Трон опенсорс-моделей снова занят 🤴
Недолго Kimi K2 носил корону. Китайцы из Qwen выкатили обнову Qwen3-235B-A22B-Instruct-2507, которая их подвинула.
Самое интересное даже не в цифрах, а в подходе. Они официально разделили модели на Instruct и Reasoning. Эта — чистый Instruct. Зачем? Да потому что, по их словам, гибриды пока получаются "ни рыба, ни мясо" и проигрывают специализированным версиям.
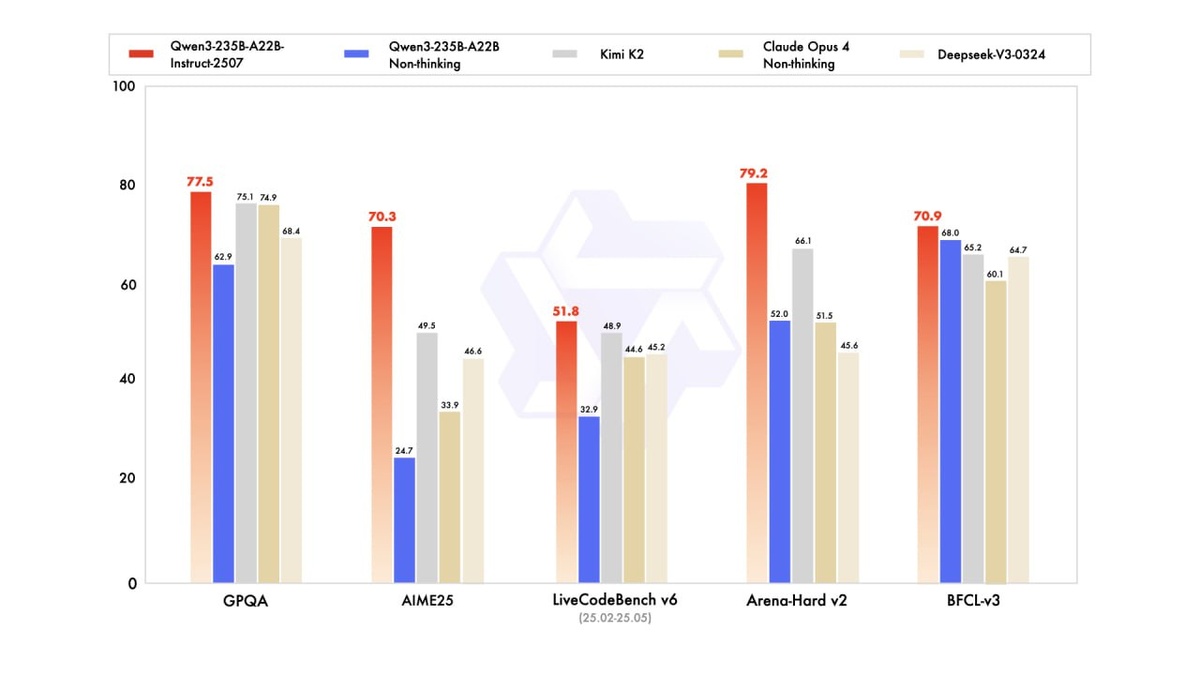
Что на счёт метрик в задачах программирования?
💻 LiveCodeBench: 51.8. Для понимания: у Kimi K2 — 48.9, у Claude Opus — 44.6. Разница не в пределах погрешности, а вполне себе ощутимая.
🌍 MultiPL-E (код на разных языках): 87.9. Это уровень Claude Opus, который многие считают эталоном.
🤖 Aider-Polyglot (агентное использование в IDE): 57.3. Тут она чуть уступает Claude (70.7), но всё ещё наравне с другими топами и показывает, что заточена под реальные задачи, а не только синтетические тесты.
🚀 Как им это удаётся?
Вся магия в MoE (Mixture of Experts). Из 235 миллиардов параметров в любой момент времени активны только 22 миллиарда. Это делает модель гораздо более лёгкой и быстрой на инференсе, чем можно было бы подумать. А главное — это прямой намёк, что скоро эту мощь дистиллируют в модели поменьше. Так что праздник на улице простых смертных с одной-двумя RTX на борту точно будет.
Ещё они мощно вкладываются в агентное применение и tool calling через свою библиотеку Qwen-Agent. То есть её можно не просто просить написать функцию, а встраивать в сложные рабочие процессы, давать доступ к инструментам и заставлять работать, а не только болтать.
Погонять бесплатно тут | Веса на Hugging Face