: "King" и "king" — два разных токена для одного понятия! Модель должна заново изучать связь между ними.
- Неизвестные слова (Out-of-Vocabulary, OOV): Если модель сталкивается со словом "микросервисный" или "Midjourney", которого нет в словаре, она не знает, что это, и заменяет его на <unk> (unknown), теряя важную информацию.
Крайность #2: Кодирование по символам/байтам (Character/Byte-level)
Теперь давайте покинем мир слов и спустимся на уровень ниже. Любой текст в мире — это последовательность байтов. В кодировке UTF-8 их всего 256.
Плюсы:
- Крошечный словарь (всего 256 токенов)
- Проблема OOV не существует. Любой текст, любой язык, любой эмодзи можно представить
Минусы:
- Длинные последовательности: Слово "трансформер" (11 букв) может потребовать ~22 байтовых токена. Модели нужно больше вычислительных ресурсов, чтобы из этой "пыли" байтов собрать смысл.
- Избыточность регистра: "K" и "k" — два разных токена для одной буквы! Модель должна заново изучать связь между "King" и "king", хотя это одно понятие.
Но это не просто "неудобно" — это математическая катастрофа
Фраза "искусственный интеллект":
- Посимвольно: ["и", "с", "к", "у", "с", "с", "т", "в", "е", "н", "н", "ы", "й", " ", "и", "н", "т", "е", "л", "л", "е", "к", "т"] → 23 токена
Проблема #1: Квадратичный рост. В классическом механизме внимания сложность растет квадратично, хотя современные модели используют различные оптимизации (Flash Attention, sliding window attention), которые значительно снижают вычислительную нагрузку.
- 4 токена (как если бы мы кодировали словами) → 4² = 16 операций.
- 23 токена → 23² = 529 операций. Рост вычислений в 33 раза! А это всего два слова.
Проблема #2: Градиентное затухание. При обучении информация распространяется назад через слои. В длинных последовательностях градиенты ослабевают настолько, что начальные токены перестают влиять на обучение.
Проблема №3: Контекстное окно "съедается". У каждой модели есть лимит на длину текста (контекстное окно). Статья на 2000 слов при пословном кодировании может занять ~2000 токенов, а при посимвольном — уже ~12000 токенов, что просто не поместится в окно большинства моделей.
Очевидно, ни одна из крайностей нас не устраивает. Нам нужен способ, который сочетал бы лучшее из двух миров — и тут на сцену выходит магия subword tokenization.
3. Решение: Конвейер токенизации и магия subword-алгоритмов
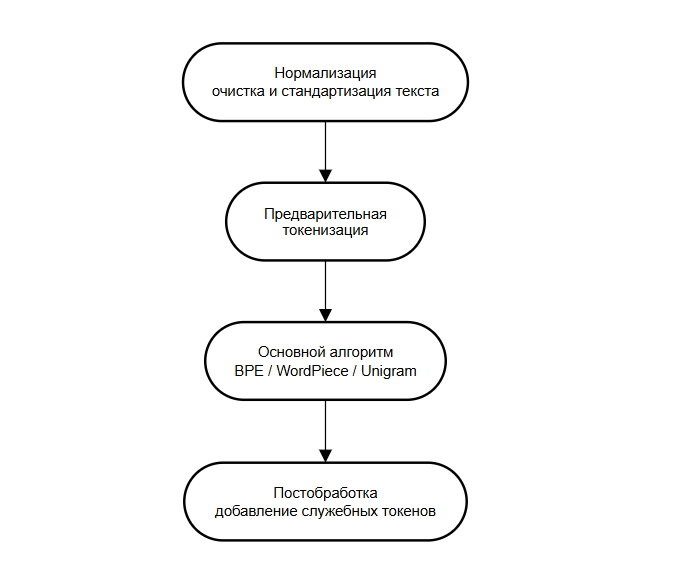
Современные токенизаторы — это не один алгоритм, а целый конвейер из нескольких шагов. Прежде чем текст превратится в числа, он проходит через несколько стадий обработки. Этот конвейер гарантирует, что на вход основному алгоритму (например, BPE) подаются стандартизированные и предсказуемые данные.
Конвейер токенизации:
- Нормализация → Очистка и стандартизация текста
- Предварительная токенизация → Разбивка на базовые блоки
- Основной алгоритм → BPE/WordPiece/Unigram
- Постобработка → Добавление служебных токенов
Давайте разберем каждый шаг.
Шаг 1: Нормализация
Это этап «чистки» текста, его генеральная уборка. Задача — превратить сырой, хаотичный текст в единый, предсказуемый формат. Без этого нейросеть будет спотыкаться на каждом шагу, пытаясь понять, почему "США", "сша" и "С.Ш.А." — это три разных слова, хотя смысл у них один.
Почему это так важно?
- Снижает "шум" и путаницу. Модель перестает тратить ресурсы на изучение орфографических причуд и может сфокусироваться на смысле.
- Экономит ресурсы (и деньги!). Когда "кот", "Кот" и "КОТ" становятся одним токеном "кот", словарь модели становится меньше, а обучение и работа — дешевле и быстрее.
- Создает фундамент для токенизации. Как мы увидим дальше, алгоритмы вроде BPE работают гораздо лучше с чистым, унифицированным текстом.
Основные операции нормализации:
- Приведение к нижнему регистру (опционально): "Hello, World!" → "hello, world!". Используется в моделях типа bert-base-uncased.
- Удаление диакритических знаков: Французское "café" превращается в простое "cafe". Это полезно для моделей, ориентированных на ASCII.
- Нормализация Unicode (NFKC/NFC): Это невидимая, но критически важная магия. Представьте, что символ «ё» можно записать двумя способами: как один цельный символ или как комбинацию из буквы «е» и двух точек над ней. Для нас разницы нет, а для компьютера — есть. Каноническая (NFC): Бережно «склеивает» такие символы (е + ¨ → ё), не меняя их сути.
По совместимости (NFKC): Более агрессивная форма, которая дополнительно заменяет похожие символы на их базовые аналоги. Например, лигатура fi (один символ) станет двумя буквами f и i, а полноширинный символ A — обычной A. - Удаление или нормализация пробелов: Множественные пробелы, табуляции и другие невидимые символы приводятся к единому формату.
Пример:
Практика: Заглянем под капот с помощью Google Colab
Мы можем легко проверить, как это работает, используя библиотеку transformers от Hugging Face.
> > > Вы можете запустить этот код самостоятельно в Google Colab по этой ссылке
Давайте возьмем нарочито "грязную" строку и посмотрим, как с ней справится нормализатор из популярной модели bert-base-uncased. Название uncased как раз и говорит нам, что он не должен учитывать регистр.
Результат, который вы увидите:
Давайте разберем, что произошло:
- Все буквы стали строчными: "ПриВет" превратилось в "привет", "ДЕМОНСТРАЦИЯ" — в "демонстрация".
- Диакритика исчезла: Символ "é" в слове "café" был заменен на обычный "e", став "cafe".
- Лишние пробелы остались: Обратите внимание, что пробелы в начале и в конце строки не были удалены. Это важный момент! Этап нормализации обычно отвечает за обработку самих символов, а удалением лишних пробелов и разделением на слова займется следующий этап конвейера — предварительная токенизация (Pre-tokenization).
Как видите, это детерминированный и понятный процесс. Текст был очищен и стандартизирован, и теперь он готов к следующему этапу — "грубой нарезке на заготовки".
Выбор, который мы увидели в действии — приведение всего к нижнему регистру — это не просто техническая мелочь, а фундаментальное решение, которое делит модели на два больших лагеря: cased (чувствительные к регистру) и uncased (нечувствительные).
Cased vs. Uncased: Стратегическое решение о регистре
На этапе нормализации разработчики LLM делают важный выбор: сохранять ли разницу между "Apple" (компания) и "apple" (фрукт), или же пожертвовать этим нюансом ради эффективности?
1. Uncased (без учета регистра)
Этот подход, который использует bert-base-uncased, ставит во главу угла экономию и простоту. Весь текст приводится к нижнему регистру.
- Плюсы:Компактный словарь: "Дом", "дом" и "ДОМ" становятся одним токеном "дом". Это значительно сокращает размер словаря, что экономит память GPU и ускоряет обучение.
Простота для модели: Модели не нужно тратить ресурсы на изучение того, что "столица" и "Столица" — это одно и то же слово в разных контекстах. Она быстрее улавливает базовые семантические связи. - Минусы:
Потеря важной информации: Иногда регистр — это не причуда, а ключ к смыслу. Модель uncased не отличит: Имена собственные: Орёл (город) от орёл (птица).
Аббревиатуры: МИД (Министерство иностранных дел) от мид (термин в играх).
Эмоциональную окраску: "ПОМОГИТЕ" несет гораздо больше экспрессии, чем "помогите".
2. Cased (с учетом регистра)
Этот подход сохраняет исходный регистр текста, полагая, что эта информация слишком ценна, чтобы ее терять.
- Плюсы:Сохранение семантических нюансов: Модель может различать имена собственные, бренды, акронимы. Это критически важно для задач вроде извлечения именованных сущностей (NER), машинного перевода или продвинутых чат-ботов.
- Минусы:Раздутый словарь: "Word", "word" и "WORD" — это три разных записи в словаре. Это требует больше памяти.
Требуется больше данных: Модели нужно увидеть значительно больше примеров, чтобы понять, что "word" в начале предложения ("Word...") и в середине ("...word...") — это одно и то же слово с точки зрения грамматики, но что "Jobs" (фамилия) и "jobs" (работа) — это разные вещи.
> > > Вы можете запустить этот код самостоятельно в Google Colab по этой ссылке
Шаг 2: Предварительная токенизация (Pre-tokenization)
После очистки текста его нужно разбить на базовые "заготовки" или "слова". Это еще не финальные токены, а лишь грубые блоки, с которыми будет работать основной алгоритм слияния (BPE/WordPiece/Unigram). Этап определяет границы, внутри которых алгоритм будет искать пары для объединения.
Разные семейства токенизаторов решают эту задачу кардинально по-разному:
Три философии разбивки текста
Разные семейства токенизаторов решают эту задачу кардинально по-разному, и каждый подход отражает определенную философию работы с языком:
1. Философия BERT (WordPiece с whitespace pre-tokenization)
"Пробелы — главные границы, пунктуация — по ситуации"
Как работает:
- Сначала текст разбивается по пробелам и основным разделителям
- Изолированные знаки препинания (окруженные пробелами) выделяются в отдельные токены
- Пунктуация, "приклеенная" к словам, остается с ними: "Dr.Smith" → ["Dr.Smith"], а не ["Dr", ".", "Smith"]
- Только после этого к каждому блоку применяется WordPiece
Пример:
"Hello, how are you? I'm fine, thanks!"
Pre-tokens: ["Hello", ",", "how", "are", "you", "?", "I", "'", "m", "fine", ",", "thanks", "!"]
В чем идея? Баланс между сохранением структуры (пробелы = границы слов) и выделением синтаксически важных элементов. Пунктуация выделяется только когда она грамматически значима (отделена пробелами).
Для чего хорошо: NER, синтаксический анализ, задачи классификации, где важна структура предложения.
2. Философия GPT-2/Codex (Byte-level BPE)
"Абсолютная обратимость: пробел — это просто особый байт"
Как работает:
- Все символы, включая пробелы, переводятся в байты UTF-8
- Пробел (байт 0x20) кодируется специальным символом Ġ (U+0120)
- Текст разбивается с сохранением информации о пробелах в самих токенах
- BPE применяется к получившейся последовательности
Пример:
"Hello, how are you? I'm fine, thanks!"
Pre-tokens: ["Hello", ",", "Ġhow", "Ġare", "Ġyou", "?", "ĠI", "'", "m", "Ġfine", ",", "Ġthanks", "!"]
В чем идея? Полная обратимость без потери информации. Модель может точно восстановить исходный текст, включая все пробелы и форматирование.
Для чего хорошо: Генерация текста, кода, машинный перевод — везде, где критично точное воспроизведение форматирования.
3. Философия SentencePiece (T5, Llama, PaLM)
"Полная языковая независимость: никакой предварительной токенизации"
ВАЖНО: SentencePiece — это не столько отдельный алгоритм, сколько мощный фреймворк и библиотека, которая может реализовывать разные subword-алгоритмы, в первую очередь BPE и Unigram. Его кардинальное отличие — в самой философии: он полностью отказывается от этапа предварительной токенизации и работает напрямую с «сырым» текстом. Именно поэтому его используют такие разные модели, как Llama (с алгоритмом BPE) и T5 (с алгоритмом Unigram), — фреймворк один, а «движки» внутри разные.
Как работает:
- Все пробелы заменяются на специальный символ ▁ (U+2581)
- Текст обрабатывается как единая последовательность без предварительного разделения
- Алгоритм (BPE или Unigram) сам решает, что объединять, основываясь только на статистике
- Обучение происходит напрямую с raw text
Пример:
"Hello, how are you? I'm fine, thanks!"
Pre-tokens: ["▁Hello,", "▁how", "▁are", "▁you?", "▁I'm", "▁fine,", "▁thanks!"]
В чем идея? Максимальная универсальность. Подход не делает языковых предположений и одинаково хорошо работает с языками с пробелами (английский) и без них (китайский, японский).
Для чего хорошо: Многоязычные модели, работа с "грязным" web-текстом, языки без явных границ слов.
Уникальные особенности SentencePiece
1. Гибкая токенизация: детерминированность и Subword Regularization. По умолчанию (в режиме предсказания/inference) токенизация полностью детерминирована: для одного и того же текста с одинаковыми параметрами результат всегда будет один. Однако главная «фишка» SentencePiece (при использовании алгоритма Unigram) — это возможность вносить контролируемую случайность во время обучения. Техника Subword Regularization позволяет с некоторой вероятностью выбирать не самый оптимальный, а один из альтернативных вариантов разбиения слова. Это работает как мощная аугментация данных на уровне токенов, делая модель более устойчивой к вариациям в тексте.
# Один и тот же текст может токенизироваться по-разному
"New York" → ['▁New', '▁Y', 'or', 'k']
"New York" → ['▁N', 'e', 'w', '▁Y', 'o', 'r', 'k']
2. Обучение напрямую с raw text - не нужен предварительный этап
3. Поддержка разных алгоритмов - BPE, Unigram (по умолчанию), character, word
4. Фиксированный размер словаря - задается заранее
Offsets (Смещение)
Важно: Токенизаторы также отслеживают позиции (offsets) исходного текста, что критично для задач вроде извлечения именованных сущностей (NER) или анализа тональности:
Offsets (или смещения) — это информация о местоположении токена в исходной текстовой строке. Они представляют собой пару чисел (start_index, end_index), указывающих начальный и конечный символ (индекс) оригинального текста, который соответствует данному токену.
# Пример работы с позициями
[('Hello', (0, 5)), (',', (5, 6)), ('how', (7, 10)), ('are', (11, 14))]
Принцип очень прост: каждый токен не просто получает свой ID, но и "помнит", какую часть исходной строки он представляет.
Например, для ("Hello", (0, 5)) это означает:
- Слово "Hello"
- Начинается на 0-м символе исходной строки (отсчет с нуля)
- Заканчивается на 5-м символе (не включая его).
Таким образом, 'Hello' занимает символы с 0 по 4.
Давайте посмотрим, как эти три подхода справляются с одной и той же фразой:
text = "Hello, how are you?"
(между ',' и 'how" два пробела)
(между 'are' и 'you' два пробела)
🔗 Вы можете запустить этот код самостоятельно в Google Colab по этой ссылке
Результат исполнения кода
BERT (WordPiece) Pre-tokens
BERT WordPiece pre-tokens:
[0:5] -> 'Hello'
[5:6] -> ','
[8:11] -> 'how'
[12:15] -> 'are'
[17:20] -> 'you'
[20:21] -> '?'
- [0:5] -> 'Hello' Что происходит: Захватывает символы с 0 по 4 (Hello). На 5-м символе (,) останавливается, так как это знак препинания.
- [5:6] -> ',' Что происходит: Захватывает запятую как отдельный токен.
- [8:11] -> 'how' Что происходит: Пропускает два пробела на позициях 6 и 7. Находит слово how (символы с 8 по 10) и делает его токеном.
- [12:15] -> 'are' Что происходит: Пропускает пробел на позиции 11. Захватывает слово are (символы с 12 по 14).
- [17:20] -> 'you' Что происходит: Пропускает два пробела на позициях 15 и 16. Захватывает слово you (символы с 17 по 19).
- [20:21] -> '?' Что происходит: Захватывает знак вопроса как отдельный токен.
Итог по BERT: Максимально простое разделение. Информация о количестве пробелов полностью теряется.
GPT-2 (BPE) Pre-tokens
GPT-2 BPE pre-tokens:
[0:5] -> 'Hello'
[5:6] -> ','
[6:7] -> 'Ġ'
[7:11] -> 'Ġhow'
[11:15] -> 'Ġare'
[15:16] -> 'Ġ'
[16:20] -> 'Ġyou'
[20:21] -> '?'
Основной принцип: Пре-токенизатор GPT-2 хитрее. Он хочет сохранить информацию о пробелах, потому что это важно для генерации текста. Он заменяет пробел на специальный символ Ġ (это не буква G, а специальный символ, обозначающий начало нового слова, которому предшествовал пробел). Он не выбрасывает пробелы.
- [0:5] -> 'Hello' Что происходит: Первое слово в строке. Перед ним нет пробела, поэтому токен — это просто Hello.
- [5:6] -> ',' Что происходит: Запятая отделяется, как и у BERT.
- [6:7] -> 'Ġ' Что происходит: Это первый пробел после запятой (на позиции 6). GPT-2 видит его и превращает в отдельный токен Ġ.
- [7:11] -> 'Ġhow' Что происходит: Это второй пробел (на позиции 7), за которым следует слово how. Токенизатор объединяет их в один пре-токен 'Ġhow'. Ġ здесь означает, что перед словом how был пробел.
- [11:15] -> 'Ġare' Что происходит: Пробел на позиции 11 объединяется со словом are.
- [15:16] -> 'Ġ' Что происходит: Это первый из двух пробелов перед you (на позиции 15). Он становится отдельным токеном Ġ.
- [16:20] -> 'Ġyou'Что происходит: Второй пробел (на позиции 16) объединяется со словом you.
- [20:21] -> '?'Что происходит: Знак вопроса отделяется.
Итог по GPT-2: Сохраняется вся информация о пробелах. Двойной пробел превращается в два токена ('Ġ' и 'Ġ<word>'), что позволяет модели понимать и генерировать разное количество пробелов.
T5 (SentencePiece) Pre-tokens
T5 SentencePiece pre-tokens:
[0:6] -> '▁Hello,'
[8:11] -> '▁how'
[12:15] -> '▁are'
[17:21] -> '▁you?'
- [0:6] -> ' Hello,' Что происходит: Захватывает Hello,. В своей внутренней репрезентации SentencePiece добавляет к началу слова мета-пробел , даже если его не было в исходном тексте (это часть его алгоритма нормализации текста).
- [8:11] -> ' how' Что происходит: Два пробела на позициях 6 и 7 схлопываются в один. Этот один пробел заменяется на и присоединяется к началу слова how. В итоге получается ' how'.
- [12:15] -> ' are' Что происходит: Один пробел на позиции 11 заменяется на и присоединяется к слову are.
- [17:21] -> ' you?' Что происходит: Два пробела на позициях 15 и 16 снова схлопываются в один. Этот пробел заменяется на и присоединяется к you?.
Итог по T5: Информация о пробелах сохраняется, но информация об их количестве теряется (двойные пробелы становятся одинарными). Пробел рассматривается как неотъемлемая часть следующего за ним слова.
Теперь мы готовы к главному. Решение пришло из мира сжатия данных.
Шаг 3: Встречайте subword tokenization и ее алгоритмы.
BPE (Byte-Pair Encoding): От сжатия данных к токенизации
Откуда появился BPE?
BPE впервые описал Филипп Гейдж в 1994 году. Идея простая: если в тексте часто встречается пара символов "th", зачем хранить их отдельно? Давайте создадим новый символ "th" и заменим все вхождения. Текст станет короче!
Позже OpenAI поняли: если алгоритм хорошо сжимает текст, значит, он выделяет важные паттерны. Эти паттерны — идеальные токены для языковых моделей. Так BPE стал стандартом для GPT, GPT-2, RoBERTa, BART и многих других.
Как работает BPE: пошаговый алгоритм
Этап 1: Создание базового словаря
Входные данные: Корпус текста после нормализации и пре-токенизации
Задача: Собрать все уникальные символы
# Пример корпуса
corpus = ["hug", "pug", "pun", "bun", "hugs"]
# Базовый словарь = все уникальные символы
base_vocab = ["b", "g", "h", "n", "p", "s", "u"]
Важный момент: Многие современные системы используют byte-level BPE, но также применяются гибридные подходы и расширенные наборы символов в зависимости от задач
Этап 2: Подсчет частот слов
# Подсчитываем, как часто встречается каждое слово
word_frequencies = {
"hug": 10, # встречается 10 раз
"pug": 5, # встречается 5 раз
"pun": 12, # встречается 12 раз
"bun": 4, # встречается 4 раза
"hugs": 5 # встречается 5 раз
}
Этап 3: Разбиение на символы
# Каждое слово представляем как список символов
splits = {
"hug": ["h", "u", "g"],
"pug": ["p", "u", "g"],
"pun": ["p", "u", "n"],
"bun": ["b", "u", "n"],
"hugs": ["h", "u", "g", "s"]
}
Этап 4: Итеративное слияние (главная магия!)
Итерация 1: Ищем самую частую пару символов
# Подсчитываем все пары и их частоты
pair_frequencies = {
("h", "u"): 10 + 5 = 15, # в "hug" (10 раз) + "hugs" (5 раз)
("u", "g"): 10 + 5 + 5 = 20, # в "hug", "pug", "hugs"
("p", "u"): 5 + 12 = 17, # в "pug" + "pun"
("u", "n"): 12 + 4 = 16, # в "pun" + "bun"
# ... и так далее
}
# Самая частая пара: ("u", "g") = 20 раз
Слияние: Создаем новый токен "ug" и обновляем словарь
# Обновляем словарь
vocab = ["b", "g", "h", "n", "p", "s", "u", "ug"]
# Обновляем разбиения
splits = {
"hug": ["h", "ug"], # "h" + "u" + "g" → "h" + "ug"
"pug": ["p", "ug"], # "p" + "u" + "g" → "p" + "ug"
"pun": ["p", "u", "n"], # без изменений
"bun": ["b", "u", "n"], # без изменений
"hugs": ["h", "ug", "s"] # "h" + "u" + "g" + "s" → "h" + "ug" + "s"
}
Итерация 2: Повторяем процесс
# Новые частоты пар
pair_frequencies = {
("h", "ug"): 10 + 5 = 15,
("p", "ug"): 5,
("p", "u"): 12,
("u", "n"): 12 + 4 = 16, # самая частая!
("b", "u"): 4,
("ug", "s"): 5
}
# Слияние: ("u", "n") → "un"
vocab = ["b", "g", "h", "n", "p", "s", "u", "ug", "un"]
Итерация 3:
# После слияния ("u", "n") → "un"
splits = {
"hug": ["h", "ug"],
"pug": ["p", "ug"],
"pun": ["p", "un"], # "p" + "u" + "n" → "p" + "un"
"bun": ["b", "un"], # "b" + "u" + "n" → "b" + "un"
"hugs": ["h", "ug", "s"]
}
# Самая частая пара: ("h", "ug") = 15 раз
# Слияние: ("h", "ug") → "hug"
vocab = ["b", "g", "h", "n", "p", "s", "u", "ug", "un", "hug"]
Продолжаем до достижения целевого размера словаря (обычно 30,000-50,000 токенов)
Ключевые преимущества BPE
1. Решение проблемы OOV (Out-of-Vocabulary)
В своей byte-level реализации (которую используют модели семейства GPT) BPE полностью решает проблему неизвестных слов. Поскольку любой текст в конечном счете состоит из байтов (а их всего 256), такой токенизатор в принципе не может встретить незнакомый символ. Любое новое слово, бренд или даже эмодзи будет надежно разложено на последовательность байтовых токенов, а не заменено на бесполезный <unk>. В других реализациях, работающих с символами, проблема OOV также значительно смягчается.
Незнакомое слово: "микросервисный
Вместо <unk> будет разбито на известные части, например:
["микро", "сервис", "ный"]
2. Адаптивность к частоте
- Частые слова остаются целыми: "the", "and", "is"
- Редкие слова разбиваются на подслова: "debugging" → ["de", "bug", "ging"]
3. Эффективность
- Сбалансированная длина токенов
- Меньше токенов = быстрее обработка
- Больше смысла на токен = лучше понимание
Почему BPE работает так хорошо?
Статистическая мудрость
BPE автоматически находит лингвистически значимые единицы:
- Морфемы: "un-", "pre-", "-ing", "-tion"
- Корни слов: "learn", "teach", "know"
- Частые слоги: "tion", "ment", "ness"
Принцип сжатия = принцип понимания
Если последовательность символов часто встречается вместе, она несет единый смысл. BPE это улавливает автоматически.
Ограничения BPE
1. Только частотная статистика
BPE не понимает грамматику или семантику. Может создать бессмысленные токены, если они статистически частые.
2. Жадный алгоритм
На каждом шаге выбирается только самая частая пара. Это может привести к субоптимальному результату.
3. Детерминированность
Для одного и того же текста всегда получается одинаковый результат. Нет вариативности.
Вывод
BPE — это элегантное решение, которое:
- Берет лучшее от символьного (нет OOV) и словесного (семантика) уровней
- Автоматически адаптируется к особенностям языка
- Работает быстро и эффективно
- Стал стандартом для современных языковых моделей
Следующий шаг — изучить более сложные алгоритмы WordPiece и Unigram, которые пытаются улучшить некоторые ограничения BPE.
WordPiece: Умное слияние от Google
BPE — это мощный и элегантный алгоритм, но не единственный. Инженеры Google, работая над легендарным BERT, решили пойти немного другим путем и создали WordPiece. На первый взгляд он очень похож на BPE, но дьявол, как всегда, в деталях.
Главные отличия WordPiece от BPE:
- Специальный префикс: WordPiece явно помечает части слова, которые не являются его началом. Для этого используется префикс ##. Так, слово tokenization при начальном разбиении превращается в ['t', '##o', '##k', '##e', '##n', '##i', '##z', '##a', '##t', '##i', '##o', '##n']. Это помогает модели четко понимать, где начинается целое слово, а где — его продолжение.
- Выбор пары для слияния: не частота, а правдоподобие. Это ключевое и самое "умное" отличие. BPE просто ищет самую частую пару. WordPiece задает более сложный вопрос: «Насколько вероятнее эта пара символов встретится вместе, чем по отдельности?».
Он вычисляет score (оценку) для каждой потенциальной пары по формуле, которая похожа на вычисление взаимной информации:
score = (частота_пары) / (частота_первого_элемента × частота_второго_элемента)
Что это значит на практике?
- Рассмотрим пару ("un", "##able"). Она может встречаться в тексте очень часто. Но и un (как префикс в словах "happy", "usual") и able (в словах "doable", "lovable") сами по себе очень частые. Знаменатель в формуле будет большим, и итоговый score — низким. Алгоритм не будет спешить их объединять, понимая, что это два независимых и полезных токена.
- А теперь пара ("hugg", "##ing"). Слово "hugging" встречается часто, но вот подстроки hugg и ##ing по отдельности вряд ли так же популярны. Знаменатель будет маленьким, а score — высоким. WordPiece быстро поймет, что эти части сильно "тяготеют" друг к другу, и объединит их.
Таким образом, WordPiece отдает предпочтение парам, которые статистически "принадлежат" друг другу, а не просто часто оказываются рядом.
Использование только итогового словаря. В отличие от BPE, который для токенизации нового текста может применять все сохраненные правила слияния, WordPiece работает иначе. Он разбивает слово с помощью так называемого «жадного поиска самого длинного префикса» (longest-match-first) в уже готовом итоговом словаре.
Как он токенизирует новое слово, например, "tokenization"?
- Сначала он берет все слово целиком ("tokenization") и проверяет, есть ли оно в словаре. Допустим, нет.
- Затем он ищет самый длинный префикс слова, который есть в словаре. Он проверяет "tokenizatio", "tokenizat", ... и находит token. Это будет первый токен в итоговой последовательности.
- Далее он переходит к оставшейся части слова — "ization" — и добавляет к ней специальный префикс ##, получая ##ization.
- Теперь он повторяет поиск для ##ization, ища самый длинный префикс в словаре. Допустим, он сразу находит ##ization как один токен.
- Итог: ['token', '##ization']. Префикс ## явно показывает модели, что этот токен — не начало нового слова, а его продолжение.
Этот подход может давать другие результаты, чем BPE. Например, для слова hugs BPE мог бы выдать ['hu', '##gs'], а WordPiece, если в его словаре есть hug, выдаст ['hug', '##s'].
- Жесткая обработка неизвестных слов. Если WordPiece в процессе разбиения слова натыкается на часть, которую не может найти в словаре, он не пытается разбить ее дальше на символы. Он сдается и помечает все исходное слово как [UNK]. BPE в этом плане более гибок и заменил бы на [UNK] только неизвестный символ.
Итог по WordPiece
WordPiece — это более сложный, но и потенциально более "семантически осмысленный" подход, чем BPE. Его вероятностная модель выбора пар для слияния позволяет создавать токены, которые лучше отражают морфологическую структуру языка. Именно этот алгоритм лежит в основе многих моделей семейства BERT (DistilBERT, MobileBERT и др.).
Unigram: Не объединяй, а сокращай! И добавь вероятности
Если BPE и WordPiece работают "снизу вверх", начиная с символов и объединяя их в более крупные токены, то Unigram идет в противоположном направлении — "сверху вниз". Он также вводит мощную концепцию вероятностной токенизации, что делает его уникальным. Этот алгоритм лежит в основе SentencePiece — фреймворка, который используют такие модели, как T5, Llama, ALBERT и XLNet.
Принципиально другой подход
Алгоритм Unigram можно описать так:
- Начни с избыточного словаря. Вместо того чтобы начинать с маленького алфавита, Unigram стартует с огромного словаря. Этот словарь может включать все символы, все слова из корпуса и огромное количество всевозможных подслов (например, "ток", "окен", "изац", "ация").
- Вычисли вероятности. Для каждого токена в этом гигантском словаре вычисляется его вероятность — по сути, как часто он встречается в корпусе.
- Итеративно сокращай. Теперь начинается самое интересное. Алгоритм итеративно удаляет токены из словаря. Но какие? Те, удаление которых минимально навредит общей "вероятности" корпуса. На каждом шаге он как бы спрашивает: "Какой токен я могу выкинуть, чтобы итоговое качество токенизации пострадало меньше всего?".
- Повторяй до нужного размера. Этот процесс "прореживания" продолжается до тех пор, пока размер словаря не достигнет заданного значения (например, 32 000 токенов). Базовые символы при этом никогда не удаляются, чтобы гарантировать возможность токенизировать любое слово.
Вероятностная токенизация: один текст — много вариантов
Главная суперсила Unigram — в том, как он токенизирует текст. Вместо того чтобы иметь одно-единственное "правильное" разбиение для слова, Unigram рассматривает все возможные варианты и выбирает тот, у которого наибольшая итоговая вероятность.
Как это работает на примере слова pug:
- Вариант 1: ['p', 'u', 'g']. Его вероятность = P('p') * P('u') * P('g').
- Вариант 2: ['pu', 'g']. Его вероятность = P('pu') * P('g').
- Вариант 3: ['p', 'ug']. Его вероятность = P('p') * P('ug').
Unigram выберет тот вариант, у которого произведение вероятностей токенов будет максимальным. Как правило, выигрывают разбиения с меньшим количеством токенов, так как каждый токен имеет вероятность меньше 1, и чем больше множителей, тем меньше итоговое произведение.
Для поиска наилучшего разбиения используется классический алгоритм Витерби.
Subword Regularization: Встроенная аугментация
Эта вероятностная природа открывает дверь к потрясающей технике, которую использует SentencePiece, — Subword Regularization. Во время обучения модели можно не всегда выбирать самое вероятное разбиение, а иногда подбрасывать и другие, чуть менее вероятные варианты.
Например, для New York модель может увидеть такие варианты токенизации:
- [' New', ' York'] (самый вероятный)
- [' New', ' Y', 'ork'] (менее вероятный)
- [' N', 'e', 'w', ' York'] (еще менее вероятный)
Зачем это нужно?
Это работает как аугментация данных на уровне токенов. Модель учится быть более устойчивой к "шуму" и разным способам написания, понимая, что разные последовательности токенов могут вести к одному и тому же смыслу. Это делает ее более робастной.
Итог по Unigram
Unigram — это не просто еще один алгоритм, а смена парадигмы:
- Сверху вниз: Начинает с большого словаря и сокращает его.
- Вероятностный: Выбирает наиболее вероятное разбиение из множества возможных.
- Гибкий: Позволяет использовать Subword Regularization для повышения устойчивости модели.
Именно эта гибкость и языковая независимость (благодаря фреймворку SentencePiece, который обрабатывает пробелы как обычные символы) сделали Unigram стандартом для многих современных многоязычных и генеративных моделей.
Шаг 4: Пост-обработка — Добавляем "знаки препинания" для модели
Итак, наши алгоритмы (BPE, WordPiece или Unigram) проделали колоссальную работу: они превратили сырой текст в осмысленную последовательность чисел (ID токенов). Но для модели это пока лишь плоский список. Чтобы нейросеть поняла структуру задачи, нам нужно добавить к этой последовательности специальные служебные (или контрольные) токены.
Представьте, что это "мета-разметка" или "команды" для нейросети. Они не являются частью исходного текста, но говорят модели, где начинается и заканчивается предложение, где вопрос, а где ответ, или какой фрагмент использовать для классификации.
Этот этап критически важен, потому что каждая архитектура обучается понимать свой собственный, уникальный формат. Подать GPT-модели данные в формате BERT — это как пытаться запустить программу для Windows на macOS. Не сработает.
Давайте рассмотрим, какие шаблоны используют ключевые семейства моделей.
1. Шаблон для BERT и Encoder-моделей (задачи на понимание)
Модели типа BERT (и его производные: RoBERTa, DistilBERT) — это энкодеры. Их главная задача — глубоко понять текст и создать его богатое представление для таких задач, как классификация, ответы на вопросы (extractive QA) или извлечение именованных сущностей (NER). Их шаблон заточен именно под это.
- [CLS] (Classification): Этот токен всегда ставится в самое начало последовательности. Его магия не в том, что он что-то означает сам по себе, а в том, как модель его использует. Финальный вектор (эмбеддинг), соответствующий этому токену после прохождения всех слоев трансформера, используется как агрегированное представление всей последовательности. Именно этот вектор подается на классификационную "голову" для решения таких задач, как анализ тональности или определение спама.
- [SEP] (Separator): Этот токен работает как разделитель. Он незаменим в задачах, где модели нужно работать с двумя (или более) сегментами текста.Классификация пар предложений: [CLS] Предложение A [SEP] Предложение B [SEP]
Ответы на вопросы: [CLS] Вопрос [SEP] Текст, в котором ищем ответ [SEP] - [PAD] (Padding): Модели обрабатывают данные батчами (пачками), и для эффективности все последовательности в одном батче должны иметь одинаковую длину. Токен [PAD] добавляется в конец более коротких последовательностей, чтобы "добить" их до нужной длины. Механизм внимания (attention mask) затем игнорирует эти токены.
- [MASK]: Особый токен, используемый при предобучении BERT (задача Masked Language Modeling), где модель учится предсказывать скрытые [MASK]-токены.
Пример для BERT:
Текст: "Какой фильм посмотреть? Мне нравятся комедии."
Токены на входе модели: [CLS] Какой фильм посмотреть? [SEP] Мне нравятся комедии. [SEP]
2. Шаблон для GPT/Llama и Decoder-моделей (задачи на генерацию)
Модели-декодеры (GPT, Llama, T5) видят мир как непрерывный поток текста. Их главная задача — предсказать следующий токен. Поэтому их система разметки проще, но не менее важна, особенно в режиме чата.
- BOS/EOS (Begin/End of Sequence):<|begin_of_text|> или <s> (BOS): Маркер, который говорит модели: "Начинай генерацию отсюда". Он запускает процесс.
<|end_of_text|> или </s> (EOS): Маркер, который сигнализирует о конце связного фрагмента текста. Во время генерации, когда модель выдает этот токен, мы понимаем, что она закончила свой ответ. - Шаблоны для чата (Chat Templates): В современных чат-ботах (как на базе Llama или Mistral) служебные токены используются для разметки диалога, чтобы модель понимала, где реплика пользователя, где ее собственный ответ, а где системные инструкции.
Пример для Llama 3:
Диалог:
- System: Ты — полезный ассистент.
- User: Привет!
Токены на входе модели будут выглядеть примерно так (упрощенно):
<|start_header_id|>system<|end_header_id|>
Ты — полезный ассистент.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Привет!<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
Здесь <|start_header_id|>, <|end_header_id|>, <|eot_id|> (end of turn) — это всё служебные токены, которые создают строгую структуру, понятную модели.
5. Заключение
Токенизация — это не просто технический этап, это стратегическое решение, которое определяет возможности, ограничения и эффективность вашей языковой модели. Правильный выбор токенизатора может:
- Сэкономить значительные вычислительные ресурсы
- Улучшить качество работы модели
- Обеспечить поддержку нужных языков и форматов
- Решить специфические задачи вашего домена
Понимание принципов токенизации поможет вам делать более осознанный выбор при работе с LLM и оптимизировать производительность ваших AI-приложений.