Когда я подумываю о покупке нового ноутбука, в голове всегда крутится вполне разумный вопрос — сколько он на самом деле должен стоить? Вместо того чтобы бесконечно сравнивать сайты и предложения, можно всего за пару минут с помощью Python и простой линейной регрессии узнать, где цена честная, а где — явный перегиб.
Зачем создавать свой собственный "ценовой калькулятор" ноутбуков?
Вручную разбираться в тысячах моделей и характеристиках — удовольствие на любителя. Компьютеры мне нравятся, но тратить дни на муторные сравнения совсем не хочется. Гораздо проще дать несколько команд программе — и получить ориентировочную справедливую цену по вашим критериям: сколько нужно памяти, какое разрешение экрана или скорость процессора.
Ассортимент огромный, а ручной анализ — занятие неблагодарное. Думаю, мой опыт пригодится всем, кто, как и я, не любит переплачивать за лейбл или маркетинговые сказки.
Я больше не куплю ноутбук без этих 10 функций — и вам не советую!
Всего пара пунктов, но эти вещи должны быть стандартом по умолчанию!
Базовое знание линейной регрессии из школьного курса натолкнуло меня на мысль — ведь можно "обучить" модель предсказывать цену по ключевым параметрам. Python — идеальный инструмент: прост даже для новичков и открывает огромное поле для экспериментов с данными.
Какие Python-библиотеки нужны для анализа данных?
Я использовал стандартные Python-инструменты, которые легко поставить в отдельную среду — например, с помощью Mamba. Системный Python обычно служит нуждам самой ОС (напоминаю: в Linux лучше его не трогать). Для экспериментов стоит создать виртуальное окружение, например через VirtualEnv.
Первая библиотека — NumPy. Без неё не обойтись: это основа для численных расчетов, статистики и линейной алгебры.
Вторая — Pandas. Позволяет работать с таблицами (фреймами данных) — удобно фильтровать, группировать и анализировать любые показатели.
Для визуализации отлично подойдёт Seaborn: делает наглядные графики, гистограммы и диаграммы буквально в пару строк.
Как быстро и красиво визуализировать данные с Python и Seaborn
Даже если вы новичок, красивые графики вам по плечу — стоит только попробовать!
Ещё один мой секрет — библиотека Pingouin для статистики. Не нужно вспоминать сложные формулы: все популярные методы, включая множественную регрессию, реализованы прямо "из коробки". Очень удобно, когда нужно учесть сразу несколько характеристик.
Всё это можно настроить почти на любом UNIX-подобном дистрибутиве (и даже на Windows, если воспользоваться WSL). Как установить — подробностей полно в интернете.
Я предпочитаю работать в Jupyter Notebook — там легко тестировать код, смотреть результаты и хранить все свои наработки. Пример скрипта выложил на своем GitHub — можно заглянуть за подробностями, которые не поместились в статью.
Если используете Mamba, создайте новое окружение буквально одной командой в терминале Linux — это проще, чем кажется.
Где брать данные о ноутбуках?
Конечно, можно собирать характеристики вручную, заходя на сайты магазинов, но это уйдёт уйма времени — и не факт, что получится всё свести в одну таблицу. К счастью, кто-то этим уже занимался до нас.
На Kaggle можно найти обширную таблицу с нужными параметрами: тактовая частота процессора, объём оперативной памяти, размеры накопителей и разрешение экрана по обеим осям — всё, что нужно для анализа.
Цены в базе, правда, указаны в евро — но пересчитать в рубли не проблема: достаточно взять актуальный курс (например, на июль 2025 года). Для удобства сразу делаю перерасчёт в рубли или в доллары по текущему курсу.
Как "натренировать" модель для вычисления честных цен?
Когда окружение готово и нужная база ноутбуков загружена — дело за малым: подключаем необходимые библиотеки:
Пара строк — и NumPy, Pandas, Seaborn и Pingouin готовы к работе. Префиксы np, pd, sns, pg ускоряют процесс. Строчки с символом "%" — это команды Jupyter, чтобы графики отображались прямо в ноутбуке, а не в отдельных окнах.
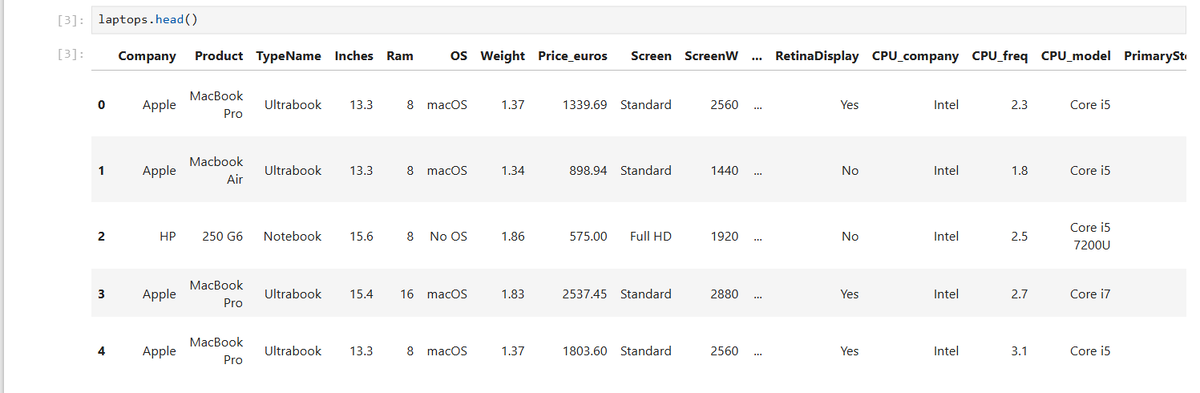
Данные подгружаются через Pandas, структуру смотрю с помощью head():
Функция describe() покажет сводную статистику для всех числовых столбцов:
Появятся средние значения, медианы, стандартные отклонения и диапазоны — в общем, всё для быстрой оценки разброса цен и характеристик.
Чтобы визуально оценить, как разбросаны данные, строю гистограмму в Seaborn:
Видно, что "хвост" распределения тянется вправо — дорогих ноутбуков меньше, но они тянут среднюю цену вверх.
Дальше учим модель на формуле:
цена = a * (частота процессора) + b * (объём оперативной памяти) + c * (диагональ экрана в дюймах) + ...
Здесь a, b, c — это коэффициенты, их-то и вычисляет регрессия. Получается воображаемая гиперплоскость в пространстве характеристик — сложнее прямой линии, но задача хорошо решается средствами Python.
чтобы понять, какие параметры действительно значимы, запускаю регрессию в Pingouin по наиболее "весомым" признакам: размеру, процессору, разрешению экрана, массе, объёму накопителя и т.д.
В левой колонке — значения коэффициентов, в правой — степень влияния характеристики на финальную цену. В этом примере объём оперативной памяти оказался главным "драйвером" стоимости. r2 — показатель качества модели: у меня вышло примерно 0,66, что вполне неплохо.
Зная коэффициенты, легко подставить свои показатели и моментально вычислить "справедливую" цену для нужной комплектации. Вот пример простой функции для такого расчёта:
Если что — вторую строку следует записывать с отступом, но формат публикации не позволяет показать это здесь красиво.
Сколько на самом деле стоит "бренд" в ноутбуке?
В моём анализе я рассчитывал цену только по железу, но любопытно — насколько бренд влияет на итоговую сумму? Проверяем это с помощью дисперсионного анализа (тест Краскела-Уоллиса). Он отлично подходит, потому что распределение цен сильно неравномерное, как видно на гистограмме — и всё делается через Pingouin.
Суть: тестирует гипотезу — а есть ли связь между брендом и стоимостью?
Результат говорит сам за себя: p-значение равно нулю. Значит бренд реально влияет на цену, и нулевая гипотеза отклоняется. Обычно p-value показывают в экспоненциальной форме (для наглядности), но, чтобы не перегружать показатели, я округлил его.
В итоге Python позволил мне быстро рассчитать "объективную" стоимость любого ноутбука по характеристикам — и наглядно увидеть, сколько приходится доплачивать за модный логотип. Его библиотеки делают подобный анализ простым и быстрым — а вручную получить такие выводы почти нереально.
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru