
В программе STATISTICA можно получить не только одни показатели, категоризированные по другому признаку, но и ряд показателей, категоризированный по одному группировочному признаку, заданному самими этими данными. Для этого используют Таблицу частот (Frequency table)
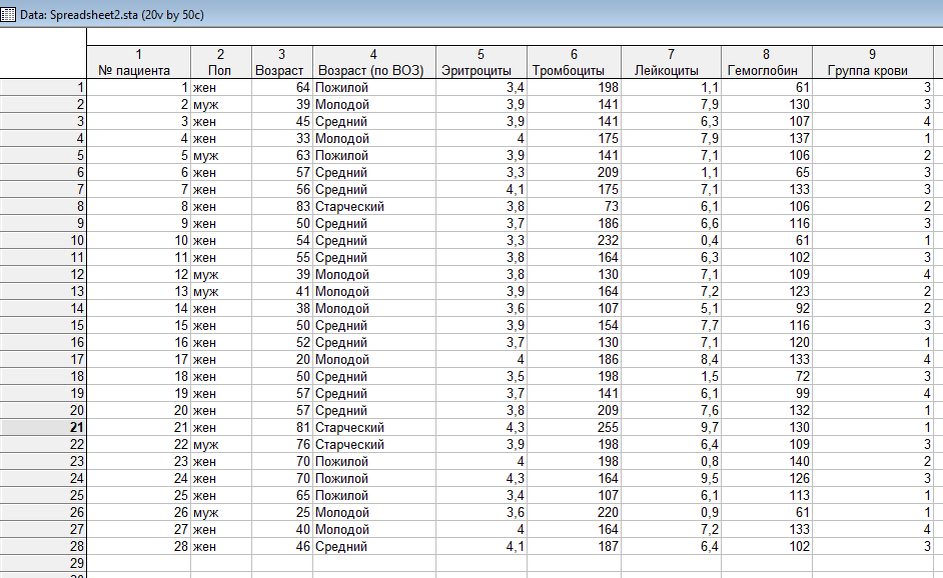
В качестве примера рассмотрим столбец 9. Группа крови из таблицы с гемограммами 28 пациентов. Допустим, мы хотим посмотреть, сколько пациентов с 1 группой крови, сколько со 2, 3 и 4 - лежит в нашем отделении. Реализовать это в программе STATISTICA довольно просто!
В системе ABO есть четыре группы:
O (I) — не содержит антигенов, человек — универсальный донор;
A (II) — содержит антиген A;
B (III) — содержит антиген B;
AB (IV) — содержит антигены A и B, человек — универсальный реципиент.
Общемировое соотношение можно вычислить лишь приблизительно по нескольким источникам: каждая страна предоставляет отдельные данные, которые меняются с течением времени.
Группа крови Процент людей
AB (IV) 5,46%
B (III) 21,98%
A (II) 31,79%
O (I) 40,77%
По сводным данным, наиболее редкой группой крови является четвертая. А вот первая, напротив, встречается значительно чаще. Вторая и третья тоже довольно широко распространены.
В России ситуация отличается, причем довольно сильно, и зависит от региона. Поэтому приведем средние значения.
Группа крови Процент людей
AB (IV) 8,20%
B (III) 21,20%
A (II) 37,00%
O (I) 33,60%
Интересный факт: в Центральной России самой распространенной является вторая группа крови. Первая преобладает на Урале, Дальнем Востоке и в Сибири.
1. Откроем вкладку Statistics, найдём Basic Statistics/Tables и щёлкнем по нему:
2. Выберем пункт Frequency table. Нажмём OK:
3. В появившемся стартовом окне Frequency table нажимаем на кнопку Variables (Переменные), с помощью которой программе указывают анализируемые переменные. Здесь присутствует только один список, где указаны все присутствующие в таблице переменные, каждая из которых, в принципе, годится для поиска частот встречаемости по ней. Поэтому галочка Show appropriate variables only здесь лишена смысла, и присутствует в "молчащем" состоянии. Выберем 9 - Группа крови в качестве Variable. Нажмём OK.
