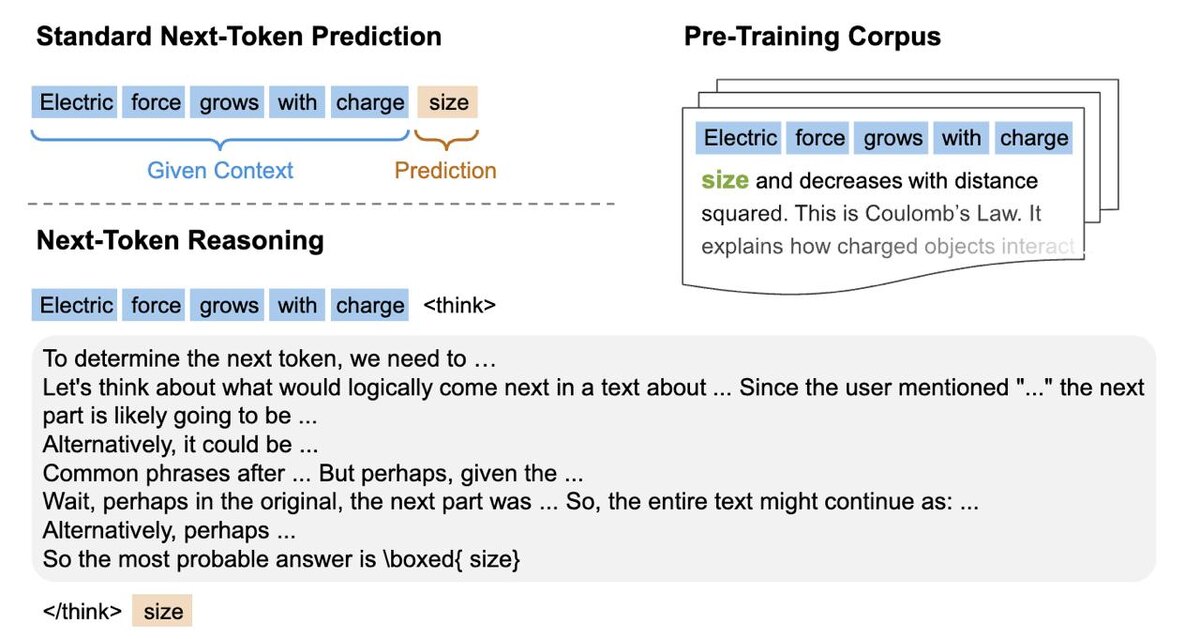
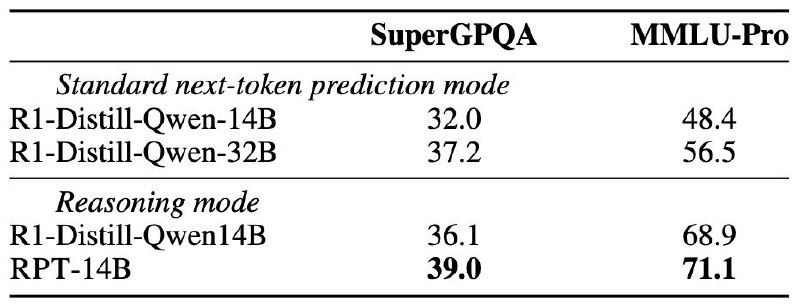
вышла статья с на мой взгляд сбивающим с толку названием "Reinforcement Pre-Training"; с толку оно сбивает потому, что они фактически работают с уже предобученной моделью и просто ее вот так хитро дообучают; хитрость заключается в том, что они стандартную задачу предсказания следующего токена решают с помощью размышлений (как показано на первой картинке); очевидно, что так (предсказывая цепочку рассуждений для каждого токена) было бы очень долго и неэффективно тренировать, поэтому они маленькой моделькой сначала выбирают токены, на которых большая перплексия и дообучаются только на них; за счет этого трюка они на два процента смогли поднять качество на бенчмарках (вторая картинка)
вышла статья с на мой взгляд сбивающим с толку названием "Reinforcement Pre-Training"; с толку оно сбивает потому, что они фактически работают с уже предобученной моделью и просто ее вот так хитро дообучают; хитрость заключается в том, что они стандартную задачу предсказания следующего токена решают с помощью размышлений (как показано на первой картинке); очевидно, что так (предсказывая цепочку рассуждений для каждого токена) было бы очень долго и неэффективно тренировать, поэтому они маленькой моделькой сначала выбирают токены, на которых большая перплексия и дообучаются только на них; за счет этого трюка они на два процента смогли поднять качество на бенчмарках (вторая картинка)