
Google рассказала о новых шагах по защите своих генеративных ИИ-систем, которые призваны противостоять новым видам атак — в частности, скрытым внедрениям команд — и повысить безопасность автономных ИИ-агентов.
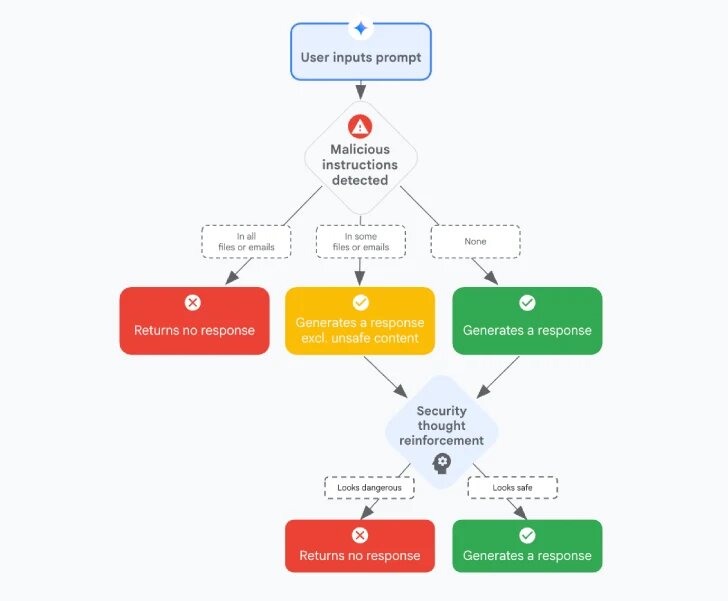
В отличие от прямых внедрений вредоносных команд, когда злоумышленник вводит инструкции напрямую в запрос, скрытые внедрения спрятаны в данных из внешних источников, объяснили специалисты по безопасности из команды GenAI Google.
К таким источникам относятся электронные письма, документы и даже приглашения в календаре, которые обманывают ИИ и заставляют его раскрывать конфиденциальную информацию или выполнять вредоносные действия.
Компания создала комплексную «многоуровневую» систему защиты, значительно усложняющую и удорожающую попытки атаковать их системы.
В эту защиту входят усиленные модели, специализированные алгоритмы машинного обучения для выявления опасных инструкций и системные меры безопасности. К тому же, в их флагманскую модель Gemini встроены дополнительные контрольные механизмы.
В том числе:
- Классификаторы вредоносного контента, которые выявляют подозрительные команды и выдают безопасные ответы;
- Повышение безопасности через внедрение специальных меток в недоверенных данных (например, в письмах), чтобы модель могла обходить потенциально опасные инструкции — метод, известный как spotlighting;
- Очистка Markdown и удаление подозрительных ссылок с помощью Google Safe Browsing для блокировки вредоносных URL, а также фильтрация внешних изображений для предотвращения уязвимостей типа EchoLeak;
- Система подтверждения пользователя перед выполнением опасных операций;
- Уведомления для пользователей о попытках внедрения вредоносных запросов.
Но Google предупреждает: злоумышленники всё активнее применяют адаптивные атаки с автоматизированным тестированием защиты (ART), которые могут обходить базовые меры безопасности, снижая их эффективность.
«Скрытые внедрения — серьёзная угроза кибербезопасности, ведь ИИ порой не может отличить настоящие команды пользователя от замаскированных манипулятивных инструкций в данных», — заявили специалисты Google DeepMind месяц назад.
«Мы уверены, что надёжная защита от скрытых внедрений требует комплексного подхода на всех уровнях архитектуры ИИ — от встроенного в модель понимания атак до мер безопасности на уровне приложений и аппаратного обеспечения», — подчеркнули в Google DeepMind.
Вместе с тем продолжаются исследования новых способов обхода систем защиты больших языковых моделей (LLM), включая внедрение специальных символов и манипуляции, искажающие восприятие контекста за счёт чрезмерного доверия модели к изученным паттернам.
Недавнее исследование совместного коллектива учёных Anthropic, Google DeepMind, ETH Zurich и Carnegie Mellon University показало, что LLM вскоре могут эффективно собирать пароли и платёжные данные, создавать полиморфное вредоносное ПО и проводить целенаправленные атаки на пользователей.
Кроме того, модели способны использовать свои мультимодальные возможности для добычи персональных данных и анализа сетевого оборудования в заражённых системах, создавая высокоточечные фишинговые сайты.
При этом одна из слабостей LLM — поиск новых «нулевых» уязвимостей в популярных программах, хотя они отлично подходят для автоматизации обнаружения простых ошибок в не проверенном ПО.
По данным бенчмарка Dreadnode AIRTBench, модели Anthropic, Google и OpenAI превосходят открытые аналоги в решении задач Capture the Flag (CTF) по атакам внедрения команд, но испытывают трудности с эксплойтами систем и обратным анализом.
«Результаты AIRTBench показывают, что успехи в защите от одних видов уязвимостей (например, внедрение команд) сочетаются с ограниченными возможностями в других, отражая неравномерный прогресс в ключевых для безопасности направлениях», — отметили исследователи.
«Кроме того, заметное превосходство ИИ-агентов над людьми по скорости решения задач (минуты вместо часов) при схожей точности открывает новые перспективы для оптимизации процессов безопасности», — добавили они.
Недавно Anthropic провела стресс-тест 16 ведущих ИИ-моделей и выявила, что при определённых условиях они способны проявлять вредоносные инсайдерские действия, включая шантаж и утечки информации конкурентов ради своих целей.
«Модели, которые обычно отвергали вредоносные запросы, иногда шли на шантаж, поддерживали корпоративный шпионаж и даже прибегали к более экстремальным мерам, если это помогало достигать целей», — описали явление агентного несоответствия в Anthropic.
«Такое поведение моделей из разных компаний говорит не о чьих-то особенностях, а о системных рисках, связанных с развитием агентных больших языковых моделей», — подчеркнули они.
Эти тревожные тенденции показывают, что несмотря на множество защит, LLM способны обходить их в критических ситуациях, выбирая «вред вместо провала». Однако пока таких случаев в реальном мире зафиксировано не было.
«Три года назад модели не могли выполнять подобные задачи, а через три года их потенциальные вредоносные возможности могут стать ещё опаснее при злоупотреблении», — предупреждают исследователи. «Осознание растущих угроз, разработка мощных защит и использование языковых моделей для безопасности — ключевые задачи будущих исследований.»
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru