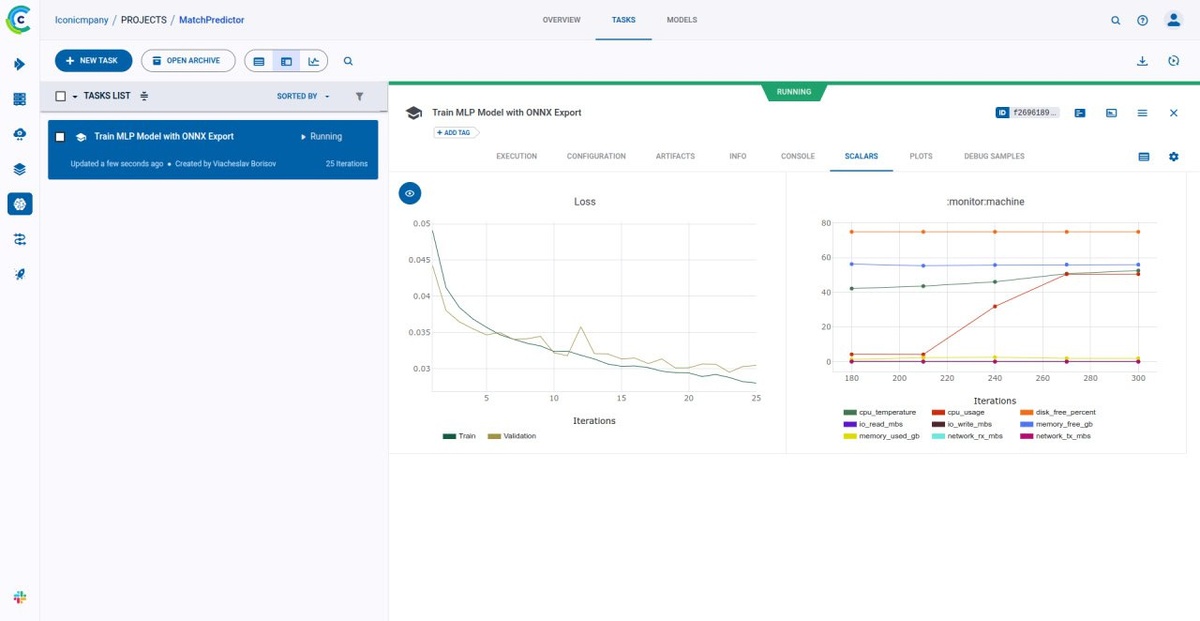
Так выглядит в ClearML график функции потерь при обучении MLP модели по векторам специалиста и вакансии. С каждой итерацией ошибка (MSE) уменьшается. Таким образом мы хотим сделать пред-матчинг специалистов. ONNX модель в отличии от LLM работает быстро и дешего.
Так выглядит в ClearML график функции потерь при обучении MLP модели по векторам специалиста и вакансии.
С каждой итерацией ошибка (MSE) уменьшается. Таким образом мы хотим сделать пред-матчинг специалистов. ONNX модель в отличии от LLM работает быстро и дешего.