
В предыдущих статьях мы рассмотрели основные возможности Perplexity AI, работу с нейросетью на русском языке, установку на разные устройства, сравнение с ChatGPT, генерацию изображений и практическое применение для учебы и работы. Сегодня мы погрузимся в более техническую тему — использование Perplexity API для интеграции возможностей нейросети в ваши собственные приложения и сервисы. Эта статья будет особенно полезна разработчикам и техническим специалистам, которые хотят создавать интеллектуальные решения на базе Perplexity AI.
Что такое Perplexity API и зачем он нужен
Perplexity API — это программный интерфейс, который позволяет разработчикам встраивать возможности Perplexity AI в свои приложения, сайты и сервисы. В отличие от обычного использования через веб-интерфейс или мобильное приложение, API дает вам полный программный контроль над нейросетью и возможность автоматизировать взаимодействие с ней.
Ключевые преимущества использования API:
- Автоматизация — автоматическое выполнение запросов и обработка результатов
- Кастомизация — настройка параметров работы нейросети под ваши задачи
- Интеграция — встраивание возможностей Perplexity AI в ваши существующие продукты
- Масштабирование — возможность обрабатывать большие объемы запросов
Perplexity API имеет важное отличие от многих других API нейросетей — он работает с актуальной информацией из интернета в реальном времени и предоставляет источники. Это ключевое преимущество для приложений, которым требуется доступ к актуальным данным с указанием источников.
Начало работы с Perplexity API
Для использования API Perplexity необходимо пройти несколько подготовительных шагов:
1. Создание и настройка API-группы
Перед началом работы нужно создать API-группу в вашем аккаунте Perplexity:
- Войдите в свой аккаунт Perplexity
- Заполните необходимую информацию о вашей группе, включая название, адрес и налоговые данные
- Настройте способ оплаты для API-запросов, зарегистрировав банковскую карту
2. Генерация API-ключа
Для аутентификации ваших запросов к API необходим API-ключ:
- Перейдите на вкладку API Keys в портале API
- Нажмите кнопку + Create Key для создания нового ключа
- Скопируйте и надежно сохраните сгенерированный ключ — он будет показан только один раз!
Важно отметить, что API-ключ должен храниться в безопасности и не должен публиковаться в открытом коде или репозиториях. Рекомендуется хранить ключи в переменных окружения или специальных хранилищах секретов.
Структура запросов и ответов API
Perplexity API использует RESTful подход и совместим с клиентскими библиотеками OpenAI, что упрощает переход для разработчиков, уже знакомых с API ChatGPT. Основной endpoint для запросов:
https://api.perplexity.ai/chat/completions
Основные параметры запроса:
- model (обязательный) — модель Perplexity для использования
- messages (обязательный) — история диалога и текущий запрос
- temperature — контроль "креативности" (от 0.0 до 1.0)
- max_tokens — максимальная длина ответа
- stream — включение потоковых ответов в реальном времени
- top_p — контроль разнообразия ответов
Доступные модели:
- sonar-pro — флагманская модель с продвинутым поиском и комплексными ответами
- sonar-small/medium — эффективные модели для простых запросов
- mistral-7b — модель с открытым исходным кодом, сбалансированная для различных задач
- codellama-34b — специализированная модель для задач, связанных с кодом
- llama-2-70b — большая модель с широкими возможностями
Примеры интеграции на разных языках программирования
Давайте рассмотрим несколько практических примеров использования Perplexity API на разных языках программирования:
Python
Python — один из самых популярных языков для работы с API. Вот простой пример использования Perplexity API с библиотекой OpenAI:
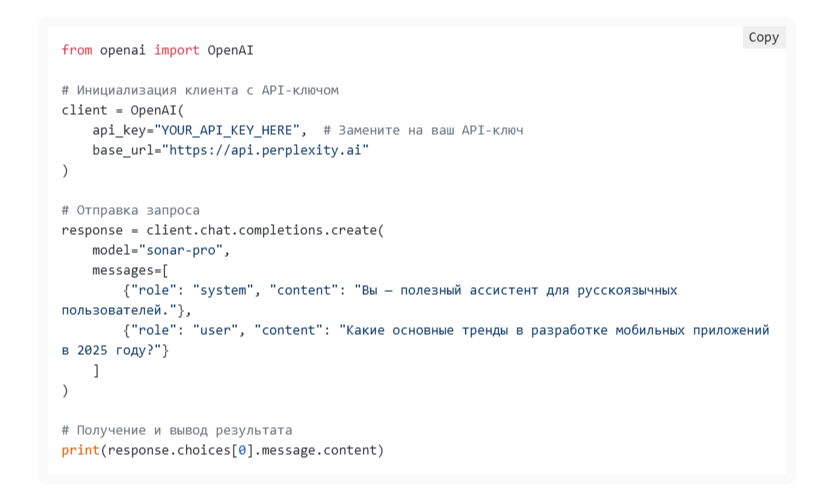
JavaScript/Node.js
Для веб-приложений и серверов на Node.js можно использовать похожий подход:
Оформите годовую подписку Perplexity Pro за 449 рублей и получите доступ к API с расширенными возможностями для своих проектов!
