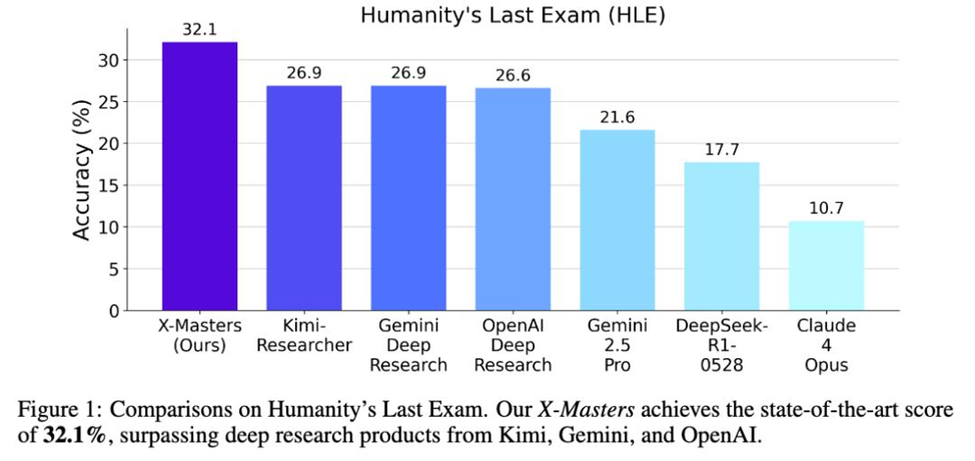
Рекорд на самом сложном AI-тесте
В июле 2025 года китайская команда из Шанхайского университета Цзяо Тун и DeepSeek совершила настоящий прорыв: их система X-Masters, основанная на открытом модели DeepSeek-R1, впервые в истории набрала 32,1 балла на тесте HLE (Humanity’s Last Exam, «Последний экзамен человечества»). Это абсолютный рекорд — до этого ни одна модель не преодолевала даже 27 баллов, а изначально результат выше 10 считался невозможным.
Что такое «Последний экзамен человечества»?
HLE — это уникальный и крайне сложный тестовый набор, созданный AI Safety Center и Scale AI. В нём более 3000 задач, собранных от 1000+ учёных из 500 организаций, включая ведущие университеты, исследовательские институты и компании. Вопросы охватывают математику, физику, биомедицину, инженерию, социальные науки и требуют не только глубоких знаний, но и сложного рассуждения, а иногда — анализа изображений и схем. Примерно 42% задач — по математике, по 11% — по физике и биомедицине.
Тест задуман так, чтобы его не могли пройти ни поисковые системы, ни стандартные LLM — вопросы не поддаются простому поиску, требуют оригинального мышления и точных ответов.
Как устроен X-Master и почему он победил?
X-Master — это инструментально-усиленный reasoning-агент, построенный на DeepSeek-R1-0528. Его ключевая особенность — умение динамически переключаться между внутренним рассуждением и использованием внешних инструментов (например, Python-кода, библиотек NumPy/SciPy, веб-поиска и парсинга данных).
Вся архитектура имитирует работу настоящего исследователя: если агент не может решить задачу «в уме», он пишет и исполняет код, анализирует результаты и продолжает рассуждение.
Вся коммуникация между агентом и инструментами реализована через специальные токены:
Thoughts
…
для размышлений, … для кода, <execution_results>…</execution_results> для результатов. Код исполняется в песочнице, а результаты возвращаются в контекст модели, что позволяет строить сложные цепочки рассуждений.
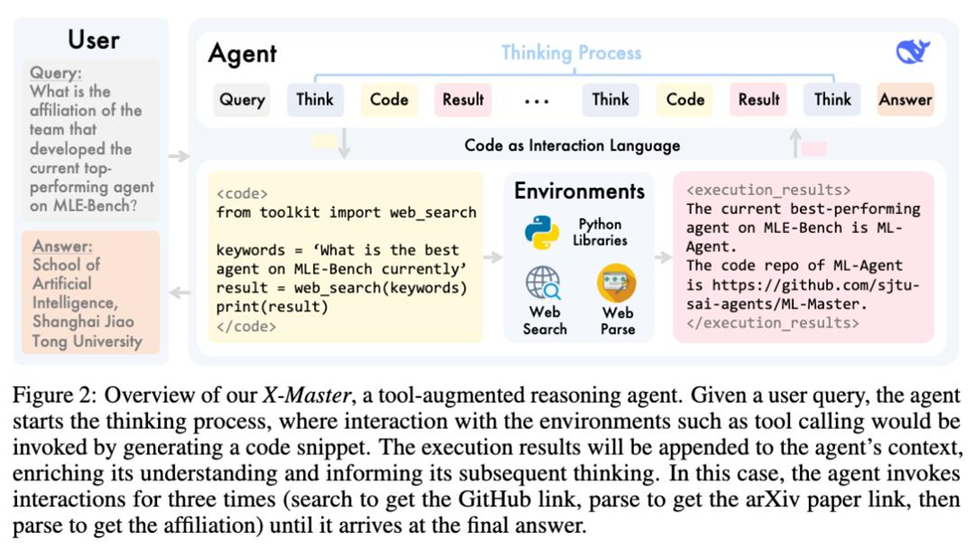
Чтобы повысить эффективность, команда внедрила механизм «инициализирующего промпта» — в начале работы агенту явно объясняют, что он может и должен использовать внешние инструменты, писать код и анализировать результаты. Это позволяет даже не дообученным под агентные задачи моделям вести себя как полноценные reasoning-агенты.
Многоагентный workflow: X-Masters
Для максимального результата команда разработала X-Masters — систему, где несколько агентов работают параллельно и последовательно. На первом этапе (dispersed) несколько solver-агентов генерируют разные решения, а критики (critic) ищут ошибки и предлагают улучшения.
Затем rewriter-агенты объединяют лучшие идеи, а selector выбирает финальный ответ. Такая архитектура напоминает rollouts в reinforcement learning: сначала широкая генерация, потом сужение и отбор.
Результаты и сравнение
В тесте HLE (текстовая часть, 2518 задач) X-Masters показал 32,1% точности — это выше всех предыдущих результатов (Kimi-Research и Gemini Deep Research — 26,9%). Особенно впечатляет, что DeepSeek-R1 не дообучался под агентные задачи, а просто был интегрирован в продуманную архитектуру.
В биомедицинских задачах X-Masters также обошёл специализированные системы Biomni (17,3%) и STELLA (26%), показав 27,6% точности на всех 222 задачах. В отдельном биологическом тесте TRQA-lit (choice) X-Master достиг 62,1%, а X-Masters workflow — 67,4%, что выше даже систем, использующих сотни специализированных инструментов.
Почему это важно?
Во-первых, это первая система, преодолевшая 30 баллов на HLE — самом сложном AI-тесте в мире. Во-вторых, решение полностью открыто: код и методика доступны на GitHub, а статья опубликована на arXiv. В-третьих, успех достигнут с помощью отечественной модели и архитектуры, что особенно важно на фоне доминирования OpenAI и Google.
Что дальше?
Эксперты отмечают, что DeepSeek-R1 и X-Master — это только начало: следующая версия (V4) обещает ещё более мощные агентные функции. Сам подход — усиление reasoning-моделей инструментами и многоагентными workflow — становится новым стандартом в AI.
«Последний экзамен человечества» — это не просто тест, а вызов для всей индустрии. Китайские исследователи показали, что открытые решения могут не только конкурировать, но и опережать мировых лидеров.
Источник: github.com/sjtu-sai-agents/X-Master
Хотите создать уникальный и успешный продукт? СМС – ваш надежный партнер в мире инноваций! Закажи разработки ИИ-решений, LLM-чат-ботов, моделей генерации изображений и автоматизации бизнес-процессов у профессионалов.
ИИ сегодня — ваше конкурентное преимущество завтра!
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru