
Google Gemma 3n представляет прорывную технологию в области on-device AI с уникальной архитектурой MatFormer и технологией Per-Layer Embeddings, позволяющую запускать мультимодальные модели с 5-8 млрд параметров, используя всего 2-3 ГБ оперативной памяти на смартфонах и ноутбуках.
Архитектурные инновации Gemma 3n
Google представила Gemma 3n на конференции Google I/O 2025 как новейшую модель семейства Gemma, специально разработанную для эффективной работы на мобильных устройствах. Основой революционной эффективности модели служат три ключевые архитектурные инновации.
MatFormer: Архитектура «матрёшки»
Сердцем Gemma 3n является архитектура MatFormer (Matryoshka Transformer) — уникальное решение с вложенными трансформерами, подобное русским матрёшкам. В процессе обучения модели E4B (4 млрд эффективных параметров) одновременно оптимизируется вложенная подмодель E2B (2 млрд эффективных параметров). Эта архитектура позволяет разработчикам:
- Использовать предварительно извлечённые модели разных размеров для различных задач
- Создавать кастомные модели промежуточных размеров методом «Mix'n'Match»
- Динамически переключаться между режимами производительности в зависимости от нагрузки устройства
Per-Layer Embeddings (PLE): Революция в управлении памятью
Технология Per-Layer Embeddings кардинально меняет подход к использованию памяти. Хотя модели имеют 5 и 8 млрд параметров, PLE позволяет значительной части параметров (эмбеддинги каждого слоя) загружаться и обрабатываться эффективно на CPU, в то время как только основные веса трансформера (около 2B для E2B и 4B для E4B) размещаются в более ограниченной памяти ускорителя (VRAM). Это обеспечивает работу моделей всего с 2-3 ГБ оперативной памяти.
Условная загрузка параметров
Gemma 3n поддерживает условную загрузку параметров, позволяя пропускать загрузку компонентов для аудио или зрения, если они не требуются для конкретной задачи. Это экономит память и ускоряет производительность при работе только с текстовыми данными.
Технические характеристики и возможности
Мультимодальные возможности
Gemma 3n представляет собой мультимодальную модель, способную обрабатывать:
- Текст: Поддержка более 140 языков с контекстным окном 32K токенов
- Изображения: Нормализованные изображения разрешением 256x256, 512x512 или 768x768, кодируемые в 256 токенов каждое
- Аудио: Обработка звуковых данных со скоростью 6,25 токенов в секунду из одного канала
- Видео: Расширенные возможности обработки видео для анализа контента
Производительность и эффективность
Модель демонстрирует впечатляющие показатели производительности:
- Скорость: На 50% быстрее предыдущих моделей Gemma 3 4B при сохранении лучшего качества вывода
- Память: Эффективное использование памяти благодаря технологии PLE — модели работают как 2B и 4B параметрические при фактическом размере 5B и 8B
- Квантизация: Поддержка INT4 и FP16 квантизации для мобильного развёртывания
Практические применения и развёртывание
Мобильные приложения
Gemma 3n открывает новые возможности для мобильного ИИ:
- Медицинские приложения: Анализ медицинских изображений и документации пациентов с полной конфиденциальностью
- Производственные системы: Контроль качества в реальном времени через мобильные устройства без подключения к интернету
- Клиентская поддержка: Мультимодальная обработка запросов клиентов через голос и изображения
Доступность и лицензирование
Модель доступна через различные платформы:
- Google AI Studio: Для экспериментов и прототипирования
- Hugging Face: Открытые веса для исследований и коммерческого использования
- Kaggle: Дополнительные ресурсы и документация
- Android приложения: Интеграция через Google AI Edge SDK
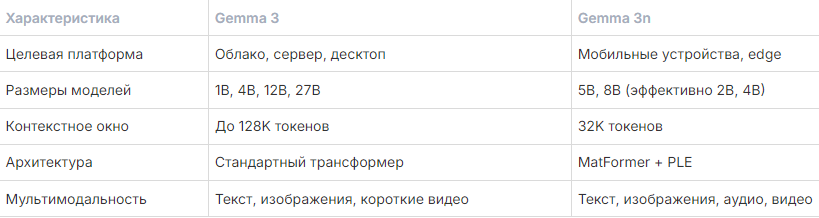
Сравнение с Gemma 3
Gemma 3n и Gemma 3 представляют разные подходы к развёртыванию ИИ:
Значение для будущего мобильного ИИ
Gemma 3n представляет значительный шаг вперёд в демократизации ИИ, делая передовые возможности доступными на обычных потребительских устройствах без зависимости от облачных сервисов. Рынок on-device ИИ ожидается достичь $173,9 млрд к 2030 году, и Gemma 3n позиционируется как ключевая технология этой трансформации.
Модель особенно важна для областей, требующих высокого уровня конфиденциальности и низкой задержки, предлагая полностью локальную обработку без передачи данных в облако. Это открывает новые возможности для персонализированных ИИ-ассистентов, работающих в режиме реального времени прямо на мобильных устройствах.