Виртуальная память в операционной системе Linux напоминает искусно спроектированный многоэтажный дом, где каждый этаж имеет свое предназначение, а архитектор продумал каждую деталь до мелочей. Эта система управления памятью стала настоящим прорывом в компьютерных технологиях, позволив программам работать так, словно у них есть неограниченные ресурсы.
Современные приложения требуют все больше оперативной памяти, однако физические ограничения железа остаются реальностью. Здесь на помощь приходит виртуальная память — элегантное решение, которое создает иллюзию бесконечного пространства для данных. Каждый процесс получает собственное виртуальное адресное пространство, изолированное от других программ и защищенное от случайных или злонамеренных вмешательств.
Основы архитектурного устройства
Виртуальная память в Linux построена на принципе многоуровневого преобразования адресов. Представьте библиотеку, где книги хранятся не по порядку на полках, а каталогизированы через сложную систему указателей. Точно так же виртуальные адреса не соответствуют напрямую физическим ячейкам оперативной памяти.
Ядро Linux использует таблицы страниц для трансляции виртуальных адресов в физические. Эти таблицы организованы иерархически: на современных 64-битных архитектурах применяется четырехуровневая схема. Первый уровень называется PGD (Page Global Directory), второй — PUD (Page Upper Directory), третий — PMD (Page Middle Directory), и наконец, четвертый — PTE (Page Table Entry).
Каждая запись в таблице страниц содержит не только физический адрес, но и набор флагов управления. Эти флаги определяют права доступа к странице: можно ли читать данные, записывать их или выполнять как код. Дополнительные биты указывают на присутствие страницы в памяти, ее модификацию и частоту использования.
Механизмы трансляции адресов
Процесс преобразования виртуального адреса в физический происходит с молниеносной скоростью благодаря специализированному аппаратному компоненту — MMU (Memory Management Unit). Этот блок процессора работает как опытный переводчик, мгновенно находящий соответствие между виртуальными и физическими адресами.
Виртуальный адрес разбивается на несколько частей: индексы для каждого уровня таблиц страниц и смещение внутри страницы. Стандартный размер страницы в Linux составляет 4096 байт, хотя система поддерживает и более крупные страницы — hugepages размером 2 МБ или даже 1 ГБ для оптимизации производительности высоконагруженных приложений.
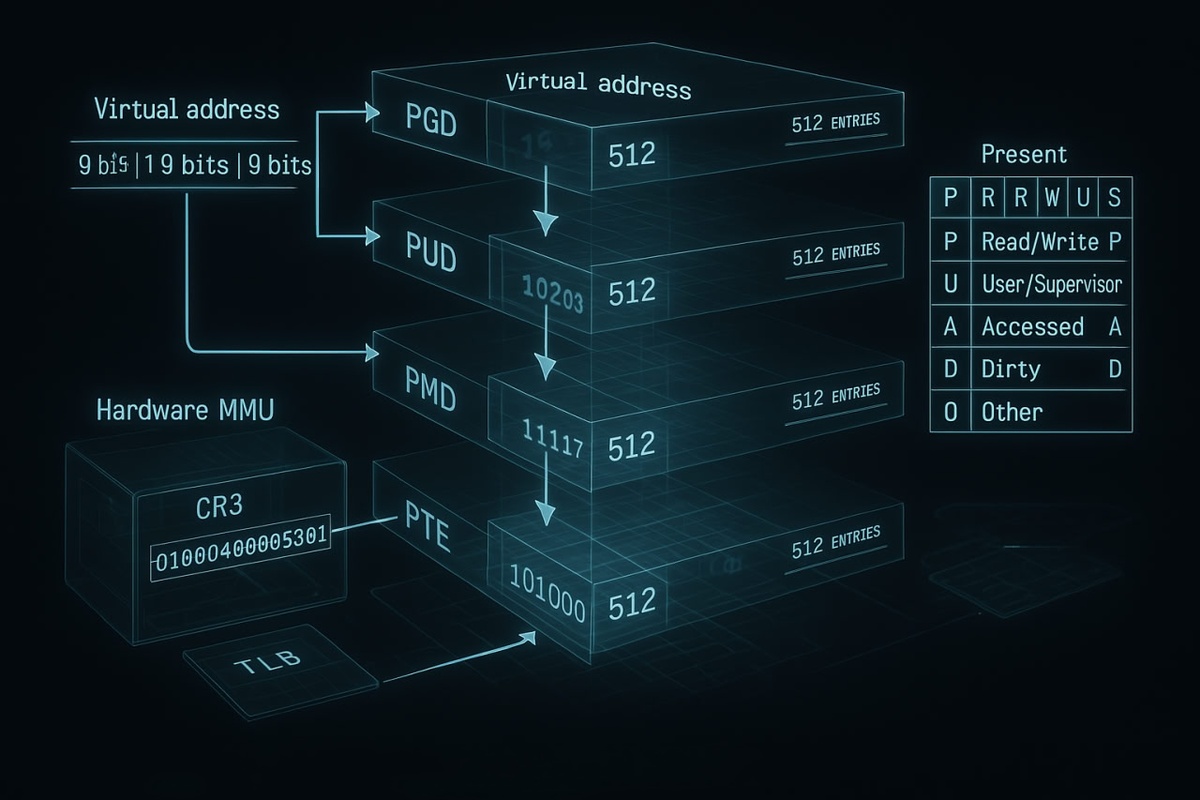
TLB (Translation Lookaside Buffer) служит кэшем для недавно использованных трансляций адресов. Этот небольшой, но чрезвычайно быстрый буфер в процессоре хранит результаты последних преобразований адресов, избавляя от необходимости каждый раз обращаться к таблицам страниц в оперативной памяти. Эффективность TLB критически важна для общей производительности системы.
Управление физической памятью
Ядро Linux разделяет физическую память на зоны в зависимости от их характеристик и предназначения. Зона DMA предназначена для устройств, которые могут обращаться только к первым 16 МБ памяти. Зона Normal охватывает память, напрямую отображаемую ядром, а зона HighMem используется для управления памятью, превышающей возможности прямого отображения.
Аллокатор страниц buddy system управляет распределением физической памяти блоками степеней двойки. Когда процессу требуется память, система ищет свободный блок подходящего размера. Если такого блока нет, более крупный блок разделяется пополам до получения нужного размера. При освобождении памяти соседние блоки объединяются обратно, предотвращая фрагментацию.
Slab-аллокатор работает поверх buddy system, оптимизируя выделение памяти для часто используемых объектов ядра. Он создает кэши для объектов определенных типов и размеров, снижая накладные расходы на управление памятью и улучшая локальность данных в кэше процессора.
Подсистема подкачки и управление нагрузкой
Когда физической памяти становится недостаточно, в действие вступает механизм подкачки. Ядро переносит редко используемые страницы на диск в специальную область — swap-пространство. Этот процесс происходит прозрачно для приложений, которые продолжают работать, не подозревая о перемещении своих данных.
Алгоритм выбора страниц для подкачки основан на принципе LRU (Least Recently Used) с различными оптимизациями. Ядро ведет статистику обращений к страницам, отмечая активные и неактивные страницы. Страницы с данными и исполняемым кодом обрабатываются по-разному: грязные страницы данных требуют записи на диск, в то время как чистые страницы кода можно просто удалить из памяти, поскольку их всегда можно перечитать из исходного файла.
Подсистема readahead предвосхищает потребности приложений, заранее загружая в память страницы, которые вероятно понадобятся в ближайшее время. Этот механизм особенно эффективен при последовательном чтении файлов, когда система может предсказать, какие данные потребуются следующими.
Оптимизация производительности и современные решения
Transparent Huge Pages (THP) автоматически использует страницы большого размера там, где это возможно и выгодно. Крупные страницы сокращают количество записей в TLB и таблицах страниц, улучшая производительность приложений с большими объемами данных. Однако THP может увеличить потребление памяти из-за внутренней фрагментации, поэтому система постоянно балансирует между производительностью и эффективностью использования ресурсов.
NUMA (Non-Uniform Memory Access) осложняет картину в многопроцессорных системах, где доступ к разным банкам памяти имеет различную задержку. Ядро Linux учитывает топологию NUMA при размещении процессов и выделении памяти, стремясь минимизировать обращения к удаленным узлам памяти.
Механизм copy-on-write позволяет нескольким процессам эффективно разделять память до тех пор, пока один из них не попытается модифицировать данные. Только тогда создается отдельная копия страницы. Этот подход кардинально снижает потребление памяти при запуске новых процессов через fork().
Безопасность и изоляция в виртуальном пространстве
Современные процессоры предоставляют различные уровни привилегий для защиты критических данных ядра от пользовательских программ. Пользовательские процессы работают в ring 3, в то время как ядро выполняется в привилегированном ring 0. Такое разделение гарантирует, что приложения не могут случайно или намеренно повредить системные структуры данных.
SMEP (Supervisor Mode Execution Prevention) и SMAP (Supervisor Mode Access Prevention) представляют дополнительные уровни защиты на аппаратном уровне. Эти технологии предотвращают выполнение пользовательского кода в режиме ядра и блокируют непреднамеренный доступ ядра к пользовательским данным.
KASLR (Kernel Address Space Layout Randomization) рандомизирует расположение ядра в памяти при каждой загрузке системы, усложняя эксплуатацию уязвимостей. Аналогично, ASLR для пользовательских программ случайным образом размещает сегменты кода, данных и стека, повышая общую безопасность системы.
Архитектура виртуальной памяти Linux продолжает эволюционировать, адаптируясь к новым требованиям безопасности, производительности и масштабируемости. Глубокое понимание этих механизмов открывает путь к созданию более эффективных приложений и оптимизации системной производительности. Виртуальная память остается одним из краеугольных камней современных операционных систем, обеспечивая стабильную и безопасную работу множества программ в едином адресном пространстве.