
Представьте: вы обучили нейросеть, добились 99% точности на тренировочных данных… и полностью провалились на реальных. Что произошло?
Поздравляем — вы столкнулись с переобучением. Один из самых частых, подлых и коварных врагов в машинном обучении.
В этой статье — всё по делу. Объясним, что такое переобучение, как его распознать, почему оно возникает и как с ним бороться. А ещё — реальные примеры, инструменты и советы из практики.
——————————————————————
📌 Что такое переобучение — простыми словами:
Переобучение (overfitting) — это когда модель слишком хорошо запоминает обучающие данные, но плохо работает на новых.
🔧 Пример из жизни:
Допустим, вы готовитесь к экзамену. Вместо того чтобы понять тему, вы зубрите ответы на конкретные вопросы. На экзамене вам попадается что-то похожее, но не один в один — и вы теряетесь.
Вот и модель так же: выучила конкретные примеры наизусть — и провалилась, когда встретила новые.
📈 Как выглядит переобучение на графике:
Возьмём две метрики:
- Train Accuracy — точность на обучающей выборке
- Validation Accuracy — точность на валидационной выборке
В начале обе растут. Но через некоторое время:
- Train Accuracy продолжает расти
- Validation Accuracy — падает
Это и есть сигнал переобучения.
🧠 Почему возникает переобучение?
Вот основные причины:
1. Слишком сложная модель
Много слоёв, параметров, высокая выразительная мощность.
2. Мало данных
Чем меньше данных — тем проще их “выучить”.
3. Отсутствие регуляризации
Модель не ограничивается и может переадаптироваться.
4. Долгое обучение
Модель успевает “переучить” данные.
5. Шумные или нерелевантные признаки
Модель учится запоминать шум, а не паттерны.
💥 Пример: классификация собак и кошек:
Вы обучаете нейросеть распознавать, где собака, а где кошка. В выборке 500 изображений, и в каждой собака — на зелёной траве, а кошка — на ковре.
Модель “думает”, что зелёный фон = собака.
На новых данных (где кошка на траве) — провал.
Вывод: модель выучила контекст, а не объект. Это — переобучение.
🔨 Как бороться с переобучением: 7 стратегий:
- 1. Регуляризация
👉 Что это?
Методы, которые ограничивают “свободу” модели, чтобы она не подгоняла себя под конкретные данные.
🔧 Инструменты:
- L1/L2-регуляризация — добавляют штраф за слишком большие веса
- Dropout — случайное обнуление нейронов во время обучения
- Early stopping — остановка обучения при ухудшении на валидации
- 2. Увеличение данных (Data Augmentation)
👉 Что это?
Создание дополнительных вариантов обучающих примеров путём трансформаций.
🔧 Инструменты:
- ImageDataGenerator (Keras)
- Albumentations (CV)
- NLPAug (тексты)
- Snorkel (weak supervision)
- 3. Снижение сложности модели
Иногда проще — лучше.
- Уменьшите число слоёв
- Уменьшите размер слоёв
- Используйте регуляризацию в архитектуре (например, ResNet vs обычный CNN)
- 4. Early Stopping
Останавливаем обучение, как только видим, что валидация начинает ухудшаться.
- 5. K-Fold Cross Validation
Разделение выборки на несколько частей для оценки устойчивости модели.
Позволяет избежать случайного переобучения на удачной или неудачной валидации.
- 6. Сбор и очистка данных
Иногда лучше не добавлять шум, а удалить его.
- Удалите дубликаты
- Проверьте аномалии
- Балансируйте классы
- 7. Использование простых моделей в начале
Начинайте с базовой модели. Иногда логистическая регрессия даст не хуже результат, чем нейросеть — особенно на табличных данных.
📌 Кейсы из практики:
📁 Кейс 1: нейросеть для прогнозирования оттока клиентов
Компания обучала модель на 5000 клиентов. Использовали глубокую сеть с 10 слоями.
Точность на тренировке: 98%
Точность на валидации: 64%
Что помогло:
- Упростили модель
- Добавили L2-регуляризацию
- Провели feature selection
Результат: 86% на валидации. Переобучение устранено.
📁 Кейс 2: CV-задача — классификация документов
Данные не были размечены точно. Модель запоминала шум и подписи на документах.
Что помогло:
- Удаление шумных признаков
- Data Augmentation
- Использование ResNet вместо кастомного CNN
🧰 Лучшие инструменты и фреймворки для контроля переобучения
🔹 TensorFlow / Keras
- EarlyStopping, Dropout, L2
- TensorBoard: визуализация метрик
- ImageDataGenerator
🔹 PyTorch
- torch.nn.Dropout
- torch.optim с weight decay
- torch.utils.data.DataLoader с аугментацией
🔹 Sklearn
- cross_val_score
- Простые модели (логистическая регрессия, деревья)
🔹 Fastai
- Learner.fit_one_cycle()
- Встроенный early stopping
- Простые методы augs + callbacks
🔹 HuggingFace
- Удобные callback’и
- Built-in eval loss tracking
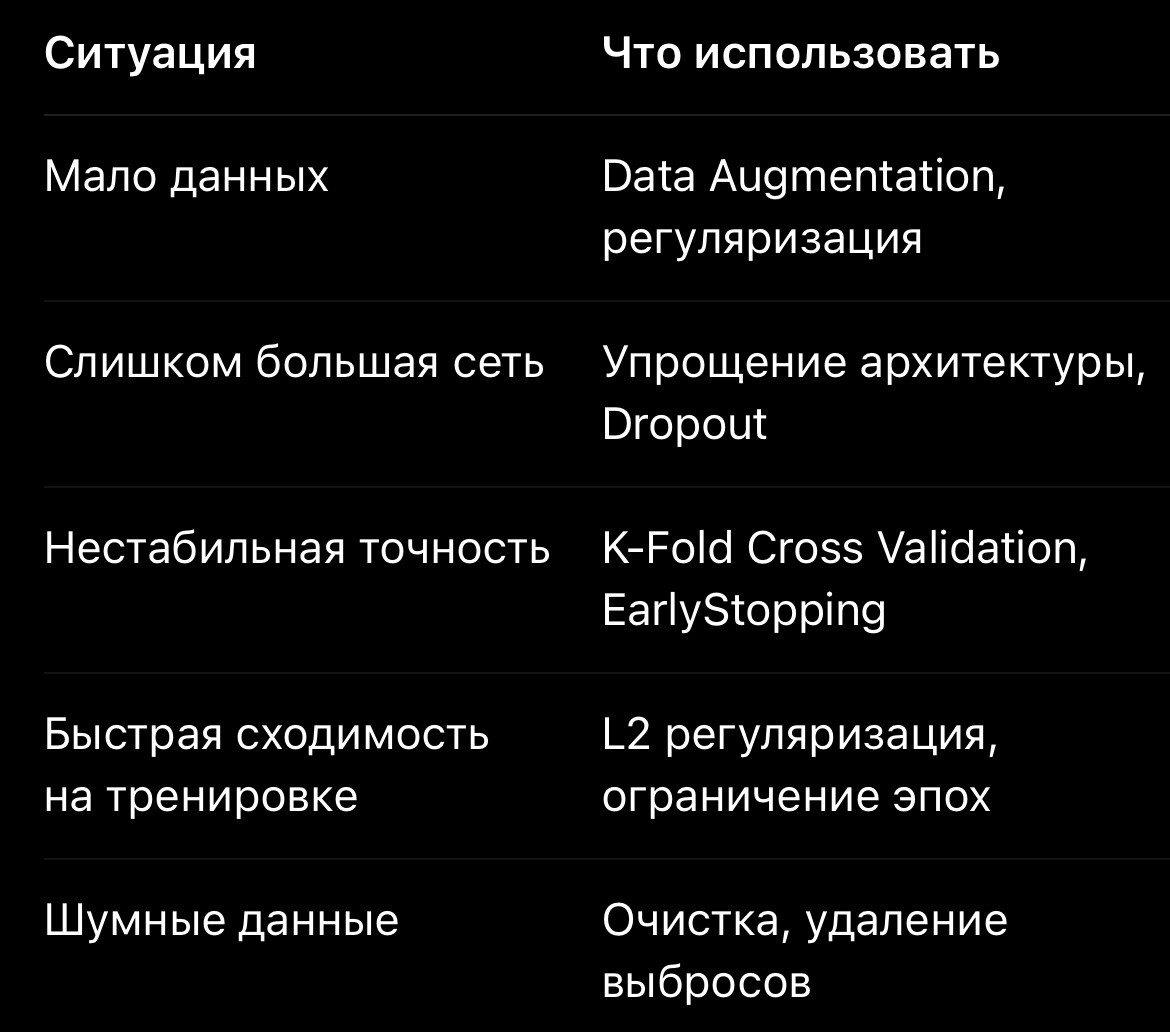
🧭 Рекомендации по выбору метода
📌 Частые ошибки новичков?
- Смотрят только на точность на тренировке
- Не используют валидационную выборку
- Переусложняют модель с самого начала
- Игнорируют визуализацию кривых обучения
- Обучают десятки эпох без контроля
🧠 Что нужно запомнить!
- Переобучение — это нормально. С ним сталкиваются все.
- Лучше недообучение, чем переобучение — его проще исправить.
- Важна валидация, визуализация, контроль за сложностью.
✅ Краткий чеклист перед запуском финальной модели:
- Есть ли разметка валидации?
- Есть ли регуляризация?
- Визуализируются ли метрики?
- Используется ли early stopping?
- Проверена ли модель на новых (real-life) данных?
——————————————————————
Если вы дочитали до этого места — теперь вы точно не попадётесь на переобучение. Но если попадётесь — будете знать, как справиться.