В июне 2025 года исследователи из Корнелла, CMU и других ведущих институтов представили Eso-LM — первую в мире языковую модель, которая объединяет диффузионные и автогрессивные подходы, обеспечивая беспрецедентный прирост скорости генерации текста.
По словам авторов, Eso-LM генерирует текст до 65 раз быстрее стандартных диффузионных моделей и в 3–4 раза быстрее лучших гибридных решений с поддержкой KV-кэширования. На это уже обратили внимание такие гиганты, как NVIDIA.
Диффузия встречает автогрессию: что это значит?
Традиционные языковые модели строятся по автогрессивному принципу: каждое следующее слово предсказывается на основе уже сгенерированных. Диффузионные модели, наоборот, начинают с зашумленного (частично замаскированного) текста и постепенно «очищают» его, восстанавливая исходную последовательность.
У каждого подхода есть свои плюсы и минусы: автогрессия быстрая благодаря KV-кэшированию, но не может генерировать токены параллельно; диффузия поддерживает параллелизм, но обычно медленнее и требует больше вычислений.
Eso-LM впервые объединяет оба мира: модель учится и генерировать текст по автогрессивной схеме, и восстанавливать его по диффузионной, а главное — использует единый механизм KV-кэширования для ускорения обеих фаз. Это позволяет гибко балансировать между скоростью и качеством генерации.
Как работает Eso-LM?
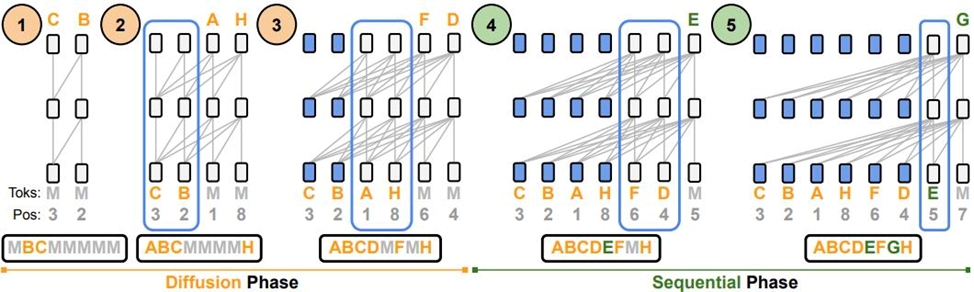
Eso-LM состоит из двух фаз:
- Диффузионная фаза: модель параллельно восстанавливает замаскированные токены в произвольном порядке, используя двунаправленное внимание. Благодаря инновационному KV-кэшированию, вычисления существенно ускоряются.
- Последовательная (автогрессивная) фаза: оставшиеся токены восстанавливаются слева направо, как в классических языковых моделях, с использованием причинного внимания и KV-кэша.
Ключевая инновация — универсальный механизм внимания с настраиваемым bias-матрицей, который позволяет одной и той же архитектуре трансформера динамически переключаться между режимами автогрессии и диффузии. Это реализовано через специальную матрицу A, которая управляет, какие токены могут «видеть» друг друга на каждом шаге.
Гибридное обучение и управление стилем генерации
В процессе обучения Eso-LM половина данных обрабатывается в автогрессивном стиле (предсказание следующего слова по чистому контексту), а другая половина — в диффузионном (маскирование части токенов и их восстановление). На этапе генерации модель может плавно переключаться между этими режимами с помощью гиперпараметра α₀, что позволяет выбирать оптимальный баланс между скоростью и качеством.
Преимущества Eso-LM
- Скорость: на длинных последовательностях (до 8192 токенов) Eso-LM достигает ускорения до 65 раз по сравнению с классическими диффузионными моделями и в 3–4 раза быстрее лучших гибридных решений (BD3-LM).
- Качество: на стандартных бенчмарках (LM1B, OpenWebText) Eso-LM достигает рекордных значений perplexity для диффузионных моделей, вплотную приближаясь к автогрессивным.
- Гибкость: модель не страдает от «mode collapse» при малом числе шагов генерации, что было проблемой для предыдущих гибридных моделей.
- Универсальность: единая архитектура трансформера поддерживает как параллельную, так и последовательную генерацию, что упрощает внедрение и масштабирование.
Почему это важно?
Появление Eso-LM знаменует собой новый этап в развитии языковых моделей. Впервые стало возможным эффективно совмещать параллельную генерацию (для скорости) и автогрессивную (для качества), не жертвуя ни тем, ни другим. Это открывает путь к созданию коммерческих диффузионных языковых моделей, которые уже заинтересовали такие компании, как NVIDIA и Google (последняя представила экспериментальный Gemini Diffusion).
Перспективы и вызовы
Хотя Eso-LM уже демонстрирует впечатляющие результаты, исследователи отмечают, что дальнейшее развитие гибридных архитектур и оптимизация внимания могут привести к еще большему ускорению и улучшению качества генерации. Ведущие AI-лаборатории активно исследуют коммерческие применения диффузионных языковых моделей, а IBM называет их «следующим поколением ИИ».
Заключение
Eso-LM — это не просто очередная языковая модель, а принципиально новый подход к генерации текста, который может изменить правила игры в NLP. Гибридизация диффузии и автогрессии, поддержка KV-кэширования и универсальное внимание делают Eso-LM одним из самых перспективных направлений в развитии больших языковых моделей.
Ссылки на оригинальные материалы и публикации: