Вот несколько эффективных способов удалить дубликаты строк в таблице PostgreSQL, сохраняя только одну запись для каждого уникального ID: WITH duplicates AS ( SELECT id, ROW_NUMBER() OVER(PARTITION BY id ORDER BY ctid) AS row_num FROM your_table ) DELETE FROM your_table WHERE (id, ctid) IN ( SELECT id, ctid FROM duplicates WHERE row_num > 1 ); CREATE TABLE your_table_new AS SELECT DISTINCT ON (id) * FROM your_table ORDER BY id, some_timestamp_column; -- можно указать критерий для выбора какой дубликат оставить DROP TABLE your_table; ALTER TABLE your_table_new RENAME TO your_table; DELETE FROM your_table WHERE ctid NOT IN ( SELECT MIN(ctid) FROM your_table GROUP BY id ); DO $$ DECLARE batch_size INTEGER := 10000; BEGIN LOOP DELETE FROM your_table WHERE ctid IN ( SELECT ctid FROM ( SELECT ctid, ROW_NUMBER() OVER(PARTITION BY id ORDER BY ctid) AS rn FROM your_table ) t WHERE rn > 1 LIMIT batch_size ); EXIT WHEN NOT FOUND; COMMIT; END LOOP; END $$; SELECT id, COUNT(*) FROM your_table GROU
Вот несколько эффективных способов удалить дубликаты строк в таблице PostgreSQL, сохраняя только одну запись для каждого уникального ID:
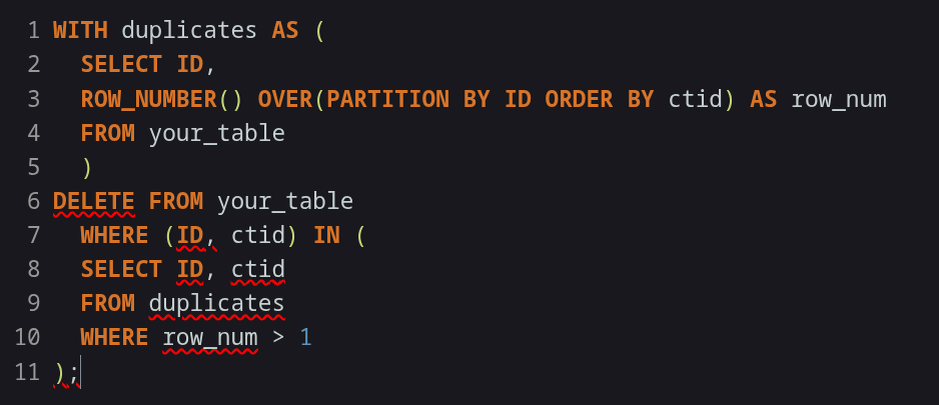
1. Использование CTE (Common Table Expression)
WITH duplicates AS (
SELECT id,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY ctid) AS row_num
FROM your_table
)
DELETE FROM your_table
WHERE (id, ctid) IN (
SELECT id, ctid
FROM duplicates
WHERE row_num > 1
);
2. Создание новой таблицы без дубликатов
CREATE TABLE your_table_new AS
SELECT DISTINCT ON (id) *
FROM your_table
ORDER BY id, some_timestamp_column; -- можно указать критерий для выбора какой дубликат оставить
DROP TABLE your_table;
ALTER TABLE your_table_new RENAME TO your_table;
3. Удаление с использованием подзапроса
DELETE FROM your_table
WHERE ctid NOT IN (
SELECT MIN(ctid)
FROM your_table
GROUP BY id
);
4. Для больших таблиц (пакетное удаление)
DO $$
DECLARE
batch_size INTEGER := 10000;
BEGIN
LOOP
DELETE FROM your_table
WHERE ctid IN (
SELECT ctid
FROM (
SELECT ctid,
ROW_NUMBER() OVER(PARTITION BY id ORDER BY ctid) AS rn
FROM your_table
) t
WHERE rn > 1
LIMIT batch_size
);
EXIT WHEN NOT FOUND;
COMMIT;
END LOOP;
END $$;
Важные замечания:
- ctid - внутренний идентификатор строки в PostgreSQL
- Для определения какую копию оставить, используйте ORDER BY в DISTINCT ON
- Перед удалением сделайте резервную копию: CREATE TABLE your_table_backup AS SELECT * FROM your_table;
- Для ускорения операции создайте временный индекс: CREATE INDEX temp_idx ON your_table(id);
Проверка дубликатов перед удалением:
SELECT id, COUNT(*)
FROM your_table
GROUP BY id
HAVING COUNT(*) > 1;
Выберите подходящий метод в зависимости от размера таблицы и требований к производительности.