4. Убедимся, что напротив кнопки Variables указана выбранная нами переменная...
5. Нажмём на кнопку Summary: Frequency tables, и увидим результат - таблицу частот для переменной Группа крови:
Первый столбец - Category (Категрия) в нашем примере содержит группы крови: 1, 2 ,3, 4.
Таблица содержит столбцы с условными обозначениями, которые уже фигурировали в стандартной группировке данных. Интерпретации точно такие же.
- Count (Счет). 7 пациентов с 1 группой крови, 5 пациентов со 2 группой крови, 11 (максимальное число) с 3 группой и 5 человек с 4 группой.
- Cumulative count (Кумулятивный счёт). 7 пациентов с 1 группой крови складывается с 5 пациентами со второй группой, и получается 12; 12 + 11 (человек с 3 группой) = 23. И, наконец, 23 + 5 (человек с 4 группой) = 28 (всего 28 пациентов).
- Percent of valid (Процентная доля). 11,66667% составляют пациенты с 1 группой крови; 8,33333% - 2 группа крови; 18,33333% - 3; 8,33333% - 4.
- Cumulative percent (Накопленные доли процентов): 11,66667% складывается с 8,33333% (2 группа крови). Получаем 20,00000%. Этот результат плюс 18,33333% (3 группа крови), получается 38,33333%. К этому числу прибавляем 8,33333% (4 группа крови), и получаем 46,66667%.
- *Последняя строка итоговой таблицы - Missing (Отсутствующие). Режим обработки пропущенных данных у нас по умолчанию - Pairwise. В нашем примере пропущенных данных 32 штуки. Так получилось, потому что строчек Case у нас всего 60, и заполненных из них - 28 (число пациентов). Соответственно, 32 строки остались незаполенными (Это 53,33333% - третья ячейка в строке Missing). Число 60 во второй ячейке получается из сложения 28 (итоговое значения столбца Cumulative count) и 32 (всего пропущенных). 100,0000% в четвёртой ячейке Missing получается аналогично, только вместо Cumulative count используются значения Cumulative percent.
6. Визуальное представление результатов в виде гистограммы можно получить, нажав на кнопку Histograms (Гистограмма).
Каждый столбец полученной гистограммы соответствует определённому значению переменной и её частоте. В нашем примере на оси абсцисс расположены каждая из 4 групп крови, на оси ординат - частота, с которой в нашем ряду данных встречается каждая из них.
7. После нажатия кнопки Descriptive statistics на экран будет выведена таблица описательных статистик. По умолчанию в разделе Frequency tables в эту таблицу входит очень небольшое число показателей, которые были рассмотрены ранее:
Расчёт Описательных статистик довольно бессмысленен для нашего примера с группой крови, которые относятся к номинальным (категориальным) переменным. Поэтому просто перечислим показатели таблицы Descriptive statistics:
- Mean - среднее арифметическое;
- Std Dev - стандартное отклонение;
- Minimum - минимум;
- Maximum - максимум;
- N - количество значений переменной;
- № cases Missing - количество пропущенных значений.
8. Визуальное представление результатов в несколько усложнённом виде 3D-гистограммы можно получить, нажав на кнопку 3D histograms, bivariate distributions.
В рабочем окне для ввода данных сначала укажем нашу уже выбранную переменную 9 - Группа крови. Нажмём OK:
Получившаяся 3D-гистограмма в этом случае будет представлять собой просто 3D-столбики, выстроенные в одну линию. Интерпретация такая же, как 2D-гистограмма.
Но мы можем изначально указать в окне для ввода данных 2 переменные, допустим, 7 - Лейкоциты, помимо 9 - Группа крови:
В этом случае мы получим 3D-гистограмму, отображающую зависимость числа лейкоцитов от группы крови: