
Всем привет! На связи енотик 🦝 И сегодня в этой короткой статье (с примерами кода) я продолжу историю создания своего 💬 чата на Python. Сегодня я расскажу как у меня получилось записывать звук в Python и сжимать его с помощью библиотеки Opus.
Сперва небольшое предисловие 🫠 Я хотел во второй части стати описать весь процесс записи, обработки и отправки аудио. Но в процессе написания статьи понял, что в одну это всё не влезет да и выглядеть будет громоздко 🫣 Так что в этой части мы рассмотрим запись и сжатие записанного звука.
🌊вВодная часть
В своей предыдущей статье я начал рассказывать о создании своего чата с нуля на Python. В ней я коротко описал возможности чата и чего всё началось.
Сегодня я бы хотел подробнее остановиться на аудиозвонках, так как именно их создание отняло у меня львиную долю времени.
Любой опытный разработчик, прочитав то, как я реализовал механизм звонков и передачи аудио, закидает меня камнями. Не надо, позялувста, я только учусь 😌
Передо мной стояла задача передать голос человека по интернету с помощью Python, да ещё и в режиме реального времени. Давайте для начала разберемся как вообще в теории работает передача аудио в реальном времени.
Аудиозвонок (или аудиопоток) - это непрерывная передача крошечных отрезков аудио по сети от отправителя к получателю. Крошечные отрезки ещё называют чанками, в контексте аудиозвонка - аудиочанками. Аудиочанк - это крошечный отрезок звука (обычно 20 миллисекунд).
💡 И если один аудиочанк это 20 мс, то 1 секунда аудио это 50 таких чанков.
Ну, становиться немного понятнее. Теперь нужно понять, как записывать эти крошечные отрезки аудио в Python.
🎙Как записать голос в Python?
Здесь нам на помощь приходит библиотека PyAudio, которая превращает ваш микрофон в цифровой конвейер.
Устанавливается библиотека через PIP:
pip install pyaudio
Далее инициализируем объект PyAudio:
import pyaudio
pa = pyaudio.PyAudio()
После нужно инициализировать объект потока записи:
input_stream = pa.open(
format=pyaudio.paInt16,
channels=1,
rate=16000,
input=True,
frames_per_buffer=960,
stream_callback=record_chunk
)
А теперь разберемся что за аргументы передаются в метод инициализации потока записи:
- format — это формат звука. В примере используется моно аудио 16 бит.
- channels — количество аудиоканалов. У нас это моно, то есть один канал.
- rate — частота дискретизации, то есть количество выборок аналогового сигнала в секунду. В нашем случае это 16000 выборок в секунду. Чем выше этот показатель, тем лучше качество звука.
- input = True — поток настроен на запись звука.
- frames_per_buffer — размер чанка в байтах.
- stream_callback — метод, который выполняется после записи каждого чанка.
Как узнать какая будет длинна у записанного чанка? Мы знаем размер чанка и частоту дискретизации. Чтобы узнать длину чанка, нужно разделить частоту дискретизации на размер чанка.
У нас получиться следующая длина:
16000/960=16.6 мс.
Приведу скриншот полного кода записи звука и вывода в консоль длины каждого чанка, дополнительно буду считать общий размер всех записанных чанков (пригодиться в дальнейшем).
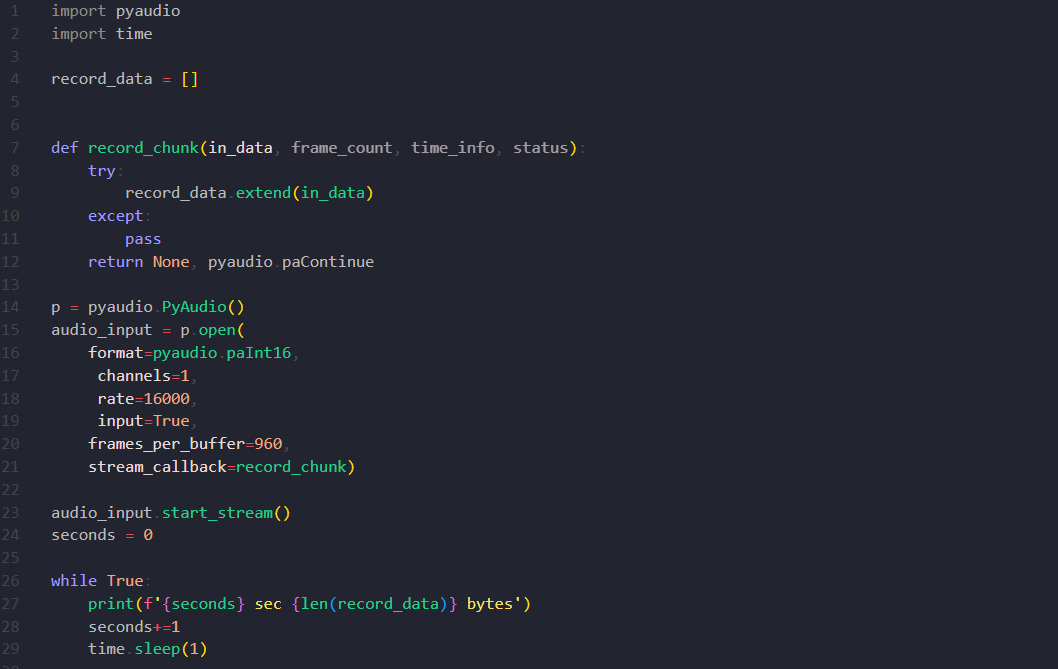
Что в этом коде происходит? Я запускаю поток записи звука с микрофона и получаю в методе Callback чанки с микрофона и записываю их в массив record_data. А в бесконечном цикле программы каждую секунду вывожу размер массива record_data в байтах.
Вот что получается при работе программы
Получается, что за 12 секунд записи у нас вышло 382 тысячи байт или 382 Кб. Довольно внушительный размер для передачи по сети. Если передавать пакеты с таким размером по сети, то возможны не только задержки, но и артефакты в самом аудио. Да и к тому же нагрузка на сеть будет сильная. Поэтому давайте эти чанки сжимать, благо для этого уже созданы различные кодеки. Например мы рассмотрим использование кодека Opus.
🔈Что такое Opus и как он сжимает аудио?
Opus (ранее известный как Harmony) — это аудиокодек, предназначенный для сжатия звука с потерями. Он идеально подходит для использования в приложениях, работающих в режиме реального времени в интернете, к примеру в приложениях для аудиосвязи.
Этот кодек использует большинство популярных мессенджеров в режиме звонков, например Telegram. И для создания аудиозвонков в своем чате я так же решил использовать Opus. Данный кодек умеет неплохо адаптироваться под условия сети: если соединение хорошее, он передает звук в высоком качестве, а если сеть перегружена — снижает качество, чтобы избежать задержек и прерываний.
Как же нам использовать возможности кодека Opus в нашем приложении на Python. Для этого нам понадобиться библиотека-мост между Opus и Python opuslib-next. Устанавливается эта библиотека так же через PIP:
pip install opuslib-next
Далее добавим в программу кодировщик из библиотеки Opus
encoder = opuslib_next.Encoder(
fs=16000, # Частота записи (16 кГц достаточно для речи)
channels=1, # Один канал (моно)
application='voip' # Режим для голосовой связи
)
Некоторые параметры нам уже знакомы:
- sample_rate - частота дискретизации (она должна быть такой же как и у записываемого звука, у нас это 16000)
- channels - количество каналов записи (также должно соответствовать записываемому звуку, у нас моно, поэтому 1)
- application - это параметр отвечающий за режим кодировки звука (в нашем случае voip отлично подходит, так как будет обеспечивать максимальное сжатие для передачи голоса в реальном времени)
Не зря я написал выше, что библиотека opuslib-next является мостом между Python и Opus. Для полноценной работы с кодеком Opus нам ещё потребуется сама библиотека opus.dll. Библиотека собирается из исходников, но можно попытаться найти её в сети в уже собранном виде. Я как человек любящий, в некотором роде, сложности, собрал её из исходников.
Если будет интересно, да и у меня будет время, опишу процесс сборки Opus для каждой ОС. Так как при разработке своего чата для Windows, Linux и macOS я собирал эту библиотеку на каждой ОС отдельно.
Дорабатываем код с учетом того, что файл библиотеки лежит рядом с исполняемым файлом. Добавляем Encoder от Opus и проверяем результат. Ниже приведен доработанный код.
Перед тем как положить записанные чанки в record_data мы их сжимаем через Opus. Метод encoder.encode() принимает два агрумента: данные, которые нужно сжать и размер этих данных (т. е. размер записанного чанка). И результаты работы весьма впечатляют.
За те же 12 секунд работы вышло 19,7 Кб, что примерно в 20 раз меньше!
Это лишь крошечная часть всего алгоритма аудиозвонков. Понадобиться несколько статей, чтобы описать его полностью. Сейчас мы реализовали запись и сжатие аудиочанков. Далее нужно упаковать их в пакет, указав получателя, и отправить на сервер-ретранслятор (почему ретранслятор - расскажу в будущих статьях). Также нужно описать алгоритм приема пакетов с аудиочанками, алгоритм декомпрессии и наконец воспроизведение.
Помимо этого, необходимо уделить внимание:
- ✅ усилению громкости (уже реализовано),
- ✅ шумоподавлению (также реализовано),
- ⏳ динамичной буферизации (в процессе разработки),
- 🛑 алгоритму компенсации эха (так называемый AEC фильтр, создать который у меня так и не получилось до сих пор).
А на сегодня всё! В следующих статьях я продолжу описывать процесс работы аудиозвонков 🔊 В дальнейших публикациях, если интересно, опишу процесс обмена картинками (недавно была добавлена такая возможность).