Доброго здоровья читателям моего канала programmer's notes. Поддерживаем мой канал.
Библиотека openpyxl для Python для работы с электронными таблицами (xlsx)
На самом деле для работы с электронными таблицами формата xlsx есть несколько библиотек. Мне нравится openpyxl. Ну значит на ней и остановимся пока.
Установить библиотеку можно стандартным образом
pip3 (pip) install openpyxl
Вот и всё, и приступать к работе уже можно
Общие возможности библиотеки openpyxl
Подсоединяем библиотеку с помощью обычной команды import, ну а далее используем тот или иной класс этой библиотеки.
С чего начать работу с электронной таблицей? Надо определиться, что вы хотите делать. Создавать новую или работать с существующей. Впрочем, можно сочетать и то и другое. Например, вытаскивать из нескольких таблиц данных, обрабатывать их и результат переносить во вновь созданную таблицу. Создаём таблицу с помощью класса Workbook, открываем с помощью класса load_workbook.
#!/usr/bin/python3
from openpyxl import Workbook
wb = Workbook() # создаём объект таблицу
sha1 = wb.active # получаем активный лист, он единственный
sha1.title = "Лист первый"
# записываем данные
sha1['B3'] = 'Привет, мир!'
sha1['C3'] = 333.333
sha2 = wb.create_sheet(title='Лист второй')
sha2['A1'] = 12
sha2['A2'] = 32
sha2['A3'] = 22
sha2['A4'] = 122
sha2['A5'] = "=SUM(A1:A4)" # вставили формулу
wb.save('new.xlsx') # сохранили таблицу в файл
Пояснение к программе
- Программа создаёт таблицу с двумя листами и вводит на них данные, при чём на втором листе с формулой.
- Объект Workbook это электронная таблица, только она в памяти. Чтобы создать электронную таблицу в виде файла используем метод save().
- При создании таблицы создаётся один лист, доступ к которому получаем через свойство active.
- Для создания нового листа используется метод create_sheet(), при этом сразу можно указать имя нового листа. Через объект "лист" можно получать доступ к отдельным ячейкам. Для это используем обычные координаты ячеек, которые используются в электронных таблицах.
Следующая программа
#!/usr/bin/python3
from openpyxl import load_workbook
wb = load_workbook('new1.xlsx')
sh0 = wb['Лист первый']
wb.remove(sh0) # удаляем лист
sh1 = wb["Лист второй"]
sh1.title = 'Лист номер 0' # меняем название
sh1['A5'] = 400
sh1['A6'] = "=SUM(A1:A5)"
wb.save('new1.xlsx')
Пояснения к программе
- Данная программа открывает уже существующую таблицу и проводит с ней ряд манипуляций.
- С помощью метода remove() можно легко удалить существующий лист.
- Далее мы меняем некоторые данные на оставшемся листе.
Может возникнуть вопрос, как получить список всех листов электронной таблицы. Да элементарно, если wb это объект электронная таблица, то
ls = [t for t in wb.sheetnames]
и ls это список имён листов электронной таблицы.
Рассмотрим теперь вопрос о том, как менять внешний вид электронной таблицы.
#!/usr/bin/python3
from openpyxl import load_workbook
from openpyxl.styles import Font, Alignment, PatternFill
wb = load_workbook('new.xlsx')
sh1 = wb['Лист первый']
sh1.column_dimensions["B"].width = 30 # ширина столбца
sh1.column_dimensions["B"].width = 40
sh1.row_dimensions[3].height = 40 # высота строки
sh1["B3"].font = Font(bold=True) # жирный шрифт
sh1["B3"].font = Font(color="00AAFF") # цвет текста
# выравнивание
sh1["C3"].alignment = Alignment(horizontal="center", vertical="center")
color = PatternFill(start_color='8888DD', fill_type='solid') # цвет заполнения
sh1['B3'].fill = color # фон в ячейке
wb.save('new.xlsx')
Пояснение к программе
Программа прокомментирована, перечислю только действия, которые она выполняет: ширина столбца, высота строки, тип шрифта, выравнивание в ячейке, цвет фона в ячейке.
Может возникнуть вопрос о получении значения в ячейке. Тут всё просто. Если sh1 это лист, то sh1['A2'].value - это значение величины, которое стоит в ячейке A2. Кстати, если ячейка пуста, то указанная величина равно None.
Библиотека openpyxl и работа с данными
Пусть имеем электронную таблицу, представленную на рисунке 1. Как видим данные начинаются не с краёв электронной таблицы. Попробуем корректно прочитать данные. При этом поставим дополнительную задачу. Пронумеруем строки таблицы. Это может пригодиться, если мы хотим из электронной таблицы сделать таблицу в СУБД. При этом мы не знаем, где у нас кончаются строки и столбцы (sic!).
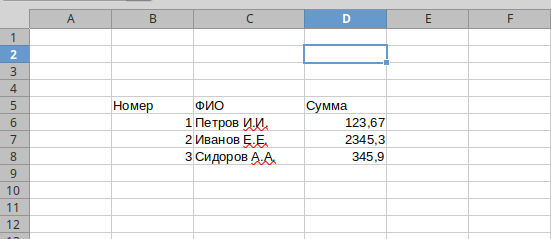
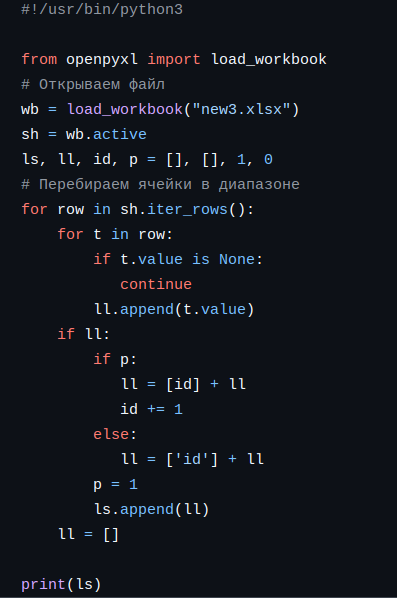
Программа, корректно читающая данные представлена ниже.
Результат выполнения программы
[['id', 'Номер', 'ФИО', 'Сумма'], [1, 1, 'Петров И.И.', 123.67], [2, 2, 'Иванов Е.Е.', 2345.3], [3, 3, 'Сидоров А.А.', 345.9]]
Т.е. мы получили двумерный список. Первая строка - названия столбцов. В таком виде список можно использовать для создания таблицы на сервере базы данных.
Пояснения к программе
- Алгоритм основывается на методе-итераторе объекта лист iter_rows(). Это интеллектуальный итератор так как он не берёт лишних строк и столбцов.
- Но начальные пустые строки и пустые столбцы мы должны обрабатывать сами. Обратим внимание на цикл for t in row:. В нем перебираются ячейки строки. И если строка полностью пуста, то она игнорируется (if ll:).
- Параллельно мы нумеруем строки с помощью переменной id. В дальнейшем этот столбец можно использовать в качестве первичного ключа.
На самом деле можно читать данные и в указанном диапазоне. Пример ниже использует технику генераторов.
#!/usr/bin/python3
from openpyxl import load_workbook
wb = load_workbook("new4.xlsx")
sh = wb.active
rows = [list(row) for row in sh["A1:C4"]]
[[print(f"Ячейка {t.coordinate}: {t.value}") for t in p] for p in rows]
Результат выполнения для конкретной электронной таблицы
Ячейка A1: Номер
Ячейка B1: ФИО
Ячейка C1: Сумма
Ячейка A2: 1
Ячейка B2: Петров И.И.
Ячейка C2: 123.67
Ячейка A3: 2
Ячейка B3: Иванов Е.Е.
Ячейка C3: 2345.3
Ячейка A4: 3
Ячейка B4: Сидоров А.А.
Ячейка C4: 345.9
Ну, изложил я далеко не всё о работе с библиотекой openpyxl, но, мне кажется, что достаточно, чтобы писать программы с использованием электронных таблиц.
Пока всё!
Хорошего программирования. Оставляйте свои комментарии, не забывайте про лайки и подписывайтесь на мой канал programmer's notes.