Продвинутые техники использования API
Помимо базовой интеграции, API Perplexity предлагает несколько продвинутых возможностей, которые могут значительно улучшить ваши приложения:
1. Потоковая передача ответов
Потоковая передача позволяет показывать ответы по мере их генерации, создавая более естественный опыт взаимодействия:
2. Управление контекстом диалога
Для многоходовых диалогов важно эффективно управлять контекстом:
3. Структурированные ответы
Для некоторых приложений удобно получать ответы в структурированном формате (например, JSON):
def get_structured_response(query):
response = client.chat.completions.create(
model="sonar-pro",
messages=[
{"role": "system", "content": "Вы — помощник, который предоставляет информацию в формате JSON."},
{"role": "user", "content": f"Предоставьте информацию о {query} в формате JSON со следующими полями: название, описание, основные_характеристики (массив), преимущества (массив), недостатки (массив)."}
]
)
# Извлечение JSON из ответа
answer = response.choices[0].message.content
try:
# Поиск JSON в тексте и парсинг
import re
import json
json_match = re.search(r'```json\n(.*?)```', answer, re.DOTALL)
if json_match:
json_str = json_match.group(1)
else:
json_str = answer
return json.loads(json_str)
except json.JSONDecodeError:
return {"error": "Не удалось распарсить JSON из ответа"}
# Пример использования
result = get_structured_response("Электромобили Tesla")
print(result)
Оптимизация и управление расходами
API Perplexity работает по модели оплаты за использование, поэтому важно контролировать расходы и оптимизировать запросы:
1. Мониторинг использования токенов
Количество токенов напрямую влияет на стоимость запросов. Вот как можно мониторить их использование:
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("perplexity-api")
def log_api_usage(response, prompt):
# Логирование использования токенов
tokens_used = response.usage.total_tokens
prompt_tokens = response.usage.prompt_tokens
completion_tokens = response.usage.completion_tokens
logger.info(f"Использовано токенов: {tokens_used} (запрос: {prompt_tokens}, ответ: {completion_tokens})")
# Примерная стоимость (проверьте актуальные тарифы)
model = "sonar-pro" # Используемая модель
rates = {
"sonar-pro": 0.0005,
"sonar-small": 0.0001,
"sonar-medium": 0.0003
}
estimated_cost = tokens_used * rates.get(model, 0.0005) / 1000
logger.info(f"Примерная стоимость запроса: ${estimated_cost:.6f}")
# Использование при запросе
response = client.chat.completions.create(
model="sonar-pro",
messages=[{"role": "user", "content": "Объясни концепцию машинного обучения"}]
)
log_api_usage(response, "Объясни концепцию машинного обучения")
2. Выбор оптимальной модели
Разные модели имеют различную стоимость и производительность:
- sonar-small: наиболее экономичная модель для простых запросов
- sonar-medium: баланс стоимости и качества для большинства задач
- sonar-pro: используйте только для сложных запросов, требующих актуальной информации
3. Реализация бюджетных ограничений
Для контроля расходов можно реализовать систему бюджетных ограничений:
Обработка ошибок и отказоустойчивость
При работе с любым API важно корректно обрабатывать возможные ошибки. Вот основные типы ошибок, с которыми вы можете столкнуться при использовании Perplexity API:
Основные типы ошибок
- Ошибки аутентификации: неверный API-ключ
- Ограничение скорости: слишком много запросов за короткий период
- Неверные параметры: некорректные имена моделей или значения параметров
- Серверные ошибки: внутренние проблемы API
Реализация логики повторных попыток
Для устойчивости приложения к временным сбоям реализуйте экспоненциальную отсрочку:
import time
import random
def make_request_with_retry(client, messages, max_retries=5):
retries = 0
while retries < max_retries:
try:
response = client.chat.completions.create(
model="sonar-pro",
messages=messages
)
return response
except Exception as e:
# Обработка ошибки ограничения скорости
if "rate_limit" in str(e).lower():
sleep_time = (2 ** retries) + random.random()
print(f"Превышен лимит запросов. Повторная попытка через {sleep_time} секунд...")
time.sleep(sleep_time)
retries += 1
# Обработка ошибки сервера
elif "5" in str(e)[0]: # Серверные ошибки (5xx)
sleep_time = (2 ** retries) + random.random()
print(f"Ошибка сервера. Повторная попытка через {sleep_time} секунд...")
time.sleep(sleep_time)
retries += 1
else:
# Другие ошибки (например, неверные параметры) - не повторяем
raise e
raise Exception(f"Превышено максимальное количество попыток ({max_retries})")
Изучите другие возможности разработки с искусственным интеллектом в нашей статье Решение проблем с Perplexity: типичные трудности и их устранение.