Даже самые продвинутые модели не понимают разницу между «есть» и «нет». В критичных задачах это может стоить жизни.
Представьте: врач смотрит на рентген и видит — «опухоль не обнаружена». Чтобы ускорить работу, он подключает ИИ-модель, анализирующую изображения и тексты. Та выдает похожие случаи... но включает в выборку и те, где опухоль была. Почему? Потому что модель проигнорировала слово «не», а это значит, что диагноз может быть неверным.
MIT провели масштабное исследование и пришли к тревожному выводу: современные vision-language модели, включая CLIP (Contrastive Language–Image Pretraining), не понимают отрицание. Слова вроде «not», «no», «without» или «lacks» они воспринимают так же, как если бы их не было вовсе.
Что показало исследование
Специалисты разработали NegBench — первый полноценный бенчмарк на понимание отрицания в мультимодальных моделях. Он включает:
- Retrieval-Neg: задача поиска изображений по запросам вроде «самолёт без пассажиров» или «улица без машин»;
- MCQ-Neg: множественный выбор между похожими подписями, отличающимися только одной деталью: «есть» или «нет» объекта.
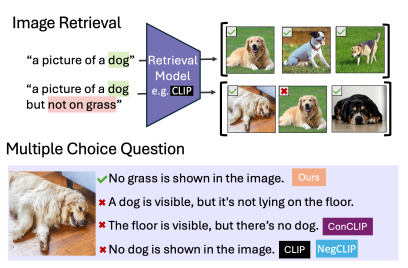
Результаты показали, что:
- в задачах с отрицанием точность CLIP-подобных (изображения-текст) моделей падала на 10–25%;
- в задачах выбора правильного описания модели часто угадывали — результаты были на уровне случайного выбора (25–39%);
- BioMedCLIP теряла до 33% точности при работе с простыми утверждениями вроде «есть затемнение лёгких» vs «нет затемнения».
Иными словами, модель видит слово «not» — и игнорирует его. Везде, где важна точность формулировки, ошибка в понимании отрицания может стоить не только рейтинга, но и безопасности.
Эффект «утвердительного искажения»
VLM-модели, такие как CLIP, работают через совместное эмбеддинг-пространство — картинки и тексты отображаются как векторы, близкие друг к другу, если они соответствуют. Но:
- Почти все обучающие подписи содержат утверждения. Никто не подписывает фото кошки фразой «на этом изображении нет самолёта».
- Модели учатся на этих парах и вырабатывают shortcut: фокусируются на визуальных объектных словах, игнорируя частицы типа «not».
MIT называют это affirmation bias — «смещение в сторону утверждения». Модель считает, что любое слово в подписи должно отражать то, что есть, а не то, чего нет.
PCA-анализ эмбеддингов показал, что для CLIP утверждение «на картинке есть собака» и отрицание «на картинке нет собаки» почти неотличимы по вектору. Для модели — это почти одно и то же.
Решение: обучить на отрицании
Чтобы решить проблему, команда MIT предложила использовать другой подход, основанный на работе с данными. Его суть заключается в том, чтобы включить в обучающие данные образцы с отрицаниями, не изменяя при этом архитектуру модели.
Специалисты создали:
- CC12M-NegCap — 30 млн сгенерированных подписей, где явно указано, чего нет на изображении;
- CC12M-NegMCQ — 40 млн примеров для задач с выбором верного описания, включая жёсткие «обманки» (hard negatives).
Для генерации подписей использовали LLaMA 3.1 и проверку через OWL-ViT, чтобы быть уверенными, что объект действительно отсутствует. В результате:
- точность в Retrieval-Neg выросла с 48% до 57.8%;
- точность в MCQ-Neg подскочила с 39% до 54.4%;
- для специализированной NegCLIP — с 28% до 56.2%.
Синтетические данные с отрицанием работают.
Что делать разработчикам VLM
- Тестируйте свои модели на запросы с отрицанием. Если вы не проверяли, как она отвечает на «не», считайте, что она не отвечает.
- Добавляйте в обучение сэмплы с отрицанием — не шаблонные, а вариативные, приближенные к реальным текстам.
Современные ИИ-модели умеют многое: распознавать, описывать, интерпретировать. Но один из самых базовых языковых элементов — отрицание — до сих пор остаётся для них невидимым.
Исследование MIT — это не просто технический отчёт, а предупреждение. Не всё, что кажется «умным», понимает контекст. И пока модели не научатся слышать «нет» — мы не можем им полностью доверять.
Читайте также: