Google представляет Gemma 3n: Революция в мобильном ИИ
Google официально выпустила Gemma 3n — новую архитектуру ИИ, специально разработанную для мобильных устройств и edge-вычислений.
🔘Ключевые особенности Gemma 3n
Мультимодальность из коробки
Gemma 3n изначально поддерживает:
- Изображения
- Аудио
- Видео
- Текст
Оптимизация для мобильных устройств
Модель доступна в двух размерах:
- E2B (эффективно 2 млрд параметров) — требует всего 2GB памяти
- E4B (эффективно 4 млрд параметров) — требует 3GB памяти
При этом фактическое количество параметров составляет 5B и 8B соответственно, но благодаря архитектурным инновациям модели работают с отпечатком памяти, сравнимым с традиционными 2B и 4B моделями.
🔘Архитектура
MatFormer: Одна модель — множество размеров
В основе Gemma 3n лежит архитектура MatFormer (Matryoshka Transformer) — вложенный трансформер для эластичного вывода. Как матрёшка: большая модель содержит меньшие, полностью функциональные версии себя.
Per-Layer Embeddings (PLE)
Инновация Per-Layer Embeddings позволяет значительной части параметров (эмбеддинги) загружаться и вычисляться эффективно на CPU, в то время как только основные веса трансформера (~2B для E2B и 4B для E4B) находятся в памяти акселератора.
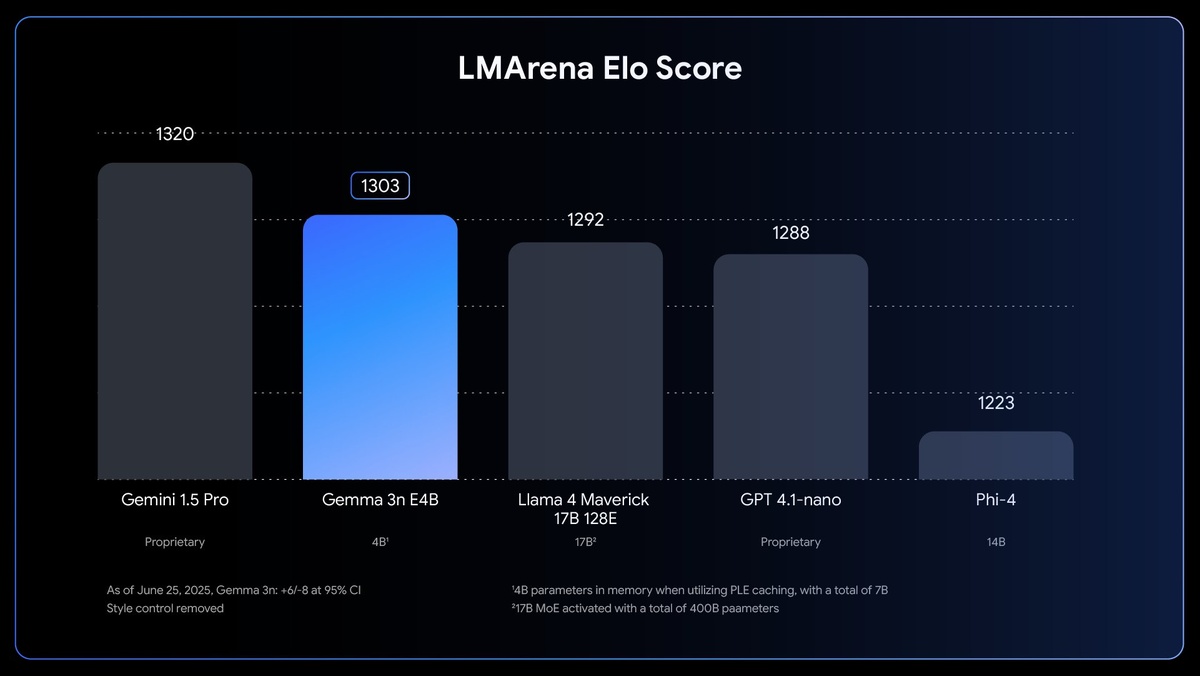
🔘Производительность
Gemma 3n E4B достигает LMArena score более 1300, становясь первой моделью менее 10 млрд параметров, достигшей этого показателя.
Модель поддерживает:
- 140 языков для текстового понимания
- 35 языков для мультимодального понимания
- Улучшенные возможности в математике, программировании и логических рассуждениях
🔘Новые возможности аудио
Gemma 3n использует продвинутый аудио-энкодер на основе Universal Speech Model (USM), который обеспечивает:
- Автоматическое распознавание речи (ASR)
- Автоматический перевод речи (AST)
- Особенно сильные результаты для перевода между английским, испанским, французским, итальянским и португальским языками
🔘MobileNet-V5: Новый стандарт компьютерного зрения
Новый vision-энкодер MobileNet-V5-300M предлагает:
- Поддержку множественных разрешений (256x256, 512x512, 768x768)
- До 60 кадров в секунду на Google Pixel
- 13x ускорение с квантизацией на Google Pixel Edge TPU
- 46% меньше параметров и 4x меньший отпечаток памяти
🔘Поддержка экосистемы
Gemma 3n поддерживается популярными инструментами:
- Hugging Face Transformers
- llama.cpp
- Google AI Edge
- Ollama
- MLX
- Docker
- NVIDIA NeMo Framework
🔘Gemma 3n Impact Challenge
Google запускает конкурс Gemma 3n Impact Challenge с призовым фондом $150,000. Цель — создать продукт, использующий уникальные возможности Gemma 3n для улучшения мира.
🔘Как начать работу
1. Попробуйте в Google AI Studio: aistudio.google.com
2. Скачайте модели: Hugging Face или Kaggle
3. Изучите документацию: ai.google.dev/gemma/docs/gemma-3n