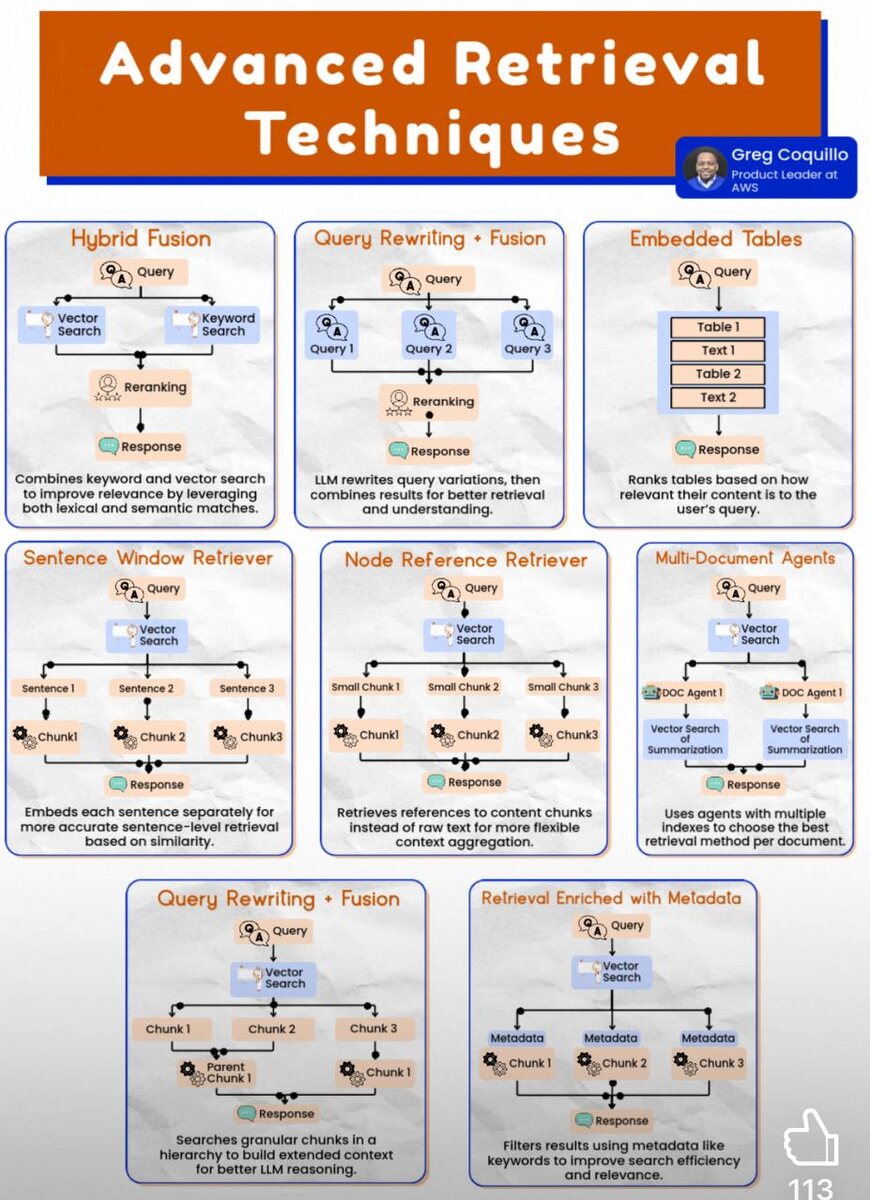
Расширенные методы извлечения данных:
Гибридная модель (Hybrid Fusion)
Объединение поиска по ключевым словам и векторного поиска
Повышает релевантность, используя как лексическое, так и семантическое соответствие.
• Запрос → Ключевой поиск + Векторный поиск → Повторная ранжировка → Ответ
⸻
Переписывание запроса + Объединение (Query Rewriting + Fusion)
LLM переписывает варианты запроса, затем объединяет результаты для улучшенного извлечения и понимания.
• Запрос → Запрос 1/2/3 (сгенерированные LLM) → Повторная ранжировка → Ответ
⸻
Встроенные таблицы (Embedded Tables)
Ранжирует таблицы по степени релевантности содержимого запросу.
• Запрос → Таблица 1 / Текст 1 / Таблица 2 / Текст 2 → Ответ
⸻
Извлечение по предложениям (Sentence Window Retriever)
Встраивает каждое предложение отдельно для более точного извлечения по уровню предложений на основе сходства.
• Запрос → Векторный поиск → Sentence 1/2/3 → Chunk 1/2/3 → Ответ
⸻
Извлечение по ссылкам на узлы (Node Reference Retriever)
Извлекает ссылки на контент-чанки, а не сырой текст, для более гибкой агрегации контекста.
• Запрос → Векторный поиск → Малые чанки → Chunk 1/2/3 → Ответ
⸻
Агенты для многодокументного анализа (Multi-Document Agents)
Используют агентов с несколькими индексами, чтобы выбрать лучший метод извлечения для каждого документа.
• Запрос → DOC Agent 1/2 → Поиск/суммаризация → Ответ
⸻
Иерархия + Переписывание (Query Rewriting + Fusion в иерархии)
Ищет по детализированным чанкам и объединяет в “родительский” контекст для лучшей логики LLM.
• Запрос → Векторный поиск → Chunk 1/2/3 → Родительский Chunk 1 → Ответ
⸻
Извлечение с использованием метаданных (Retrieval Enriched with Metadata)
Фильтрует результаты по метаданным, например ключевым словам, чтобы повысить точность и эффективность.
• Запрос → Векторный поиск + Метаданные → Chunk 1/2/3 → Ответ
⸻
Объяснение и практическая польза
Эти подходы — это расширенные техники RAG (Retrieval-Augmented Generation), применяемые для улучшения извлечения знаний из больших баз данных и документов, особенно при работе с LLM.
Для чего:
• Повышение точности ответов LLM
• Эффективная работа с неструктурированными и полуструктурированными данными
• Улучшение качества поиска в корпоративных базах
Где:
• Создание ИИ-ассистентов
• Документооборот и комплаенс
• Поиск по внутренним базам знаний
• Анализ юридических, финансовых или технических документов