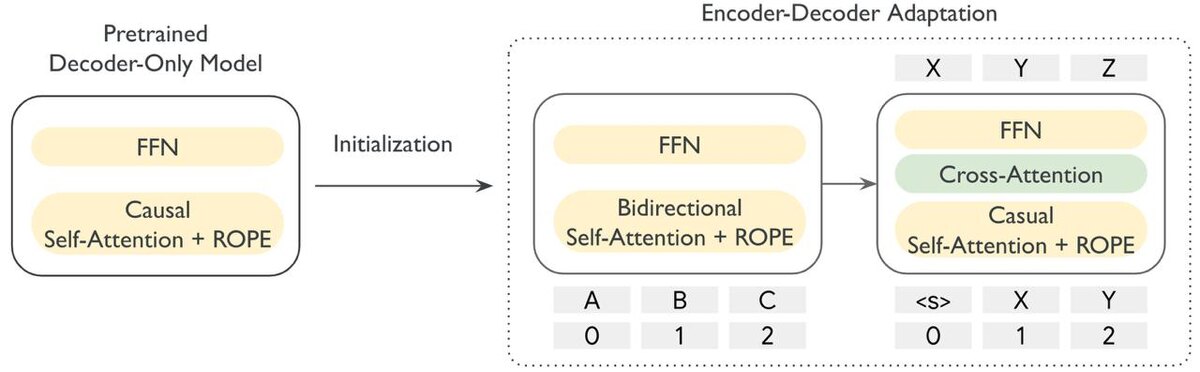
коллеги из Google выпустили статью с интересной идеей: вернуться к концепции encoder-decoder (недавно такую модель выпустил Microsoft); суть подхода изложена на первой картинке - берем готовую декодерную модель, в их случае Gemma, и инициализируем все веса декодировщика из нее, веса кодировщика также берутся из декодерной модели, кроме весов внимания, которое учится с нуля; в качестве преимущества подхода заявляется возможность создания несбалансированных моделей с большим кодировщиком и маленьким декодировщиком
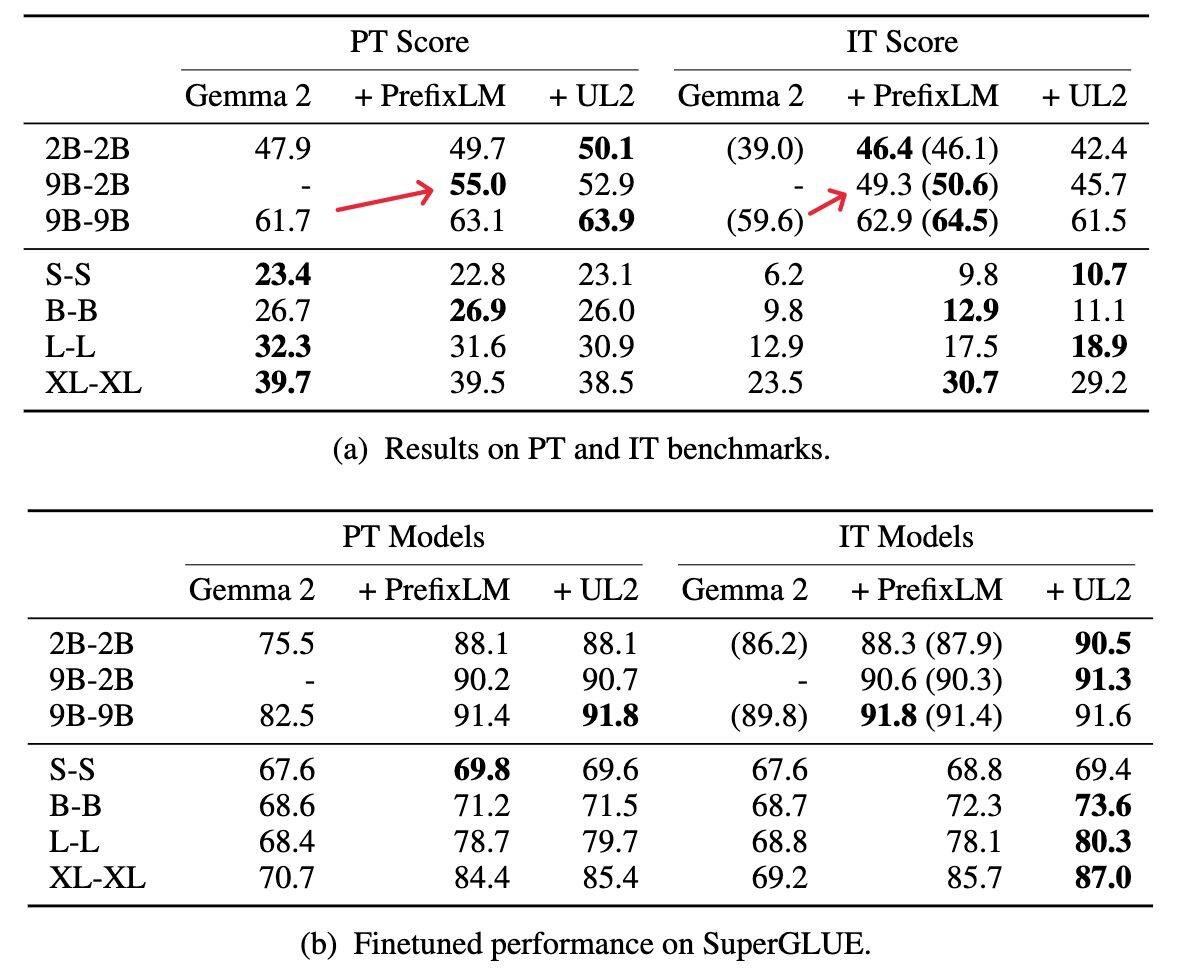
на второй картинке представлены результаты; PT - это набор стандартных датасетов, типа SuperGLUE, а IT - инструкционных; и вот тут для меня начинаются проблемы - получается, что модель 9+2B хуже, чем обычная 9B; этот аспект авторы как-то обошли стороной (показал стрелочками); интересно, что на SuperGLUE этого эффекта не наблюдается (нижняя часть второй картинки)