Настоящий мужик должен родить сына, запрограммировать дерево и построить raid.
зы И пожать сотку.
Приветствую тебя авантюрист! Сегодня мы обсудим довольно важную и не простую тему — организацию файловых хранилищ. Каждый системный администратор и IT-специалист рано или поздно сталкивается с необходимостью изучения более сложных методов и систем для работы с дисками и создания разнообразных схем хранения данных. Использование многодисковых систем и файловых систем, отличных от стандартных NTFS, открывает множество возможностей: скорость, отказоустойчивость, гибкость, экономию места и многое другое. Мы рассмотрим одно из довольно мощных и бесплатных решений — ZFS.
Структура материала
Материал будет разбит на 4 статьи:
- Рассмотрим снапшоты, клоны и реплики. Опять же с примерами.
Необходимый уровень знаний
Уверенное знание и понимание работы носителей данных в операционных системах Linux. Уверенное знание и понимание, как работают файловые системы, что это такое и для чего. Базовые знания и умения работы с RAID-массивами.
Снапшоты
Снапшот — это моментальная копия файловой системы или тома, не требующая дополнительного места на физическом диске. Пространство диска начинает использоваться только тогда, когда в снапшоте и реальных данных начинают появляться различия. До тех пор снапшот не занимает ни байт места. Учитывая, что большая часть данных в файловых «помойках» не меняется десятилетиями, это вполне удобно.
Поехали экспериментировать. Для простоты я создам простейший пул из одного виртуального устройства.
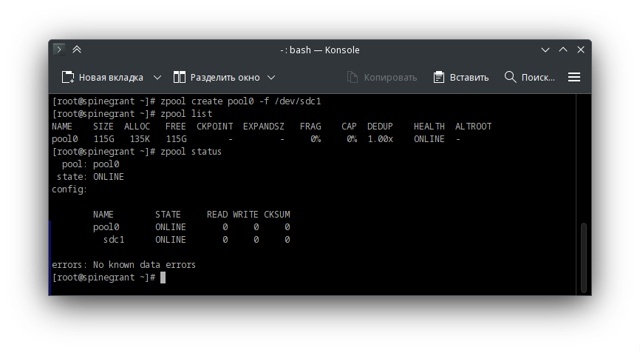
Далее я создам пару файловых систем для наглядности, так как снапшоты делаются именно для файловых систем.
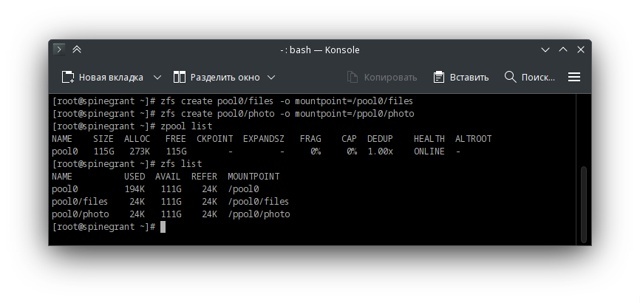
Да, я отпечатался в точке монтирования для файловой системы pool0/photo, но это нам не критично.
Замечательно, маэстро, у нас есть пул pool0 и три файловых системы (ты же помнишь, что корневая файловая система создается автоматически при создании пула). Итак, три файловых системы: /pool0, /pool0/files, /pool0/photo.
Теперь создадим файл в файловой системе /pool0/files и что-нибудь туда запишем.
Замечательно. У нас есть файл с именем some_file, и внутри лежит одно единственное слово Test.
Делаем снапшот нашей файловой системы. Для этого используем следующую команду.
zfs snapshot имяФайловой_системы@имя_снапшота
То есть я выполняю следующую команду.
zfs snapshot pool0/files@backup20250604
Обрати внимание на то, что в названии файловой системы не ставим слеш в начале, если поставить, будет ошибка.
Снапшот создан, сразу смотрим список снапшотов командой
zfs list -t snapshot
Как видно, снапшот создан. Теперь внесём изменения в файл some_file.
Теперь в нашем файле два слова. Что ж, откатим наш снапшот, для этого выполним следующую команду.
zfs rollback pool0/files@backup20250604
Как видно на скрине, файл был восстановлен до исходного состояния, снапшот, к слову, никуда не делся, он остается и теперь будет фиксировать изменения вновь.
Кстати, если нужно увидеть, какие данные хранит снапшот, то для этого можно зайти в каталог «.zfs» в корне файловой системы. Его не видно, но он есть.
Каталог действительно не отображается, но я легко в него зашел, и в каталоге snapshot лежат все наши снапшоты, а внутри измененные файлы.
Снапшоты можно удалять и переименовывать командами zfs destroy, zfs destroy соответственно.
Вот в целом и все, что касается снапшотов. Просто, удобно, эффективно.
Клоны
Развивая инженерную мысль, вполне логично было бы как-то эти самые снапшоты уметь монтировать как полноценные файловые системы. Собственно, для этого и были созданы клоны. Благодаря им можно смонтировать снапшот на чтение/запись и работать с ним как с обычной файловой системой. И да, записывать тоже можно. Если очень упростить, то клон — это копия состояния текущей файловой системы, которая не занимает место на диске. Опять же, до момента, пока нет разницы в данных.
Итак, как и было сказано, клон делается из снапшота. Снапшот у нас уже есть, вот из него давай и сделаем клон. Для этого используем команду.
zfs clone pool0/files@backup20250604 pool0/clone_file
Здесь я указал, какой снапшот используется в качестве исходных данных, и имя файловой системы. Также тут можно поменять точку монтирования новой файловой системы.
Как видишь, создана новая файловая система, внутри находится тот же файл some_file. Пока я не внесу в этот файл какие-либо изменения, на диске не будет потрачено ни байта свободного места.
Кстати, так как клон — это полноценная файловая система в понимании zfs, то нам ничего не мешает сделать ее снапшот, а на основе снапшота сделать новый клон. Тем самым можно создавать ветку бекапов с возможностью получить полное состояние на момент создания клона, и при этом каждый бекап будет занимать только разницу в данных, все одинаковые данные не будут занимать дополнительно ничего. Например, у меня в реальной работе таких бекапов уже около 15, а места они занимают всего около 15% от изначальных данных. То есть 15 ПОЛНОЦЕННЫХ наборов данных по датам, а места всего 15% плюсом.
Из особенностей логично, что снапшот, на основе которого сделан клон, нельзя удалить, пока не будет удален клон. Клон можно удалить командой, как обычную файловую систему zfs.
zfs destroy pool0/clone_file
Реплики ZFS
Собственно, процесс репликации в ZFS выполняет всё то же, что и процесс репликации в других файловых системах и сервисах — это копирование данных из одного пула в другой. У тебя возникнет вполне резонный вопрос: а почему просто не скопировать данные из одного пула в другой? Ответ будет такой: скорость. Не будем вдаваться в дебри работы, в гугле можно найти ответ, почему репликация действительно предпочтительнее. Более того, репликация умеет сериализацию данных в обычный stdout. Это значит, можно сделать репликацию даже по SSH без каких-либо вспомогательных средств.
Собственно все что нужно сделать для запуска процесса репликации это запустить следующий набор команд
zfs send pool0/files@backup20250604 | zfs receive backup_pool/backup
В данном примере мы отправим наш снапшот на пул backup_pool в файловую систему backup_pool/backup. Будет создана полная копия содержимого снапшота.
Итог
Завершаю цикл статей о ZFS. Технология обширная, сходу её освоить сложно. Нужно попробовать, чтобы понять все нюансы. В статьях я постарался охватить основные моменты. Надеюсь, предоставленной мной информации достаточно, чтобы грамотно сформулировать запрос в тот же поисковик или нейронку.
Как обычно, если есть предложения и замечания, милости прошу в комментарии. Удачи, авантюрист.