Инсайд о результатах бенчмарков GPT 5 Это паразительно, не думающая модель что превосходит grok 4 heavy(несколько думающих моделей запускаются на 1 промпт и позже решают чей ответ лучше, как я понял - грубо говоря на 1 запрос 4 ответа и выбор лучшего) Human Last Exam 50 и 56, поразительно. Особенно будет интересно посмотреть на arc asi 2, где grok также сильно преуспел. И swe(кодинг) на 85 и 90, поразительно Есть большая надежда что это так и есть и инсайд не вкинули. И если это так, OpenAI до сих пор с отрывом впереди
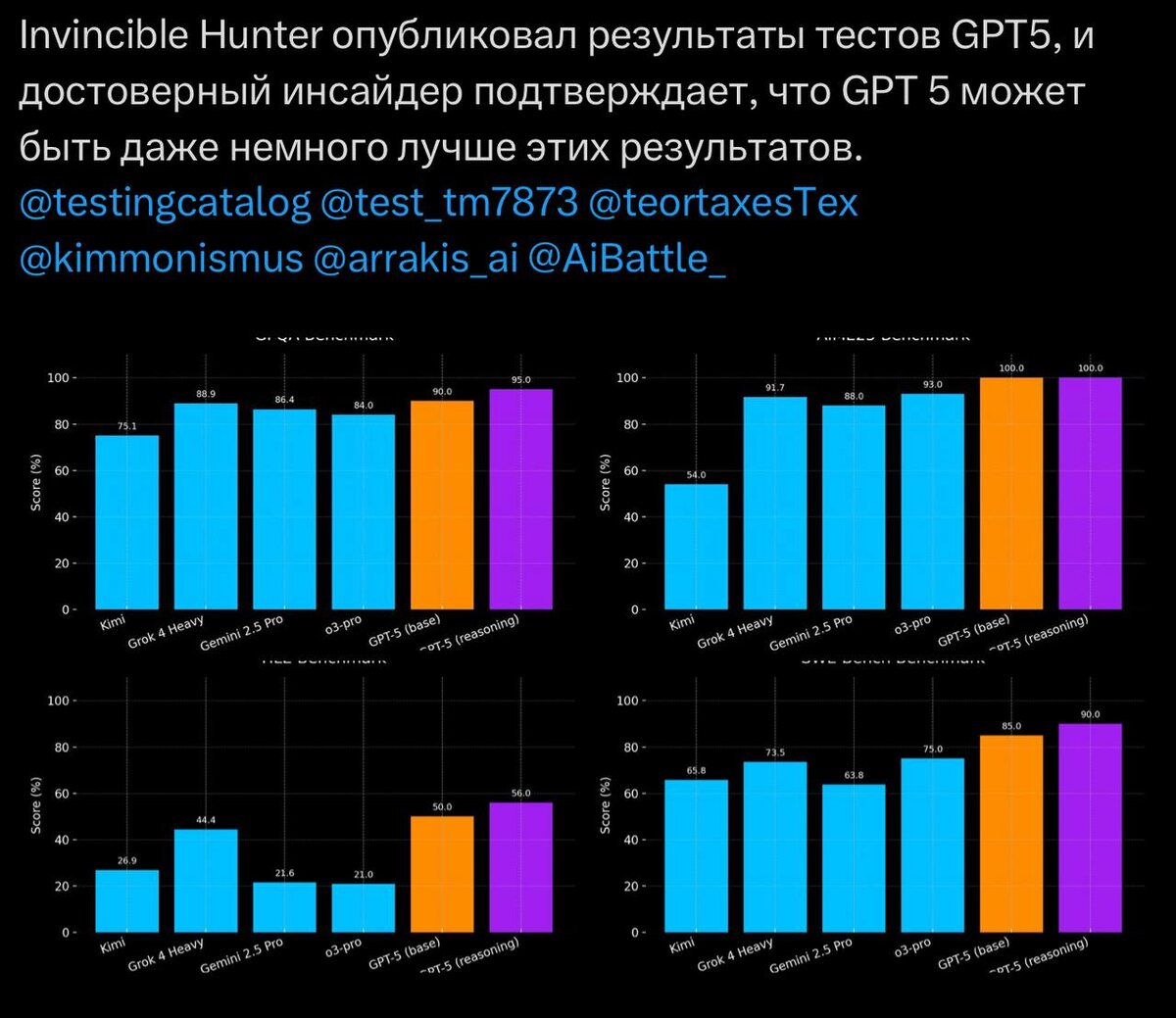
Инсайд о результатах бенчмарков GPT 5
Это паразительно, не думающая модель что превосходит grok 4 heavy(несколько думающих моделей запускаются на 1 промпт и позже решают чей ответ лучше, как я понял - грубо говоря на 1 запрос 4 ответа и выбор лучшего)
Human Last Exam 50 и 56, поразительно. Особенно будет интересно посмотреть на arc asi 2, где grok также сильно преуспел. И swe(кодинг) на 85 и 90, поразительно
Есть большая надежда что это так и есть и инсайд не вкинули. И если это так, OpenAI до сих пор с отрывом впереди