
В исследовании Microsoft выявили кратное превосходство передовых LLM в точности диагнозов, сравнивая со средними результатами терапевтов. При этом ресурсов на решение проблемы ИИ затрачивает меньше. Резюмируем выводы учёных.
Методы и метрики
В систему для оценки ИИ исследователи внесли 304 сложных диагностических случая из авторитетного медицинского журнала NEJM. В отличие от статичных тестов, здесь имитировали реальный приём у врача: модель или живой специалист получали краткое описание проблемы, должны были самостоятельно запрашивать дополнительные сведения (историю болезни, результаты осмотра) и назначать анализы. При этом вычислялась примерная стоимость каждого шага.
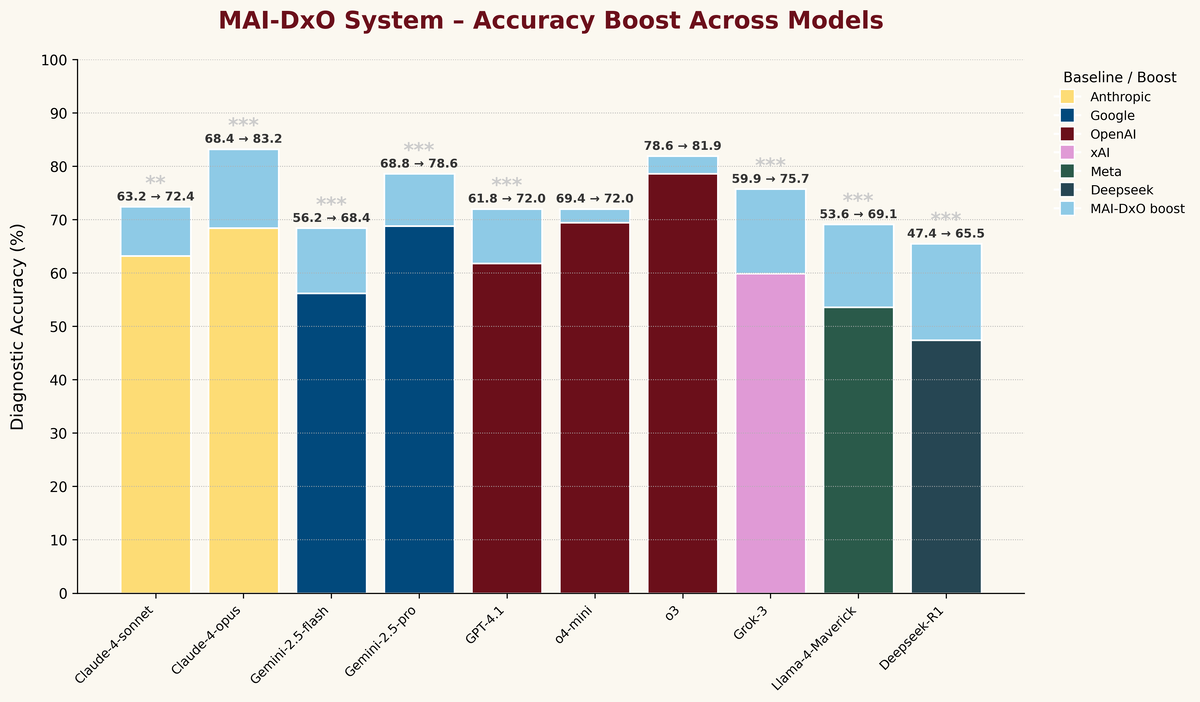
Эксперты создали интересный алгоритм для решения задач — MAI-DxO. Он эксплуатирует передовые языковые модели в режиме «нейроконсилиума». ИИ разбивается на несколько модулей, исполняющих роли виртуальных экспертов с разными точками зрения. Они выдвигают гипотезы, критикуют их между собой, предлагают альтернативы и стараются оптимизировать издержки. В итоге конфигурация с OpenAI o3 показала 80% точности при затратах в $2397 на случай. Практикующие врачи поставили 20% правильных диагнозов при средних расходах до $2963.
То есть правильный вердикт LLM выносит в четырёх из пяти случаев, средний терапевт — в каждом пятом. Заметна разница не только в точности, но и в экономичности. Метод внутренней нейродискуссии оказался эффективен: с ним повышаются успехи любой нейронки. Так, даже GPT-4.1, не обладающая механизмом размышлений CoT, улучшила результат с 61,8 до 72 процентов, Grok-3 — с 59,9 до 75,7 процента, Llama-4-Maverick — с 53,6 до 69,1 процента, а Deepseek-R1 — с 47,4 до 65,5 процента.
О чём говорит тренд?
Прогресс ИИ в этом исследовании объясняется сочетанием мощной аналитики, доступа к огромным объёмам данных и способности рассматривать проблему с разных сторон. Имитация врачебного консилиума позволяет системе не зацикливаться на первоначальной гипотезе. Одна часть модели ищет противоречия в выводах другой, предлагая альтернативные диагнозы.
В целом, пусть это и не готовая замена человеческой экспертизы, свежий взгляд ассистента нередко бывает полезен. Полностью полагаться на такой инструмент пока не стоит, ведь ошибки всё равно неизбежны. Однако ИИ даёт специалистам «второе мнение», помогающее расширить перспективу и заметить детали, упущенные при стандартном подходе.